ESG reporting or Environmental, Social, and Governance reporting, typically feels overwhelming as a result of the info comes from so many locations and takes ages to tug collectively. Groups spend most of their time gathering numbers as a substitute of decoding what they imply. Agentic AI adjustments that dynamic. As a substitute of 1 chatbot answering questions, you get a coordinated group of AI helpers that work like a devoted reporting crew. They collect info, test it in opposition to related guidelines, and put together clear draft summaries so people can concentrate on perception quite than paperwork.
On this information, we’re going to current, step-by-step, a sensible, developer-centric pipeline for ESG reporting masking:
- Knowledge aggregation: Make use of concurrent brokers to acquire knowledge from APIs and paperwork after which index it utilizing vector search (e.g., OpenAI embeddings + FAISS).
- Compliance checks: Execute regulatory guidelines (like CSRD or EU Taxonomy) via code logic or SQL queries to focus on any issues.
- Good Report: Direct the creation of a story report by utilizing Retrieval-Augmented Technology (RAG) and LLM chains and ship it as a PDF.
Step 1: Aggregating ESG Knowledge with AI Brokers
Initially, it’s essential to gather all pertinent knowledge by parallel means. As an instance, one agent can get hold of the newest ESG analysis via arXiv API, one other can search for latest regulatory updates through a information API, and a 3rd can classify the corporate’s inner ESG paperwork.
In a single experiment, three particular “search brokers” operated concurrently to make inquiries to arXiv, an inner Azure AI Search index, and information sources. After that, every agent offered the central data base with its knowledge. We will emulate this course of in Python by using threads together with a vector retailer for doc search:
import requests
import concurrent.futures
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# ESG Knowledge Aggregation and RAG Pipeline Instance
# 1. Exterior Search Capabilities
# Instance: search arXiv for ESG-related papers
def search_arxiv(question, max_results=3):
"""Searches the arXiv API for papers."""
url = (
f"http://export.arxiv.org/api/question?"
f"search_query=all:{question}&max_results={max_results}"
)
res = requests.get(url)
# (Parse the XML response; right here we simply return uncooked textual content for brevity)
return res.textual content[:200] # present first 200 chars of outcome
# Instance: search information utilizing a hypothetical API (substitute with an actual information API)
def search_news(question, api_key):
"""Searches a hypothetical information API (wants substitute with an actual one)."""
# NOTE: It is a placeholder URL and won't work with no actual information API
url = f"https://newsapi.instance.com/search?q={question}&apiKey={api_key}"
strive:
# Simulate a request; this can probably fail with a 404/SSL error
res = requests.get(url, timeout=5)
articles = res.json().get("articles", [])
return [article["title"] for article in articles[:3]]
besides requests.exceptions.RequestException as e:
return [f"Error fetching news (API Placeholder): {e}"]
# 2. Inner Doc Indexing Operate (for RAG)
def build_vector_index(pdf_paths):
"""Hundreds, splits, and embeds PDF paperwork right into a FAISS vector retailer."""
splitter = CharacterTextSplitter(chunk_size=800, chunk_overlap=100)
all_docs = []
# NOTE: PyPDFLoader requires the recordsdata 'annual_report.pdf' and 'energy_audit.pdf' to exist
for path in pdf_paths:
strive:
loader = PyPDFLoader(path)
pages = loader.load()
docs = splitter.split_documents(pages)
all_docs.lengthen(docs)
besides Exception as e:
print(f"Warning: Couldn't load PDF {path}. Skipping. Error: {e}")
if not all_docs:
# Return a easy object or increase an error if no paperwork had been loaded
print("Error: No paperwork had been efficiently loaded to construct the index.")
return None
embeddings = OpenAIEmbeddings()
vector_index = FAISS.from_documents(all_docs, embeddings)
return vector_index
# --- Most important Execution ---
# Paths to inner ESG PDFs (should exist in the identical listing or have full path)
pdf_files = ["annual_report.pdf", "energy_audit.pdf"]
# Run exterior searches and doc indexing in parallel
print("Beginning parallel knowledge fetching and index constructing...")
