
|
Right this moment, we’re introducing Amazon Nova Multimodal Embeddings, a state-of-the-art multimodal embedding mannequin for agentic retrieval-augmented technology (RAG) and semantic search purposes, out there in Amazon Bedrock. It’s the first unified embedding mannequin that helps textual content, paperwork, photographs, video, and audio by way of a single mannequin to allow crossmodal retrieval with main accuracy.
Embedding fashions convert textual, visible, and audio inputs into numerical representations referred to as embeddings. These embeddings seize the that means of the enter in a means that AI techniques can examine, search, and analyze, powering use circumstances equivalent to semantic search and RAG.
Organizations are more and more in search of options to unlock insights from the rising quantity of unstructured knowledge that’s unfold throughout textual content, picture, doc, video, and audio content material. For instance, a corporation might need product photographs, brochures that include infographics and textual content, and user-uploaded video clips. Embedding fashions are in a position to unlock worth from unstructured knowledge, nevertheless conventional fashions are usually specialised to deal with one content material sort. This limitation drives prospects to both construct advanced crossmodal embedding options or limit themselves to make use of circumstances centered on a single content material sort. The issue additionally applies to mixed-modality content material sorts equivalent to paperwork with interleaved textual content and pictures or video with visible, audio, and textual parts the place present fashions battle to seize crossmodal relationships effectively.
Nova Multimodal Embeddings helps a unified semantic house for textual content, paperwork, photographs, video, and audio to be used circumstances equivalent to crossmodal search throughout mixed-modality content material, looking with a reference picture, and retrieving visible paperwork.
Evaluating Amazon Nova Multimodal Embeddings efficiency
We evaluated the mannequin on a broad vary of benchmarks, and it delivers main accuracy out-of-the-box as described within the following desk.
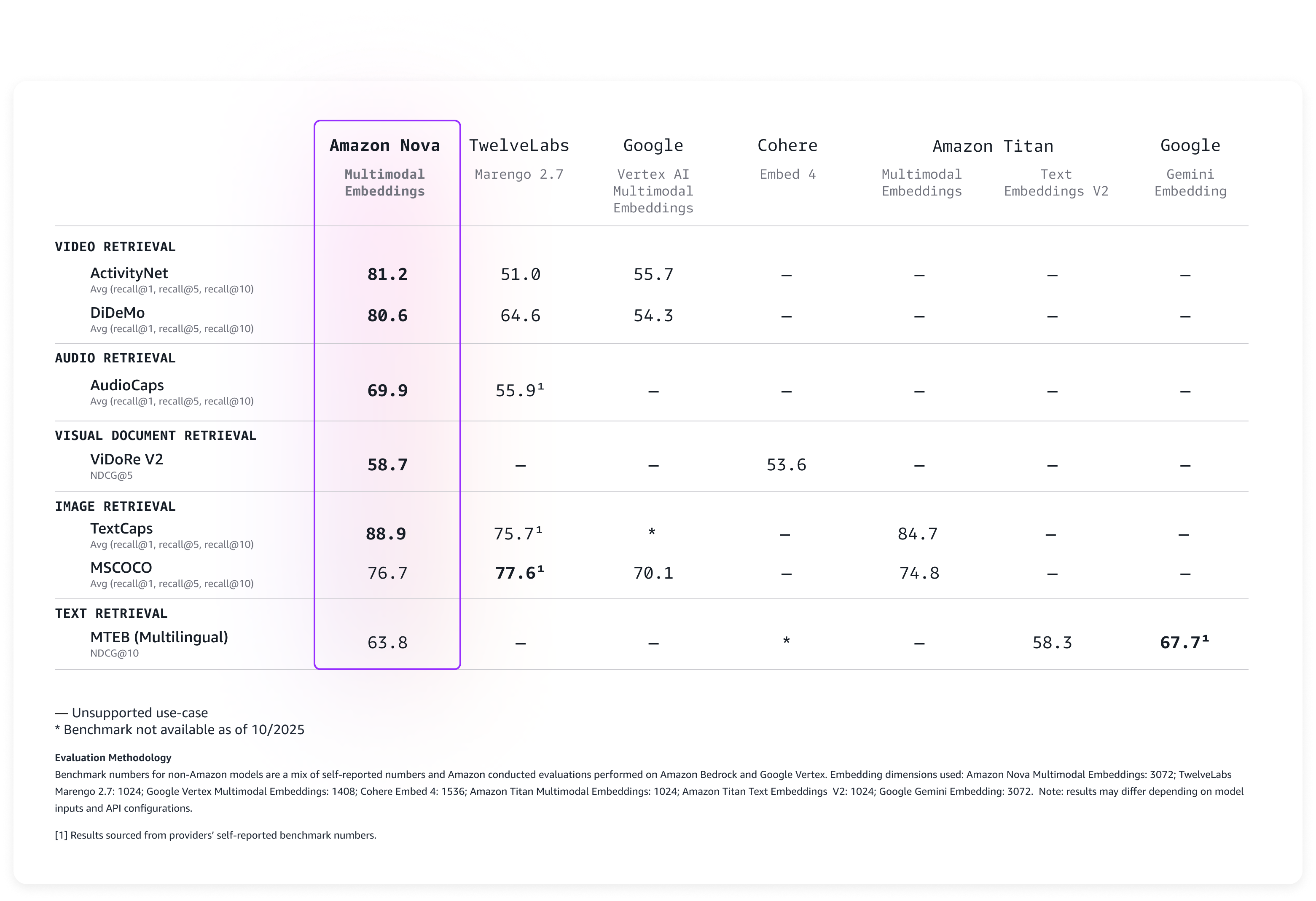
