It is a visitor submit by Umesh Dangat, Senior Principal Engineer for Distributed Companies and Programs at Yelp, and Toby Cole, Precept Engineer for Information Processing at Yelp, in partnership with AWS.
Yelp processes huge quantities of consumer information every day—over 300 million enterprise opinions, 100,000 picture uploads, and numerous check-ins. Sustaining sub-minute information freshness with this quantity introduced a major problem for our Information Processing staff. Our homegrown information pipeline, inbuilt 2015 utilizing then-modern streaming applied sciences, scaled successfully for a few years. As our enterprise and information wants advanced, we started to come across new challenges in managing observability and governance throughout an more and more advanced information ecosystem, prompting the necessity for a extra trendy strategy. This affected our outage incidents, making it more durable to each assess influence and restore service. On the identical time, our streaming framework struggled with Kafka for information streaming and everlasting information storage. As well as, our connectors to analytical information shops skilled latencies exceeding 18 hours.
This got here to a head when our efforts to adjust to Common Information Safety Regulation (GDPR) necessities revealed gaps in our infrastructure that will require us to wash up our information, whereas concurrently sustaining operational reliability and lowering information processing occasions. One thing needed to change.
On this submit, we share how we modernized our information infrastructure by embracing a streaming lakehouse structure, reaching real-time processing capabilities at a fraction of the fee whereas lowering operational complexity. With this modernization effort, we lowered analytics information latencies from 18 hours to mere minutes, whereas additionally eradicating the necessity for utilizing Kafka as a everlasting storage for our change log streams.
The issue: Why we wanted change
We began this transformation by initiating a migration from self-managed Apache Kafka to Amazon Managed Streaming for Apache Kafka (Amazon MSK), which considerably lowered our operational overhead and enhanced safety. Amazon MSK’s specific brokers additionally supplied higher elasticity for our Apache Kafka clusters. Whereas these enhancements have been a promising begin, we acknowledged the necessity for a extra elementary architectural change
Legacy structure ache factors
Let’s study the particular challenges and limitations of our earlier structure that prompted us to hunt a contemporary resolution.
The next diagram depicts Yelp’s authentic information structure.
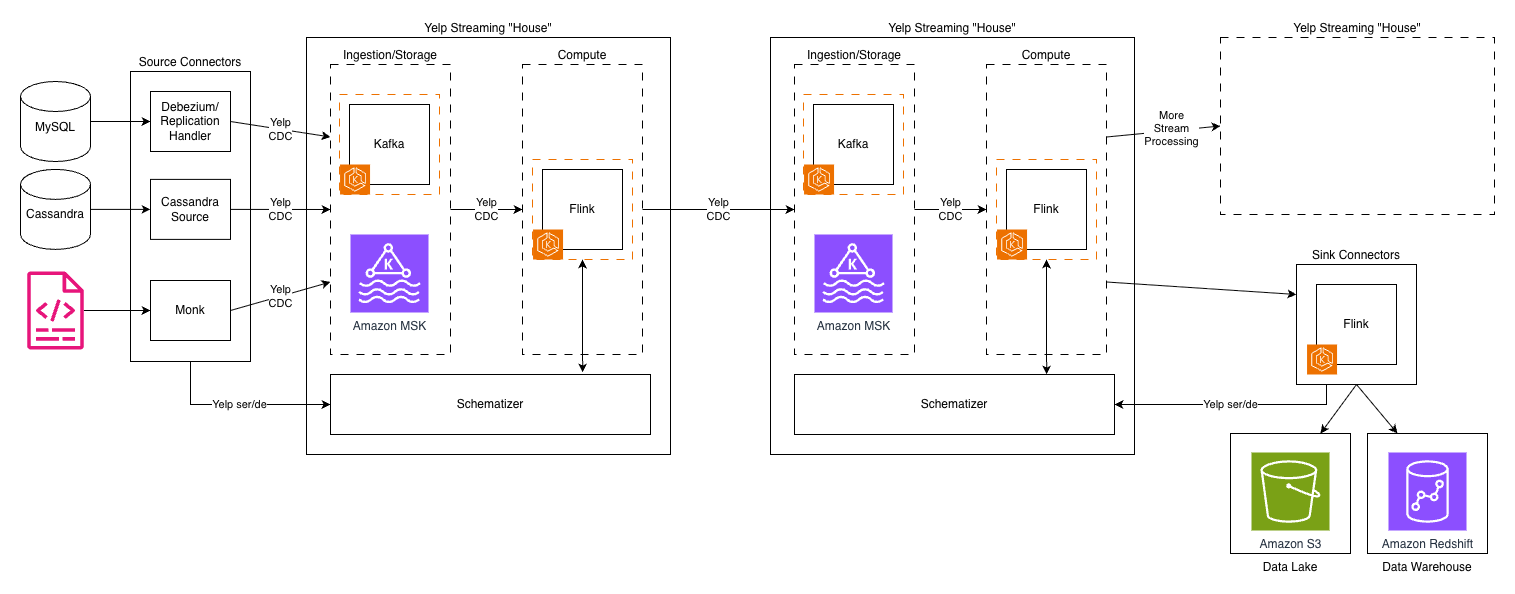
Kafka subjects proliferated throughout our infrastructure, creating lengthy processing chains. Consequently, every hop added latency, operational overhead, and storage prices. The system’s reliance on Kafka for each ingestion and storage created a elementary bottleneck—Kafka’s structure, optimized for high-throughput messaging, wasn’t designed for long-term storage and to deal with advanced querying patterns.
