Apache Spark Join, launched in Spark 3.4, enhances the Spark ecosystem by providing a client-server structure that separates the Spark runtime from the shopper software. Spark Join allows extra versatile and environment friendly interactions with Spark clusters, significantly in eventualities the place direct entry to cluster assets is proscribed or impractical.
A key use case for Spark Join on Amazon EMR is to have the ability to join immediately out of your native growth environments to Amazon EMR clusters. By utilizing this decoupled strategy, you possibly can write and check Spark code in your laptop computer whereas utilizing Amazon EMR clusters for execution. This functionality reduces growth time and simplifies information processing with Spark on Amazon EMR.
On this submit, we exhibit find out how to implement Apache Spark Join on Amazon EMR on Amazon Elastic Compute Cloud (Amazon EC2) to construct decoupled information processing purposes. We present find out how to arrange and configure Spark Join securely, so you possibly can develop and check Spark purposes regionally whereas executing them on distant Amazon EMR clusters.
Answer structure
The structure facilities on an Amazon EMR cluster with two node sorts. The main node hosts each the Spark Join API endpoint and Spark Core parts, serving because the gateway for shopper connections. The core node offers extra compute capability for distributed processing. Though this answer demonstrates the structure with two nodes for simplicity, it scales to help a number of core and job nodes based mostly on workload necessities.
In Apache Spark Join model 4.x, TLS/SSL community encryption isn’t inherently supported. We present you find out how to implement safe communications by deploying an Amazon EMR cluster with Spark Join on Amazon EC2 utilizing an Utility Load Balancer (ALB) with TLS termination because the safe interface. This strategy allows encrypted information transmission between Spark Join purchasers and Amazon Digital Personal Cloud (Amazon VPC) assets.
The operational move is as follows:
- Bootstrap script – Throughout Amazon EMR initialization, the first node fetches and executes the
start-spark-connect.shfile from Amazon Easy Storage Service (Amazon S3). This script begins the Spark Join server. - Server availability – When the bootstrap course of is full, the Spark Server enters a ready state, prepared to just accept incoming connections. The Spark Join API endpoint turns into out there on the configured port (usually 15002), listening for gRPC connection from distant purchasers.
- Shopper interplay – Spark Join purchasers can set up safe connections to an Utility Load Balancer. These purchasers translate DataFrame operations into unresolved logical question plans, encode these plans utilizing protocol buffers, and ship them to the Spark Join API utilizing gRPC.
- Encryption in transit – The Utility Load Balancer receives incoming gRPC or HTTPS site visitors, performs TLS termination (decrypting the site visitors), and forwards the requests to the first node. The certificates is saved in AWS Certificates Supervisor (ACM).
- Request processing – The Spark Join API receives the unresolved logical plans, interprets them into Spark’s built-in logical plan operators, passes them to Spark Core for optimization and execution, and streams outcomes again to the shopper as Apache Arrow-encoded row batches.
- (Elective) Operational entry – Directors can securely hook up with each main and core nodes by means of Session Supervisor, a functionality of AWS Methods Supervisor, enabling troubleshooting and upkeep with out exposing SSH ports or managing key pairs.
The next diagram depicts the structure of this submit’s demonstration for submitting Spark unresolved logical plans to EMR clusters utilizing Spark Join.
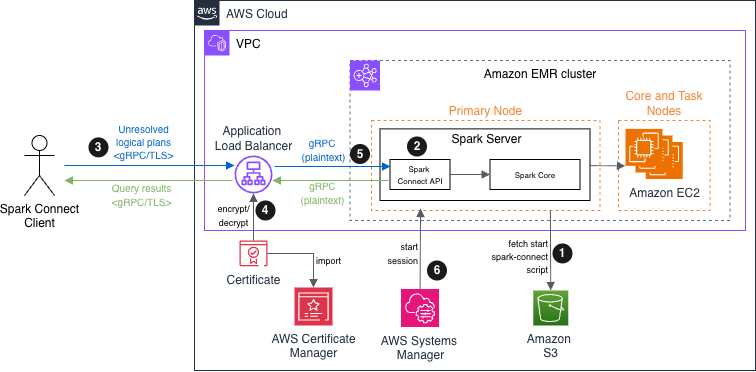
Apache Spark Join on Amazon EMR answer structure diagram
Conditions
To proceed with this submit, guarantee you may have the next:
Implementation steps
On this recipe, by means of AWS CLI instructions, you’ll:
- Put together the bootstrap script, a bash script beginning Spark Join on Amazon EMR.
- Arrange the permissions for Amazon EMR to provision assets and carry out service-level actions with different AWS providers.
- Create the Amazon EMR cluster with these related roles and permissions and finally connect the ready script as a bootstrap motion.
- Deploy the Utility Load Balancer and certificates with ACM safe information in transit over the web.
- Modify the first node’s safety group to permit Spark Join purchasers to attach.
- Join with a check software connecting the shopper to Spark Join server.
Put together the bootstrap script
To organize the bootstrap script, observe these steps:
- Create an Amazon S3 bucket to host the bootstrap bash script:
- Open your most well-liked textual content editor, add the next instructions in a brand new file with a reputation such
start-spark-connect.sh. If the script runs on the first node, it begins Spark Join server. If it runs on a job or core node, it does nothing: - Add the script into the bucket created in step 1:
Arrange the permissions
Earlier than creating the cluster, you could create the service function, and occasion profile. A service function is an IAM function that Amazon EMR assumes to provision assets and carry out service-level actions with different AWS providers. An EC2 occasion profile for Amazon EMR assigns a task to each EC2 occasion in a cluster. The occasion profile should specify a task that may entry the assets in your bootstrap motion.