Nova Multimodal Embeddings helps a context size of as much as 8K tokens, textual content in as much as 200 languages, and accepts inputs by way of synchronous and asynchronous APIs. Moreover, it helps segmentation (also called “chunking”) to partition long-form textual content, video, or audio content material into manageable segments, producing embeddings for every portion. Lastly, the mannequin offers 4 output embedding dimensions, educated utilizing Matryoshka Illustration Studying (MRL) that permits low-latency end-to-end retrieval with minimal accuracy adjustments.
Let’s see how the brand new mannequin can be utilized in follow.
Utilizing Amazon Nova Multimodal Embeddings
Getting began with Nova Multimodal Embeddings follows the identical sample as different fashions in Amazon Bedrock. The mannequin accepts textual content, paperwork, photographs, video, or audio as enter and returns numerical embeddings that you need to use for semantic search, similarity comparability, or RAG.
Right here’s a sensible instance utilizing the AWS SDK for Python (Boto3) that reveals the best way to create embeddings from completely different content material sorts and retailer them for later retrieval. For simplicity, I’ll use Amazon S3 Vectors, a cost-optimized storage with native help for storing and querying vectors at any scale, to retailer and search the embeddings.
Let’s begin with the basics: changing textual content into embeddings. This instance reveals the best way to remodel a easy textual content description right into a numerical illustration that captures its semantic that means. These embeddings can later be in contrast with embeddings from paperwork, photographs, movies, or audio to search out associated content material.
To make the code simple to observe, I’ll present a piece of the script at a time. The complete script is included on the finish of this walkthrough.
import json
import base64
import time
import boto3
MODEL_ID = "amazon.nova-2-multimodal-embeddings-v1:0"
EMBEDDING_DIMENSION = 3072
# Initialize Amazon Bedrock Runtime consumer
bedrock_runtime = boto3.consumer("bedrock-runtime", region_name="us-east-1")
print(f"Producing textual content embedding with {MODEL_ID} ...")
