Apache HBase is a database system for large information purposes that effectively manages billions of rows and thousands and thousands of columns. Its distributed, column-oriented construction handles each structured and unstructured information whereas addressing pace, flexibility, and scalability challenges. Amazon EMR HBase on Amazon S3 extends these options by storing information straight in Amazon S3, enabling information persistence and cross-zone entry whereas supporting compute-based cluster sizing and read-only replicas.
HBase BucketCache serves as a complicated L2 caching mechanism that works alongside conventional on-heap reminiscence cache. It shops massive information volumes outdoors the JVM heap, decreasing rubbish assortment overhead whereas sustaining quick entry. When mixed with Amazon EBS gp3 SSDs, it offers near-HDFS efficiency at decrease prices.
Nonetheless, implementing terabyte-scale BucketCache in manufacturing environments presents challenges: figuring out optimum cache sizes, balancing value versus efficiency, and configuring eviction insurance policies for S3-backed storage.
On this put up, we exhibit how you can enhance HBase learn efficiency by implementing bucket caching on Amazon EMR. Our checks diminished latency by 57.9% and improved throughput by 138.8%. This answer is especially worthwhile for large-scale HBase deployments on Amazon S3 that have to optimize learn efficiency whereas managing prices.
The next diagram exhibits Amazon EMR’s integration with Apache HBase and Amazon S3 to implement a multi-tiered caching technique.
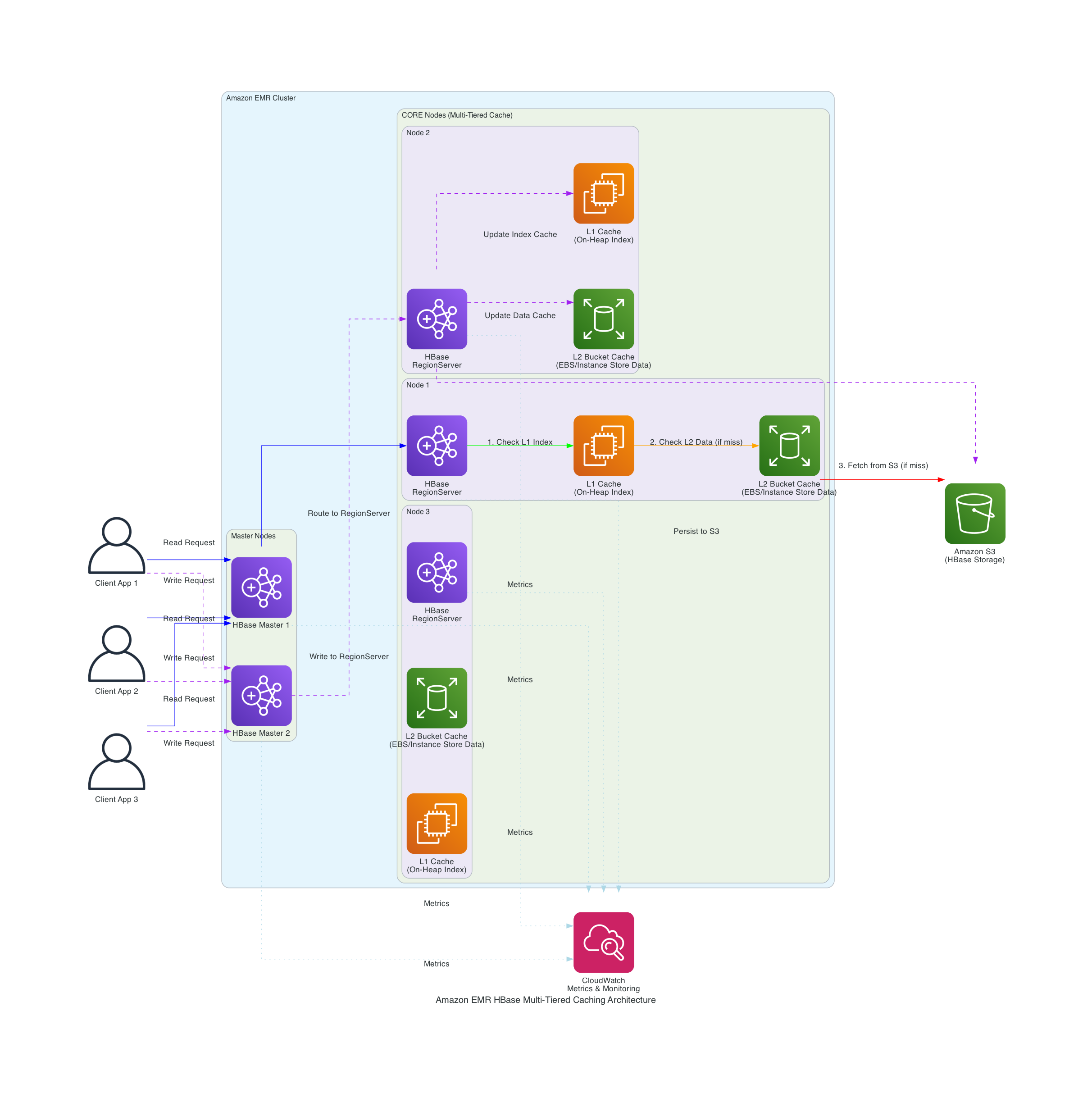
Determine 1 – Resolution Structure
The answer implements key parts:
- Configure persistent bucket cache with validated parameters
- Implement cache-aware load balancing
- Use ZGC for improved rubbish assortment efficiency
- Monitor cache effectiveness by l2CacheHitRatio utilizing Amazon EMR metrics
In our testing with datasets in terabytes, we achieved:
- Bucket cache hit ratios exceeding 95%
- S3 GET requests diminished to underneath 1,000/hour at peak efficiency
- Learn latencies diminished to milliseconds
- Zero JVM pause detection throughout excessive learn workloads
- 138.8% enchancment in learn throughput
Walkthrough
Stipulations
This part exhibits how we improved HBase learn efficiency utilizing bucket caching on Amazon EMR in our checks. Earlier than implementing this answer, it is best to have:
AWS sources
Technical necessities:
For setup directions, seek advice from:
Create an EMR Cluster with optimized configuration
Create your EMR cluster utilizing the next exampled launch command. This command is an optimization demo for terabyte-scale bucket caching:
Clarify configurations for HBase optimized cache efficiency
Within the above launch command, you possibly can see configurations by the EMR software program configurations. These settings are particularly for terabyte-scale caching eventualities. When HBase is put in on EMR, Apache YARN’s reminiscence allocation is diminished by roughly 50% from its default configuration (68-73% of RAM) to 34-36% of bodily RAM, reserving reminiscence for HBase RegionServer operations. The cache and memstore sizes should be fastidiously balanced in opposition to out there node reminiscence to forestall useful resource rivalry.
The hbase.bucketcache.dimension parameter determines the full bucket cache dimension per RegionServer in megabytes, which straight impacts how a lot information might be saved in bucket cache. If the info information are saved in compressed codecs, it’s important to allow hbase.block.information.cachecompressed . This function retains blocks compressed within the cache, decreasing reminiscence footprint whereas sustaining fast entry instances. Your EBS dimension per RegionServer relies on the worth of hbase.bucketcache.dimension. The configured EBS dimension might be the worth of this function plus a buffer for system utilization. The hbase.bucketcache.bucket.sizes setting defines bucket sizes to effectively accommodate totally different information block sizes, whereas hbase.bucketcache.author.threads controls the variety of threads used for writing to the cache, optimizing write efficiency.
Within the above launch command, we configured ZGC settings to optimize rubbish assortment.
Utilizing ZGC minimizes the necessity for a big JVM heap to accommodate JVM objects for large-scale bucket cache operations, leading to fewer JVM pauses. By adjusting the heap dimension by growing or lowering the HBASE_HEAPSIZE parameter, you possibly can optimize reminiscence allocation on your particular workload. A key benefit of ZGC is that it retains JVM pause instances quick no matter heap dimension, whereas conventional rubbish collectors expertise longer full GC instances as heap dimension will increase. This makes ZGC notably worthwhile for HBase deployments with terabyte-scale bucket caches, the place sustaining constant low-latency efficiency is vital.