with concurrent.futures.ThreadPoolExecutor() as executor:
# Exterior Searches
future_arxiv = executor.submit(search_arxiv, "web zero 2030")
# NOTE: Exchange 'YOUR_NEWS_API_KEY' with a legitimate key for an actual information API
future_news = executor.submit(
search_news,
"EU CSRD regulation",
"YOUR_NEWS_API_KEY"
)
# Construct vector index (will print warnings if PDFs do not exist)
future_index = executor.submit(build_vector_index, pdf_files)
# Accumulate outcomes
arxiv_data = future_arxiv.outcome()
news_data = future_news.outcome()
vector_index = future_index.outcome()
print("n--- Aggregated Outcomes ---")
print("ArXiv fetched knowledge snippet:", arxiv_data)
print("High information titles:", news_data)
if vector_index:
print("nFAISS Vector Index efficiently constructed.")
# Instance continuation: Initialize the RAG chain
# llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
# qa_chain = RetrievalQA.from_chain_type(
# llm=llm,
# retriever=vector_index.as_retriever()
# )
# print("RAG setup full. Prepared to question inner paperwork.")
else:
print("RAG setup skipped on account of failed vector index creation.")Output:


Right here, we used a thread pool to concurrently name totally different sources. One thread fetches arXiv papers, one other calls a information API, and one other builds a vector retailer of inner paperwork. The vector index makes use of OpenAI embeddings saved in FAISS, enabling natural-language search over the paperwork.
Querying the Aggregated Knowledge
With the info collected, brokers can question it through pure language. For instance, we are able to use LangChain’s RAG pipeline to ask questions in opposition to the listed paperwork:
# Create a retriever from the FAISS index
retriever = vector_index.as_retriever(
search_type="similarity",
search_kwargs={"okay": 4}
)
# Initialize an LLM (e.g., GPT-4) and a RetrievalQA chain
llm = ChatOpenAI(temperature=0, mannequin="gpt-4")
qa_chain = RetrievalQA(llm=llm, retriever=retriever)
# Ask a pure language query about ESG knowledge
reply = qa_chain.run("What had been the Scope 2 emissions for 2023?")
print("RAG reply:", reply)This RAG method lets the agent retrieve related doc segments (through similarity search) after which generate a solution. In a single demonstration, an agent transformed plain-English queries to SQL to fetch numeric knowledge (e.g. “Scope 2 emissions in 2024”) from the emissions database. We will equally embed a SQL question step if wanted, for instance utilizing SQLite in Python:
import sqlite3
# Instance: retailer some emissions knowledge in SQLite
conn = sqlite3.join(':reminiscence:')
cursor = conn.cursor()
cursor.execute("CREATE TABLE emissions (12 months INTEGER, scope2 REAL)")
cursor.execute("INSERT INTO emissions VALUES (2023, 1725.4)")
conn.commit()
# Easy SQL question for numeric knowledge
cursor.execute("SELECT scope2 FROM emissions WHERE 12 months=2023")
scope2_emissions = cursor.fetchone()[0]
print("Scope 2 emissions 2023 (from DB):", scope2_emissions) In observe, you might combine a LangChain SQL Agent to transform pure language to SQL mechanically. No matter supply, all these knowledge factors – from PDFs, APIs, and databases – feed right into a unified data base for the reporting pipeline.