# Textual content to embed
textual content = "Amazon Nova is a multimodal basis mannequin"
# Create embedding
request_body = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"textual content": {"truncationMode": "END", "worth": textual content},
},
}
response = bedrock_runtime.invoke_model(
physique=json.dumps(request_body),
modelId=MODEL_ID,
contentType="software/json",
)
# Extract embedding
response_body = json.masses(response["body"].learn())
embedding = response_body["embeddings"][0]["embedding"]
print(f"Generated embedding with {len(embedding)} dimensions")Now we’ll course of visible content material utilizing the identical embedding house utilizing a picture.jpg file in the identical folder because the script. This demonstrates the facility of multimodality: Nova Multimodal Embeddings is ready to seize each textual and visible context right into a single embedding that gives enhanced understanding of the doc.
Nova Multimodal Embeddings can generate embeddings which can be optimized for the way they’re getting used. When indexing for a search or retrieval use case, embeddingPurpose could be set to GENERIC_INDEX. For the question step, embeddingPurpose could be set relying on the kind of merchandise to be retrieved. For instance, when retrieving paperwork, embeddingPurpose could be set to DOCUMENT_RETRIEVAL.
# Learn and encode picture
print(f"Producing picture embedding with {MODEL_ID} ...")
with open("picture.jpg", "rb") as f:
image_bytes = base64.b64encode(f.learn()).decode("utf-8")
# Create embedding
request_body = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"picture": {
"format": "jpeg",
"supply": {"bytes": image_bytes}
},
},
}
response = bedrock_runtime.invoke_model(
physique=json.dumps(request_body),
modelId=MODEL_ID,
contentType="software/json",
)
# Extract embedding
response_body = json.masses(response["body"].learn())
embedding = response_body["embeddings"][0]["embedding"]
print(f"Generated embedding with {len(embedding)} dimensions")To course of video content material, I exploit the asynchronous API. That’s a requirement for movies which can be bigger than 25MB when encoded as Base64. First, I add an area video to an S3 bucket in the identical AWS Area.
aws s3 cp presentation.mp4 s3://my-video-bucket/movies/This instance reveals the best way to extract embeddings from each visible and audio parts of a video file. The segmentation characteristic breaks longer movies into manageable chunks, making it sensible to go looking by way of hours of content material effectively.
# Initialize Amazon S3 consumer
s3 = boto3.consumer("s3", region_name="us-east-1")
print(f"Producing video embedding with {MODEL_ID} ...")
# Amazon S3 URIs
S3_VIDEO_URI = "s3://my-video-bucket/movies/presentation.mp4"
S3_EMBEDDING_DESTINATION_URI = "s3://my-embedding-destination-bucket/embeddings-output/"
# Create async embedding job for video with audio
model_input = {
"taskType": "SEGMENTED_EMBEDDING",
"segmentedEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"video": {
"format": "mp4",
"embeddingMode": "AUDIO_VIDEO_COMBINED",
"supply": {
"s3Location": {"uri": S3_VIDEO_URI}
},
"segmentationConfig": {
"durationSeconds": 15 # Phase into 15-second chunks
},
},
},
}
response = bedrock_runtime.start_async_invoke(
modelId=MODEL_ID,
modelInput=model_input,
outputDataConfig={
"s3OutputDataConfig": {
"s3Uri": S3_EMBEDDING_DESTINATION_URI
}
},
)
invocation_arn = response["invocationArn"]
print(f"Async job began: {invocation_arn}")
# Ballot till job completes
print("nPolling for job completion...")