- Create the IAM function:
- Connect the mandatory managed insurance policies to the service function to permit Amazon EMR to handle the underlying providers Amazon EC2 and Amazon S3 in your behalf and optionally grant an occasion to work together with Methods Supervisor:
- Create an Amazon EMR occasion function to grant permissions to EC2 situations to work together with Amazon S3 or different AWS providers:
- To permit the first occasion to learn from Amazon S3, connect the
AmazonS3ReadOnlyAccesscoverage to the Amazon EMR occasion function. For manufacturing environments, this entry coverage needs to be reviewed and changed with a customized coverage following the precept of least privilege, granting solely the particular permissions wanted in your use case: - Attaching AmazonSSMManagedInstanceCore coverage allows the situations to make use of core Methods Supervisor options, equivalent to Session Supervisor, and Amazon CloudWatch:
- To move the
EMR_EC2_SparkClusterInstanceProfileIAM function info to the EC2 situations after they begin, create the Amazon EMR EC2 occasion profile: - Connect the function
EMR_EC2_SparkClusterNodesRolecreated in step 3 to the newly occasion profile:
Create the Amazon EMR cluster
To create the Amazon EMR cluster, observe these steps:
- Set the surroundings variables, the place your EMR cluster and load-balancer should be deployed:
- Create the EMR cluster with the newest Amazon EMR launch. Substitute the placeholder worth together with your precise S3 bucket title the place the bootstrap motion script is saved:
To switch main node’s safety group to permit Methods Supervisor to start out a session.
- Get the first node’s safety group identifier. File the identifier since you’ll want it for subsequent configuration steps by which
primary-node-security-group-idis talked about: - Discover the EC2 occasion join prefix checklist ID in your Area. You need to use the
EC2_INSTANCE_CONNECTfilter with the describe-managed-prefix-lists command. Utilizing a managed prefix checklist offers a dynamic safety configuration to authorize Methods Supervisor EC2 situations to attach the first and core nodes by SSH: - Modify the first node safety group inbound guidelines to permit SSH entry (port 22) to the EMR cluster’s main node from assets which are a part of the desired Occasion Join service contained within the prefix checklist:
Optionally, you possibly can repeat the previous steps 1–3 for the core (and duties) cluster’s nodes to permit Amazon EC2 Occasion Hook up with entry the EC2 occasion by means of SSH.
Deploy the Utility Load Balancer and certificates
To deploy the Utility Load Balancer and certificates, observe these steps:
- Create a load balancer’s safety group:
- Add rule to just accept TCP site visitors from a trusted IP on port 443. We suggest that you just use the native growth machine’s IP tackle. You may verify your present public IP tackle right here: https://checkip.amazonaws.com:
- Create a brand new goal group with gRPC protocol, which targets the Spark Join server occasion and the port the server is listening to:
- Create the Utility Load Balancer:
- Get the load balancer DNS title:
- Retrieve the Amazon EMR main node ID:
- (Elective) To encrypt and decrypt the site visitors, the load balancer wants a certificates. You may skip this step if you have already got a trusted certificates in ACM. In any other case, create a self-signed certificates:
- Add to ACM:
- Create the load balancer listener:
- After the listener has been provisioned, register the first node to the goal group:
Modify the first node’s safety group to permit Spark Join purchasers to attach
To hook up with Spark Join, amend solely the first safety group. Add an inbound rule to the first’s node safety group to just accept Spark Join TCP connection on port 15002 out of your chosen trusted IP tackle:
Join with a check software
This instance demonstrates {that a} shopper working a more recent Spark model (4.0.1) can efficiently hook up with an older Spark model on the Amazon EMR cluster (3.5.5), showcasing Spark Join’s model compatibility function. This model mixture is for demonstration solely. Working older variations may pose safety dangers in manufacturing environments.
To check the client-to-server connection, we offer the next check Python software. We suggest that you just create and activate a Python digital surroundings (venv) earlier than putting in the packages. This helps isolate the dependencies for this particular undertaking and prevents conflicts with different Python initiatives. To put in packages, run the next command:
In your built-in growth surroundings (IDE), copy and paste the next code, substitute the placeholder, and invoke it. The code creates a Spark DataFrame containing two rows and it exhibits its information:
The next exhibits the appliance output:
Clear up
Whenever you now not want the cluster, launch the next assets to cease incurring prices:
- Delete the Utility Load Balancer listener, goal group, and the load balancer.
- Delete the ACM certificates.
- Delete the load balancer and Amazon EMR node safety teams.
- Terminate the EMR cluster.
- Empty the Amazon S3 bucket and delete it.
- Take away
AmazonEMR-ServiceRole-SparkConnectDemoandEMR_EC2_SparkClusterNodesRoleroles andEMR_EC2_SparkClusterInstanceProfileoccasion profile.
Issues
Safety concerns with Spark Join:
- Personal subnet deployment – Preserve EMR clusters in personal subnets with no direct web entry, utilizing NAT gateways for outbound connectivity solely.
- Entry logging and monitoring – Allow VPC Move Logs, AWS CloudTrail, and bastion host entry logs for audit trails and safety monitoring.
- Safety group restrictions – Configure safety teams to permit Spark Join port (15002) entry solely from bastion host or particular IP ranges.
Conclusion
On this submit, we confirmed how one can undertake fashionable growth workflows and debug Spark purposes from native IDEs or notebooks, so you possibly can step by means of code execution. With Spark Join’s client-server structure, the Spark cluster can run on a distinct model than the shopper purposes, so operations groups can carry out infrastructure upgrades and patches independently.
Because the cluster operators acquire expertise, they’ll customise the bootstrap actions and add steps to course of information. Think about exploring Amazon Managed Workflows for Apache Airflow (MWAA) for orchestrating your information pipeline.
Concerning the authors