One other problem was our customized “Yelp CDC” format—a proprietary change information seize language—was highly effective and tailor-made to our wants. Nevertheless, as our staff grew and our use instances expanded, it launched complexity and a steeper studying curve for brand spanking new engineers. It additionally made integrations with off-the-shelf programs extra advanced and upkeep intensive.
The fee and latency trade-off
The normal trade-off between real-time processing and value effectivity had us caught in an costly bind. Actual-time streaming programs demand vital assets to keep up state inside compute engines like Apache Flink, maintain a number of copies of information throughout Kafka clusters, and run always-on processing jobs. Our infrastructure prices have been rising, and it was largely pushed by:
- Lengthy Kafka chains: Information usually traversed 4-5 Kafka subjects earlier than reaching its vacation spot and every matter was replicated for reliability
- Duplicate information storage: The identical information existed in a number of codecs throughout totally different programs—uncooked in Kafka, processed in intermediate subjects, and closing kinds in information warehouses and Flink RocksDB for join-like use instances
- Complicated customized tooling upkeep: The proprietary nature of our instruments meant engineering assets have been targeted on upkeep relatively than constructing new capabilities
In the meantime, our enterprise necessities grew to become extra demanding. Groups at Yelp wanted quicker insights, near-real-time outcomes, and the flexibility to shortly run advanced historic analyses at once. This pushed us to form our new structure to enhance streaming discovery and metadata visibility, present extra versatile transformation tooling, and simplify operational workflows with quicker restoration occasions.
Understanding the streamhouse idea
To know how we solved our information infrastructure challenges, it’s essential to first grasp the idea of a streamhouse and the way it differs from conventional architectures.
Evolution of information structure
To know why a streaming lakehouse or streamhouse was the reply to our challenges, it’s useful to hint the evolution of information architectures. The journey from information warehouses to trendy streaming programs reveals why every technology solved sure issues whereas creating new ones.
Information warehouses like Amazon Redshift and Snowflake introduced construction and reliability to analytics, however their batch-oriented nature meant accepting hours or days of latency. Information lakes emerged to deal with the quantity and number of large information, utilizing low-cost object storage like Amazon S3, however usually grew to become “information swamps” with out correct governance. The lakehouse structure, pioneered by applied sciences like Apache Iceberg and Delta Lake, promised to mix the most effective of each, the construction of warehouses with the pliability and economics of lakes.
However even lakehouses have been designed with batch processing in thoughts. Whereas they added streaming capabilities, these have been usually bolted on relatively than elementary to the structure. What we wanted was one thing totally different: a reimagining that handled streaming as a first-class citizen whereas sustaining lakehouse economics.
What makes a streamhouse totally different
A streamhouse, as we outline it, is “a stream processing framework with a storage layer that leverages a desk format, making intermediate streaming information immediately queryable.” This seemingly easy definition represents a elementary shift in how we take into consideration information processing.
Conventional streaming programs keep dynamic tables like materialized views in databases, however these aren’t immediately queryable. You possibly can solely devour them as streams, limiting their utility for ad-hoc evaluation or debugging. Lakehouses, conversely, excel at queries however wrestle with low-latency updates and sophisticated streaming operations like out-of-order occasion dealing with or partial updates.