whereas True:
job = bedrock_runtime.get_async_invoke(invocationArn=invocation_arn)
standing = job["status"]
print(f"Standing: {standing}")
if standing != "InProgress":
break
time.sleep(15)
# Examine if job accomplished efficiently
if standing == "Accomplished":
output_s3_uri = job["outputDataConfig"]["s3OutputDataConfig"]["s3Uri"]
print(f"nSuccess! Embeddings at: {output_s3_uri}")
# Parse S3 URI to get bucket and prefix
s3_uri_parts = output_s3_uri[5:].break up("/", 1) # Take away "s3://" prefix
bucket = s3_uri_parts[0]
prefix = s3_uri_parts[1] if len(s3_uri_parts) > 1 else ""
# AUDIO_VIDEO_COMBINED mode outputs to embedding-audio-video.jsonl
# The output_s3_uri already consists of the job ID, so simply append the filename
embeddings_key = f"{prefix}/embedding-audio-video.jsonl".lstrip("/")
print(f"Studying embeddings from: s3://{bucket}/{embeddings_key}")
# Learn and parse JSONL file
response = s3.get_object(Bucket=bucket, Key=embeddings_key)
content material = response['Body'].learn().decode('utf-8')
embeddings = []
for line in content material.strip().break up('n'):
if line:
embeddings.append(json.masses(line))
print(f"nFound {len(embeddings)} video segments:")
for i, phase in enumerate(embeddings):
print(f" Phase {i}: {phase.get('startTime', 0):.1f}s - {phase.get('endTime', 0):.1f}s")
print(f" Embedding dimension: {len(phase.get('embedding', []))}")
else:
print(f"nJob failed: {job.get('failureMessage', 'Unknown error')}")With our embeddings generated, we’d like a spot to retailer and search them effectively. This instance demonstrates establishing a vector retailer utilizing Amazon S3 Vectors, which offers the infrastructure wanted for similarity search at scale. Consider this as making a searchable index the place semantically comparable content material naturally clusters collectively. When including an embedding to the index, I exploit the metadata to specify the unique format and the content material being listed.
# Initialize Amazon S3 Vectors consumer
s3vectors = boto3.consumer("s3vectors", region_name="us-east-1")
# Configuration
VECTOR_BUCKET = "my-vector-store"
INDEX_NAME = "embeddings"
# Create vector bucket and index (if they do not exist)
attempt:
s3vectors.get_vector_bucket(vectorBucketName=VECTOR_BUCKET)
print(f"Vector bucket {VECTOR_BUCKET} already exists")
besides s3vectors.exceptions.NotFoundException:
s3vectors.create_vector_bucket(vectorBucketName=VECTOR_BUCKET)
print(f"Created vector bucket: {VECTOR_BUCKET}")
attempt:
s3vectors.get_index(vectorBucketName=VECTOR_BUCKET, indexName=INDEX_NAME)
print(f"Vector index {INDEX_NAME} already exists")
besides s3vectors.exceptions.NotFoundException:
s3vectors.create_index(
vectorBucketName=VECTOR_BUCKET,
indexName=INDEX_NAME,
dimension=EMBEDDING_DIMENSION,
dataType="float32",
distanceMetric="cosine"
)
print(f"Created index: {INDEX_NAME}")
texts = [
"Machine learning on AWS",
"Amazon Bedrock provides foundation models",
"S3 Vectors enables semantic search"
]
print(f"nGenerating embeddings for {len(texts)} texts...")
# Generate embeddings utilizing Amazon Nova for every textual content
vectors = []
for textual content in texts:
response = bedrock_runtime.invoke_model(
physique=json.dumps({
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingDimension": EMBEDDING_DIMENSION,
"textual content": {"truncationMode": "END", "worth": textual content}
}
}),
modelId=MODEL_ID,
settle for="software/json",
contentType="software/json"
)
response_body = json.masses(response["body"].learn())
embedding = response_body["embeddings"][0]["embedding"]
vectors.append({
"key": f"textual content:{textual content[:50]}", # Distinctive identifier
"knowledge": {"float32": embedding},
"metadata": {"sort": "textual content", "content material": textual content}
})
print(f" ✓ Generated embedding for: {textual content}")
# Add all vectors to retailer in a single name
s3vectors.put_vectors(
vectorBucketName=VECTOR_BUCKET,
indexName=INDEX_NAME,
vectors=vectors
)
print(f"nSuccessfully added {len(vectors)} vectors to the shop in a single put_vectors name!")This closing instance demonstrates the potential of looking throughout completely different content material sorts with a single question, discovering essentially the most comparable content material no matter whether or not it originated from textual content, photographs, movies, or audio. The space scores make it easier to perceive how intently associated the outcomes are to your unique question.
# Textual content to question
query_text = "basis fashions"
print(f"nGenerating embeddings for question '{query_text}' ...")