Step 2: Automated Compliance Checks
The compliance assurance course of is subsequent in line after the uncooked metrics have been gathered. The combination of code logic and LLM assist might help on this regard. For example, we are able to map the foundations of the area (such because the EU Taxonomy standards) after which carry out checks:
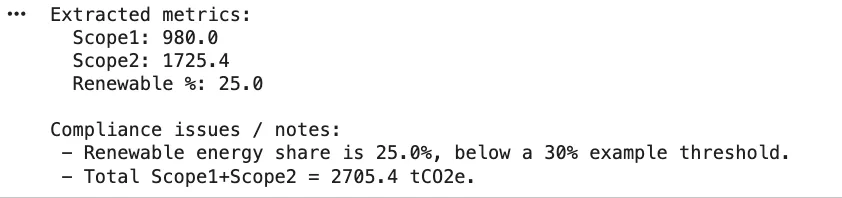
# Instance ESG metrics extracted from knowledge aggregation
metrics = {
"scope1_tCO2": 980,
"scope2_tCO2": 1725.4,
"renewable_percent": 25, # % of power from renewables
"water_usage_liters": 50000,
"reported_water_liters": 48000
}
# Easy rule-based compliance checks
def run_compliance_checks(metrics):
"""
Runs primary checks in opposition to predefined ESG compliance guidelines.
"""
points = []
# Instance rule 1: EU Taxonomy requires >= 30% renewable power
if metrics["renewable_percent"] < 30:
points.append("Renewables beneath EU taxonomy threshold (30%).")
# Instance rule 2: Consistency test (tolerance of 1000 liters)
if abs(metrics["water_usage_liters"] - metrics["reported_water_liters"]) > 1000:
points.append("Water utilization mismatch between operations knowledge and monetary report.")
return points
# Execute the checks
compliance_issues = run_compliance_checks(metrics)
print("Compliance points discovered:", compliance_issues)This straightforward perform identifies any guidelines which have been violated. In actual life, you’d maybe get guidelines from a data base or configuration. Compliance checks are incessantly divided into roles in agent-based methods. The Standards/Mapping brokers hyperlink the info that has been extracted to the particular disclosure fields or the factors of the taxonomy whereas the Calculation brokers perform the numeric checks or conversions. To quote an instance, one of many brokers might test if a selected exercise conforms to the “Do No Vital Hurt” standards set by the Taxonomy or might derive complete emissions by way of text-to-SQL queries.
Textual content-to-SQL Instance (Elective)
LangChain offers SQL instruments to automate this step. For example, one can create a SQL Agent that examines your database schema and generates queries. Right here’s a sketch utilizing LangChain’s SQLDatabase :
from langchain.brokers import create_sql_agent
from langchain.sql_database import SQLDatabase
# Arrange a SQLite DB (identical as above)
db = SQLDatabase.from_uri("sqlite:///:reminiscence:", include_tables=["emissions"])
# Create an agent that may reply questions utilizing the DB
sql_agent = create_sql_agent(llm=llm, db=db, verbose=False)
query_result = sql_agent.run("What's the complete Scope 2 emissions for 2023?")
print("SQL Agent outcome:", query_result)This agent will introspect the emissions desk and produce a question to calculate the reply, verifying it earlier than returning a outcome. (In observe, guarantee your database permissions are locked down, as executing model-generated SQL has dangers.)
Step 3: Generative Good Reporting with RAG Brokers
After validation, the ultimate stage is to compose the narrative report. Right here a synthesis agent takes the cleaned knowledge and writes human-readable disclosures. We will use LLM chains for this, typically with RAG to incorporate particular figures and citations. For instance, we would immediate the mannequin with the important thing metrics and let it draft a abstract:
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
# Put together a immediate template to generate an government abstract
prompt_template = """
Write a concise government abstract of the ESG report utilizing the info beneath.
Embody key figures and context:
{summary_data}
"""
template = PromptTemplate(
input_variables=["summary_data"],
template=prompt_template
)
# Instance knowledge to incorporate within the abstract
findings = f"""
- Scope 1 CO2 emissions: {metrics['scope1_tCO2']} tCO2e
- Scope 2 CO2 emissions: {metrics['scope2_tCO2']} tCO2e
- Renewable power share: {metrics['renewable_percent']}%
"""
chain = LLMChain(llm=ChatOpenAI(temperature=0.2), immediate=template)
summary_text = chain.run({"summary_data": findings})
print("Generated abstract:n", summary_text)Output:
=== ANSWER ===
Within the **Sustainability Annual Report 2024**, the reported emissions are as follows:- **Scope 1 Emissions**: 980 tCO2e
- **Scope 2 Emissions**: 1,725.4 tCO2eThe whole emissions quantity to **2,705.4 tCO2e**.