The streamhouse bridges this hole by:
- Treating batch as a particular case of streaming, relatively than a separate paradigm
- Making information, together with intermediate processing outcomes, queryable through SQL
- Offering streaming-native options like database change-data seize (CDC) and temporal joins
- Leveraging cost-effective object storage whereas sustaining minute-level latencies
Core capabilities we wanted
Our necessities for a streaming lakehouse have been formed by years of working at scale:
Actual-time processing with minute-level latency: Whereas sub-second latency wasn’t essential for many use instances, our earlier hours-long delays weren’t acceptable. The candy spot was processing latencies measured in minutes quick sufficient for real-time decision-making however relaxed sufficient to leverage cost-effective storage.
Environment friendly CDC dealing with: With quite a few MySQL databases powering our purposes, the flexibility to effectively seize and course of database modifications was essential. The answer wanted to deal with each preliminary snapshots and ongoing modifications seamlessly, with out guide intervention or downtime.
Value-effective scaling: The structure needed to break the linear relationship between information quantity and value. This meant leveraging tiered storage, with scorching information on quick storage and chilly information on low-cost object storage, all whereas sustaining question efficiency.
Constructed-in information administration: Schema evolution, information lineage, time journey queries, and information qc wanted to be first-class options, not afterthoughts. Our expertise sustaining our customized Schematizer taught us that these capabilities have been important for working at scale.
The answer structure
Our modernized information infrastructure combines a number of key applied sciences right into a cohesive streamhouse structure that addresses our core necessities whereas sustaining operational effectivity.
Our know-how stack choice
We fastidiously chosen and built-in a number of confirmed applied sciences to construct our streamhouse resolution.The next diagram depicts Yelp’s new information structure.
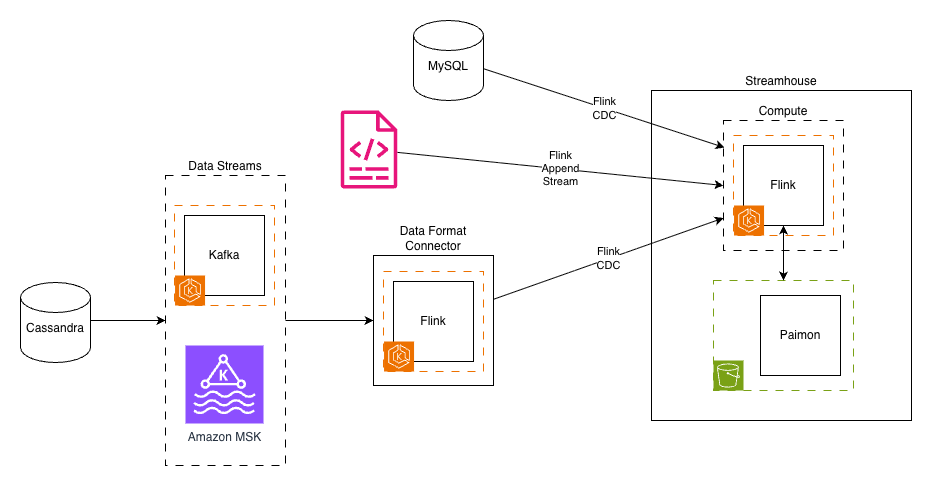
After intensive analysis, we assembled a contemporary streaming lakehouse stack, streamhouse, constructed on confirmed open supply applied sciences:
Amazon MSK continues to ship current streams as they did earlier than from supply purposes and companies.
Apache Flink on Amazon EKS served as our compute engine, a pure selection given our current experience and funding in Flink-based processing. Its highly effective stream processing capabilities, exactly-once semantics, and mature framework made it supreme for the computational layer.
Apache Paimon emerged as the important thing innovation, offering the streaming lakehouse storage layer. Born from the Flink neighborhood’s FLIP-188 proposal for built-in dynamic desk storage, Paimon was designed from the bottom up for streaming workloads. Its LSM-tree-based structure supplied the high-speed ingestion capabilities we wanted.
Amazon S3 serves as our streamhouse storage layer, providing extremely scalable capability at a fraction of the fee. The shift from compute-coupled storage (Kafka brokers) to object storage represented a elementary architectural change that unlocked huge value financial savings.
Flink CDC connectors changed our customized CDC implementations, offering battle-tested integrations with databases like MySQL. These connectors dealt with the complexity of preliminary snapshots, incremental updates, and schema modifications robotically.
Architectural transformation
The transformation from our legacy structure to the streamhouse mannequin concerned three key architectural shifts:
1. Decoupling ingestion from storage
In our outdated world, Kafka dealt with each information ingestion and storage, creating an costly coupling. Each byte ingested needed to be saved on Kafka brokers with replication for reliability. Our new structure separated these issues: Flink CDC dealt with ingestion by instantly writing to Paimon tables backed by S3. This separation lowered our storage prices by over 80% and improved reliability via the 11 nines of sturdiness of S3.