# Generate embeddings
response = bedrock_runtime.invoke_model(
physique=json.dumps({
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_RETRIEVAL",
"embeddingDimension": EMBEDDING_DIMENSION,
"textual content": {"truncationMode": "END", "worth": query_text}
}
}),
modelId=MODEL_ID,
settle for="software/json",
contentType="software/json"
)
response_body = json.masses(response["body"].learn())
query_embedding = response_body["embeddings"][0]["embedding"]
print(f"Trying to find comparable embeddings...n")
# Seek for high 5 most comparable vectors
response = s3vectors.query_vectors(
vectorBucketName=VECTOR_BUCKET,
indexName=INDEX_NAME,
queryVector={"float32": query_embedding},
topK=5,
returnDistance=True,
returnMetadata=True
)
# Show outcomes
print(f"Discovered {len(response['vectors'])} outcomes:n")
for i, lead to enumerate(response["vectors"], 1):
print(f"{i}. {outcome['key']}")
print(f" Distance: {outcome['distance']:.4f}")
if outcome.get("metadata"):
print(f" Metadata: {outcome['metadata']}")
print()Crossmodal search is likely one of the key benefits of multimodal embeddings. With crossmodal search, you possibly can question with textual content and discover related photographs. You may as well seek for movies utilizing textual content descriptions, discover audio clips that match sure subjects, or uncover paperwork primarily based on their visible and textual content material. In your reference, the complete script with all earlier examples merged collectively is right here:
import json
import base64
import time
import boto3
MODEL_ID = "amazon.nova-2-multimodal-embeddings-v1:0"
EMBEDDING_DIMENSION = 3072
# Initialize Amazon Bedrock Runtime consumer
bedrock_runtime = boto3.consumer("bedrock-runtime", region_name="us-east-1")
print(f"Producing textual content embedding with {MODEL_ID} ...")
# Textual content to embed
textual content = "Amazon Nova is a multimodal basis mannequin"
# Create embedding
request_body = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"textual content": {"truncationMode": "END", "worth": textual content},
},
}
response = bedrock_runtime.invoke_model(
physique=json.dumps(request_body),
modelId=MODEL_ID,
contentType="software/json",
)
# Extract embedding
response_body = json.masses(response["body"].learn())
embedding = response_body["embeddings"][0]["embedding"]
print(f"Generated embedding with {len(embedding)} dimensions")
# Learn and encode picture
print(f"Producing picture embedding with {MODEL_ID} ...")
with open("picture.jpg", "rb") as f:
image_bytes = base64.b64encode(f.learn()).decode("utf-8")
# Create embedding
request_body = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"picture": {
"format": "jpeg",
"supply": {"bytes": image_bytes}
},
},
}
response = bedrock_runtime.invoke_model(
physique=json.dumps(request_body),
modelId=MODEL_ID,
contentType="software/json",
)
# Extract embedding
response_body = json.masses(response["body"].learn())
embedding = response_body["embeddings"][0]["embedding"]
print(f"Generated embedding with {len(embedding)} dimensions")
# Initialize Amazon S3 consumer
s3 = boto3.consumer("s3", region_name="us-east-1")
print(f"Producing video embedding with {MODEL_ID} ...")
# Amazon S3 URIs
S3_VIDEO_URI = "s3://my-video-bucket/movies/presentation.mp4"
# Amazon S3 output bucket and placement
S3_EMBEDDING_DESTINATION_URI = "s3://my-video-bucket/embeddings-output/"
# Create async embedding job for video with audio
model_input = {
"taskType": "SEGMENTED_EMBEDDING",
"segmentedEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"video": {
"format": "mp4",
"embeddingMode": "AUDIO_VIDEO_COMBINED",
"supply": {
"s3Location": {"uri": S3_VIDEO_URI}
},
"segmentationConfig": {
"durationSeconds": 15 # Phase into 15-second chunks
},
},
},
}
response = bedrock_runtime.start_async_invoke(
modelId=MODEL_ID,
modelInput=model_input,
outputDataConfig={
"s3OutputDataConfig": {
"s3Uri": S3_EMBEDDING_DESTINATION_URI
}
},
)
invocation_arn = response["invocationArn"]
print(f"Async job began: {invocation_arn}")
# Ballot till job completes
print("nPolling for job completion...")