A notable compliance hole is recognized within the **Power Audit Abstract - 2024**, the place the renewable power share is reported at **28%**, which is beneath the regulatory goal of **30%**. This means a necessity for enchancment in renewable power utilization to satisfy compliance requirements.
Moreover, the report highlights a advice so as to add **500 kW** of rooftop photo voltaic to reinforce renewable power capability.
Alternatively, you possibly can construct a chained RetrievalQA or agent that pulls from the listed paperwork and knowledge, then calls the LLM to put in writing every part. For instance, utilizing LangChain’s RetrievalQA as above, you might ask the agent to “Summarize Scope 1 and a couple of emissions and spotlight any compliance gaps.” The bottom line is that each reply can cite sources or strategies, enabling an proof path .
Step 4: Compiling the Remaining Report
After drafting, it might be potential to mix and format the sections as it’s executed in a quite simple approach by utilizing fpdf. PDF can be used to put in writing the abstract.
from fpdf import FPDF
pdf = FPDF()
pdf.add_page()
pdf.set_font("Arial", dimension=14)
pdf.multi_cell(0, 10, summary_text)
pdf.output("esg_report_summary.pdf")
print("PDF report generated.")Output:

In a whole pipeline, one might make many sections (like cultures, emissions, power, water, and so forth.) and put them collectively. Brokers might even help in human-in-the-loop modifying: the draft solutions are proven in a chat UI for area consultants to judge and enhance. As soon as authorized, a synthesis agent can create the ultimate PDF or textual content deliverable, together with tables and figures being as essential.
In the long run, this agentic workflow reduces the time spent on handbook reporting from weeks to hours: brokers fill within the questionnaire gadgets from the info in batches, mark any points, let human overview, after which produce a full report. Each reply comes with inline references and calculation steps for readability. The end result is an ESG report prepared for audit which was generated by code and AI, not a human hand.
Conclusion
An end-to-end ESG workflow can run far smoother when a number of AI brokers share the load. They pull info from analysis sources, information feeds, and inner recordsdata on the identical time, test the info in opposition to related guidelines, and assist form the ultimate report utilizing context-aware era. The code examples present how every half stays clear and modular, making it simple to plug in actual APIs, increase the rule set, or modify the logic when laws shift. The true win is time: groups spend much less power chasing knowledge and extra on understanding what it means. With this pipeline, you may have a transparent blueprint for constructing your individual agent-driven ESG reporting system.
Ceaselessly Requested Questions
A. It splits the workload throughout autonomous brokers that pull knowledge, test compliance, and draft sections in parallel. A lot of the grunt work disappears, leaving people to overview and refine as a substitute of assembling every little thing by hand.
A. Not likely. A typical setup makes use of Python, LangChain, vector search instruments like FAISS, and an LLM API. You possibly can scale up later with workflow orchestrators or cloud features if wanted.
A. Sure. Compliance guidelines stay in code or configuration, so you possibly can replace or add new rule modules with out touching the remainder of the pipeline. Brokers mechanically apply the newest logic throughout checks.
Knowledge Science Trainee at Analytics Vidhya
I’m at the moment working as a Knowledge Science Trainee at Analytics Vidhya, the place I concentrate on constructing data-driven options and making use of AI/ML methods to resolve real-world enterprise issues. My work permits me to discover superior analytics, machine studying, and AI functions that empower organizations to make smarter, evidence-based choices.
With a robust basis in pc science, software program growth, and knowledge analytics, I’m enthusiastic about leveraging AI to create impactful, scalable options that bridge the hole between expertise and enterprise.
📩 You can too attain out to me at [email protected]
Login to proceed studying and luxuriate in expert-curated content material.