2. Unified information format
The migration from our proprietary CDC format to the industry-standard Debezium format was greater than a technical change. It mirrored a broader transfer towards community-supported requirements. We constructed a Information Format Converter that bridged the hole, permitting legacy streams to proceed functioning whereas new streams leveraged commonplace codecs. This strategy facilitated backward compatibility whereas paving the best way for future simplification.
3. Streamhouse tables
Maybe probably the most radical change was changing a few of our Kafka subjects with Paimon tables. These weren’t simply storage places—they have been dynamic, versioned, queryable entities that supported:
- Time journey queries within the desk’s snapshot retention interval
- Computerized schema evolution with out downtime
- SQL-based entry for each streaming and batch workloads
- Constructed-in compaction and optimization
Key design selections
A number of key design selections formed our implementation:
SQL as the first interface: Relatively than requiring builders to write down Java or Scala code for each transformation, SQL grew to become our lingua franca. This democratized entry to streaming information, permitting analysts and information scientists to work with real-time information utilizing acquainted instruments.
Separation of compute and storage: By decoupling these layers, we may scale them independently. A spike in processing wants not meant provisioning extra storage, and historic information may very well be stored indefinitely with out impacting compute prices.
Embracing open supply requirements: The shift from home-grown codecs and instruments to community-supported initiatives lowered our upkeep burden and accelerated function growth. When points arose, our engineers may leverage neighborhood information relatively than debugging in isolation.
Implementation journey
Our transition to the brand new streamhouse structure adopted a fastidiously deliberate path, encompassing prototype growth, phased migration, and systematic validation of every part.
Migration technique
Our migration to the streamhouse structure required cautious planning and execution. The technique needed to steadiness the necessity for transformation with the truth of sustaining essential manufacturing programs.
1. Prototype growth
Our journey started with constructing foundational parts:
- Pure Java consumer library: Eradicating Scala dependencies have been essential for broader adoption. Our new library eliminated reliance on Yelp-specific configurations, permitting it to run in lots of environments.
- Information Format Converter: This bridge part translated between our proprietary CDC format and the usual Debezium format, ensuring current shoppers may proceed working in the course of the migration.
- Paimon ingestor: A Flink job that would ingest information from Kafka sources into Paimon tables, dealing with schema evolution robotically.
2. Phased rollout strategy
Relatively than making an attempt a “large bang” migration, we adopted a per-use case strategy—shifting a vertical slice of information relatively than your complete system without delay. Our phased rollout adopted these steps:
- Choose a consultant, real-world use case that gives broad protection of the present function set.
- Re-implement the use case on the brand new stack in a growth surroundings utilizing pattern information to check the logic
- Shadow-launch the brand new stack in manufacturing to check it at scale
- This was a essential step for us, as we needed to iterate via numerous configuration tweaks earlier than the system may reliably maintain our manufacturing visitors.
- Confirm the brand new manufacturing deployment in opposition to the legacy system’s output
- Swap dwell visitors to the brand new system solely after each the Yelp Platform staff and information homeowners are assured in its efficiency and reliability
- Decommission the legacy system for that use case as soon as the migration is full
This phased strategy allowed our staff to construct confidence, establish points early, and refine our processes earlier than touching business-critical programs in manufacturing.
Technical challenges we overcame
The migration surfaced a number of technical challenges that required progressive options:
System integration: We developed complete monitoring to trace end-to-end latencies and constructed automated alerting to detect any degradation in efficiency.
Efficiency tuning: Preliminary write efficiency to Paimon tables was suboptimal for our higher-throughput streams. After cautious evaluation, we recognized that Paimon was re-reading manifest recordsdata from S3 on each commit. To alleviate this, we enabled Paimon’s sink author coordinator cache setting, which is disabled by default. This massively lowered the variety of S3 calls throughout commits. We additionally discovered that writing parallelism in Paimon is restricted by the variety of “buckets” inside a partition. Choosing the fitting variety of buckets to let you scale horizontally, but in addition not unfold your information too thinly is essential for balancing write efficiency in opposition to question efficiency.
Information validation: Validating information consistency between our legacy Yelp CDC streams and the brand new Debezium-based format introduced notable challenges. In the course of the parallel run part, we carried out complete validation frameworks to verify the Information Format Convertor precisely remodeled messages, whereas sustaining information integrity, ordering ensures, and schema compatibility throughout each programs.
Information migration complexity: For consistency, we developed customized tooling to confirm ordering ensures and carried out parallel working of outdated and new programs. We selected Spark because the framework to implement our validations as each information supply and sink in our framework has mature connectors, and Spark is a well-supported system at Yelp.