whereas True:
job = bedrock_runtime.get_async_invoke(invocationArn=invocation_arn)
standing = job["status"]
print(f"Standing: {standing}")
if standing != "InProgress":
break
time.sleep(15)
# Examine if job accomplished efficiently
if standing == "Accomplished":
output_s3_uri = job["outputDataConfig"]["s3OutputDataConfig"]["s3Uri"]
print(f"nSuccess! Embeddings at: {output_s3_uri}")
# Parse S3 URI to get bucket and prefix
s3_uri_parts = output_s3_uri[5:].break up("/", 1) # Take away "s3://" prefix
bucket = s3_uri_parts[0]
prefix = s3_uri_parts[1] if len(s3_uri_parts) > 1 else ""
# AUDIO_VIDEO_COMBINED mode outputs to embedding-audio-video.jsonl
# The output_s3_uri already consists of the job ID, so simply append the filename
embeddings_key = f"{prefix}/embedding-audio-video.jsonl".lstrip("/")
print(f"Studying embeddings from: s3://{bucket}/{embeddings_key}")
# Learn and parse JSONL file
response = s3.get_object(Bucket=bucket, Key=embeddings_key)
content material = response['Body'].learn().decode('utf-8')
embeddings = []
for line in content material.strip().break up('n'):
if line:
embeddings.append(json.masses(line))
print(f"nFound {len(embeddings)} video segments:")
for i, phase in enumerate(embeddings):
print(f" Phase {i}: {phase.get('startTime', 0):.1f}s - {phase.get('endTime', 0):.1f}s")
print(f" Embedding dimension: {len(phase.get('embedding', []))}")
else:
print(f"nJob failed: {job.get('failureMessage', 'Unknown error')}")
# Initialize Amazon S3 Vectors consumer
s3vectors = boto3.consumer("s3vectors", region_name="us-east-1")
# Configuration
VECTOR_BUCKET = "my-vector-store"
INDEX_NAME = "embeddings"
# Create vector bucket and index (if they do not exist)
attempt:
s3vectors.get_vector_bucket(vectorBucketName=VECTOR_BUCKET)
print(f"Vector bucket {VECTOR_BUCKET} already exists")
besides s3vectors.exceptions.NotFoundException:
s3vectors.create_vector_bucket(vectorBucketName=VECTOR_BUCKET)
print(f"Created vector bucket: {VECTOR_BUCKET}")
attempt:
s3vectors.get_index(vectorBucketName=VECTOR_BUCKET, indexName=INDEX_NAME)
print(f"Vector index {INDEX_NAME} already exists")
besides s3vectors.exceptions.NotFoundException:
s3vectors.create_index(
vectorBucketName=VECTOR_BUCKET,
indexName=INDEX_NAME,
dimension=EMBEDDING_DIMENSION,
dataType="float32",
distanceMetric="cosine"
)
print(f"Created index: {INDEX_NAME}")
texts = [
"Machine learning on AWS",
"Amazon Bedrock provides foundation models",
"S3 Vectors enables semantic search"
]
print(f"nGenerating embeddings for {len(texts)} texts...")
# Generate embeddings utilizing Amazon Nova for every textual content
vectors = []
for textual content in texts:
response = bedrock_runtime.invoke_model(
physique=json.dumps({
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"textual content": {"truncationMode": "END", "worth": textual content}
}
}),
modelId=MODEL_ID,
settle for="software/json",
contentType="software/json"
)
response_body = json.masses(response["body"].learn())
embedding = response_body["embeddings"][0]["embedding"]
vectors.append({
"key": f"textual content:{textual content[:50]}", # Distinctive identifier
"knowledge": {"float32": embedding},
"metadata": {"sort": "textual content", "content material": textual content}
})
print(f" ✓ Generated embedding for: {textual content}")
# Add all vectors to retailer in a single name
s3vectors.put_vectors(
vectorBucketName=VECTOR_BUCKET,
indexName=INDEX_NAME,
vectors=vectors
)
print(f"nSuccessfully added {len(vectors)} vectors to the shop in a single put_vectors name!")