Sensible wins we achieved
Our implementation delivered transformative outcomes:
Simplified streaming stack: By changing a number of customized parts with standardized instruments, we averted years of technical debt in a single migration. We lowered our complexity and thereby simplified our complete streaming structure, resulting in greater reliability and fewer upkeep overhead. Our Schematizer, encryption layer, and customized CDC format have been all changed by built-in options from Paimon and commonplace Kafka, together with IAM controls throughout S3 and MSK.
Wonderful-grained entry administration: Transferring our analytical use instances learn through Iceberg unlocked an enormous win for us: the flexibility to allow AWS Lake Formation on our information lake. Beforehand, our entry administration relied on giant, advanced S3 bucket coverage paperwork that have been approaching their measurement limits. By shifting to Lake Formation we may construct an entry request lifecycle into our in-house Entry Hub to automate entry granting and revocation.
Constructed-in information administration options: Capabilities that will have required months of customized growth got here out-of-the-box, resembling automated schema evolution, time journey queries, and incremental snapshots for environment friendly processing.
Potential for lowered operational prices: We anticipate that transitioning from Kafka storage to S3 in a streamhouse structure will considerably cut back storage prices. Avoiding lengthy Kafka chains will even simplify information pipelines and cut back compute prices.
Enhanced troubleshooting capabilities: The streamhouse structure guarantees built-in observability options that can make debugging simpler. Relatively than having to manually look via occasion streams for problematic information, which may be time-consuming and sophisticated for multi-stream pipelines, engineers can now question dwell information immediately from tables utilizing commonplace SQL.
Classes discovered and finest practices
All through this transformation, we gained invaluable insights about each technical implementation and organizational change administration that may profit others enterprise comparable modernization efforts.
Technical insights
Our journey revealed a number of essential technical classes:
Battle-tested open supply wins: Selecting Apache Paimon and Flink CDC over customized options proved sensible. The neighborhood help, steady enhancements, and shared information base accelerated our growth and lowered danger.
SQL interfaces democratize entry: Making streaming information accessible through SQL remodeled who may work with real-time information. Engineers and analysts acquainted with SQL can now perceive how streaming pipelines work. The barrier to entry has been considerably lowered as engineers not want to know Flink-specific APIs to create a streaming software.
Separation of storage and compute is prime: This architectural precept unlocked value financial savings and operational flexibility that wouldn’t have been potential in any other case. Our groups can now optimize storage and compute independently based mostly on their particular wants.
Organizational learnings
The human aspect of the transformation was equally essential:
Phased migration reduces danger: Our gradual strategy allowed groups to construct confidence and experience, whereas sustaining enterprise continuity. Every profitable part created momentum for the following. Constructing belief with newer programs helps acquire velocity in later levels of migrations.
Backward compatibility permits progress: By sustaining compatibility layers, our groups may migrate at their very own tempo with out forcing synchronized modifications throughout the group.
Funding in studying pays dividends: Giving our groups house to study new applied sciences like Paimon and streaming SQL had some alternative value, however they paid off via elevated productiveness and lowered operational burden.
Conclusion
Our transformation to a streaming lakehouse structure (streamhouse) has revolutionized Yelp’s information infrastructure, delivering spectacular outcomes throughout a number of dimensions. By implementing Apache Paimon with AWS companies like Amazon S3 and Amazon MSK, we lowered our analytics information latencies from 18 hours to simply minutes whereas chopping storage prices by 80%. The migration additionally simplified our structure by changing a number of customized parts with standardized instruments, considerably lowering upkeep overhead and enhancing reliability.
Key achievements embrace the profitable implementation of real-time processing capabilities, streamlined CDC dealing with, and enhanced information administration options like automated schema evolution and time journey queries. The shift to SQL-based interfaces has democratized entry to streaming information, whereas the separation of compute and storage has given us unprecedented flexibility in useful resource optimization. These enhancements have remodeled not simply our know-how stack, but in addition how our groups work with information.
For organizations going through comparable challenges with information processing latency, operational prices, and infrastructure complexity, we encourage you to discover the streamhouse strategy. Begin by evaluating your present structure in opposition to trendy streaming options, significantly these leveraging cloud companies and open-source applied sciences like Apache Paimon. Ensure to leverage safety finest practices when implementing your resolution. You’ll find AWS safety finest practices right here. Go to the Apache Paimon web site or AWS documentation to study extra about implementing these options in your surroundings.
Concerning the authors