# Textual content to question
query_text = "basis fashions"
print(f"nGenerating embeddings for question '{query_text}' ...")
# Generate embeddings
response = bedrock_runtime.invoke_model(
physique=json.dumps({
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_RETRIEVAL",
"embeddingDimension": EMBEDDING_DIMENSION,
"textual content": {"truncationMode": "END", "worth": query_text}
}
}),
modelId=MODEL_ID,
settle for="software/json",
contentType="software/json"
)
response_body = json.masses(response["body"].learn())
query_embedding = response_body["embeddings"][0]["embedding"]
print(f"Trying to find comparable embeddings...n")
# Seek for high 5 most comparable vectors
response = s3vectors.query_vectors(
vectorBucketName=VECTOR_BUCKET,
indexName=INDEX_NAME,
queryVector={"float32": query_embedding},
topK=5,
returnDistance=True,
returnMetadata=True
)
# Show outcomes
print(f"Discovered {len(response['vectors'])} outcomes:n")
for i, lead to enumerate(response["vectors"], 1):
print(f"{i}. {outcome['key']}")
print(f" Distance: {outcome['distance']:.4f}")
if outcome.get("metadata"):
print(f" Metadata: {outcome['metadata']}")
print()For manufacturing purposes, embeddings could be saved in any vector database. Amazon OpenSearch Service presents native integration with Nova Multimodal Embeddings at launch, making it simple to construct scalable search purposes. As proven within the examples earlier than, Amazon S3 Vectors offers a easy method to retailer and question embeddings along with your software knowledge.
Issues to know
Nova Multimodal Embeddings presents 4 output dimension choices: 3,072, 1,024, 384, and 256. Bigger dimensions present extra detailed representations however require extra storage and computation. Smaller dimensions provide a sensible stability between retrieval efficiency and useful resource effectivity. This flexibility helps you optimize on your particular software and value necessities.
The mannequin handles substantial context lengths. For textual content inputs, it might course of as much as 8,192 tokens without delay. Video and audio inputs help segments of as much as 30 seconds, and the mannequin can phase longer information. This segmentation functionality is especially helpful when working with massive media information—the mannequin splits them into manageable items and creates embeddings for every phase.
The mannequin consists of accountable AI options constructed into Amazon Bedrock. Content material submitted for embedding goes by way of Amazon Bedrock content material security filters, and the mannequin consists of equity measures to cut back bias.
As described within the code examples, the mannequin could be invoked by way of each synchronous and asynchronous APIs. The synchronous API works nicely for real-time purposes the place you want instant responses, equivalent to processing consumer queries in a search interface. The asynchronous API handles latency insensitive workloads extra effectively, making it appropriate for processing massive content material equivalent to movies.
Availability and pricing
Amazon Nova Multimodal Embeddings is accessible immediately in Amazon Bedrock within the US East (N. Virginia) AWS Area. For detailed pricing info, go to the Amazon Bedrock pricing web page.
To be taught extra, see the Amazon Nova Person Information for complete documentation and the Amazon Nova mannequin cookbook on GitHub for sensible code examples.
In case you’re utilizing an AI–powered assistant for software program improvement equivalent to Amazon Q Developer or Kiro, you possibly can arrange the AWS API MCP Server to assist the AI assistants work together with AWS companies and assets and the AWS Data MCP Server to offer up-to-date documentation, code samples, data concerning the regional availability of AWS APIs and CloudFormation assets.
Begin constructing multimodal AI-powered purposes with Nova Multimodal Embeddings immediately, and share your suggestions by way of AWS re:Submit for Amazon Bedrock or your typical AWS Help contacts.
— Danilo