The generational rubbish assortment settings effectively handle reminiscence by separating short-lived objects from long-lived ones, decreasing assortment frequency and overhead. The AlwaysPreTouch parameter improves Apache HBase responsiveness by pre-allocating reminiscence throughout operation.
Clarify EMR metrics assortment configurations
Within the above launch command, we arrange configurations to publish emr metrics to CloudWatch by CloudWatch Brokers. We will use these metrics to trace bucket cache request quantity and hit ratios. If L2CacheHitRatio is excessive however L2CacheMissCount is low, it means HBase can fetch many of the requested information in bucket cache. The learn latencies might be shorted to milliseconds on this case.
Efficiency testing and outcomes
This part particulars our efficiency testing methodology and outcomes utilizing a 7.9 TB dataset.
Take a look at setup
- We used ycsb to generate and check with a 7.9 TB dataset.
- We used the next command to run a read-only workload:
| Configuration | Throughput (ops/sec) | Latency (ms) |
| With out Cache | 371.93 | 2680 |
| With Cache | 888.67 | 1127 |
| Enchancment | 138.80% | 57.90% |
In our learn efficiency check utilizing bucket cache to cache terabytes of information, we achieved a 138.8% enchancment in learn throughput (from 371.93 to 888.67 ops/sec) and a 57.9% discount in learn latency (from 2680ms to 1127ms) in comparison with a state of affairs with out bucket cache.
Learn efficiency enchancment
As proven within the previoustable, implementing bucket cache led to enhancements in each throughput and latency. The system achieved a 138.8% improve in throughput, processing 888.67 operations per second in comparison with the baseline 371.93 ops/sec. Equally, latency was diminished by 57.9%, dropping from 2680ms to 1127ms, demonstrating the efficiency advantages of the caching answer. The next chart exhibits implementing bucket cache led to enhancements in common throughput in comparison with a state of affairs with out bucket cache.
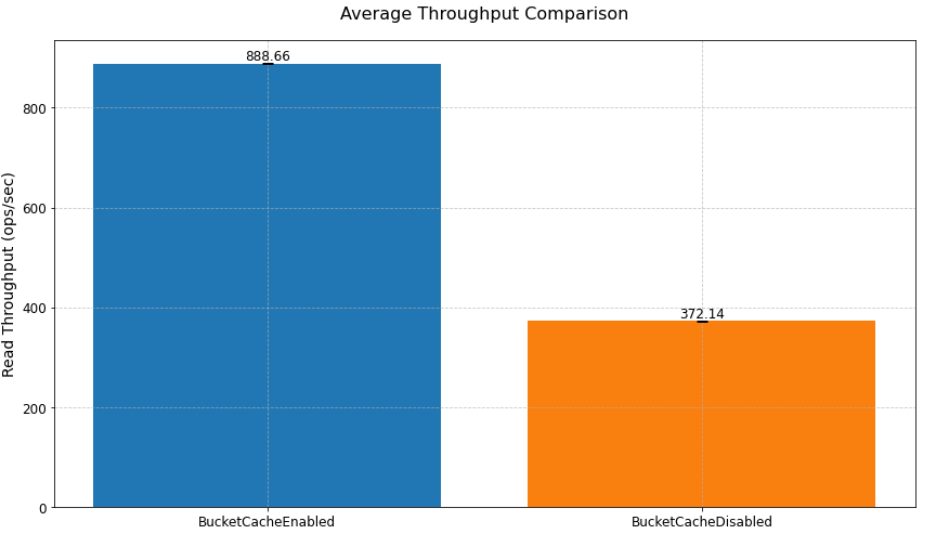
Determine 2 – Common throughput comparability
Cache hit ratio development
The cache hit ratio information demonstrates the effectiveness of the bucket cache implementation over time. Ranging from 0% at initialization, the cache hit ratio improved to 85% inside 12 hours, finally stabilizing above 95% after 24 hours. This development corresponded with an intensive discount in Amazon S3 GetObject requests, from 95,000 per hour initially to fewer than 1,000 per hour at peak efficiency, decreasing each latency and prices.
| Time (hours) | Hit Ratio | S3 Requests/hour |
| 0 | 0% | 95,000 |
| 12 | 85% | 15,000 |
| 24 | 95%+ |
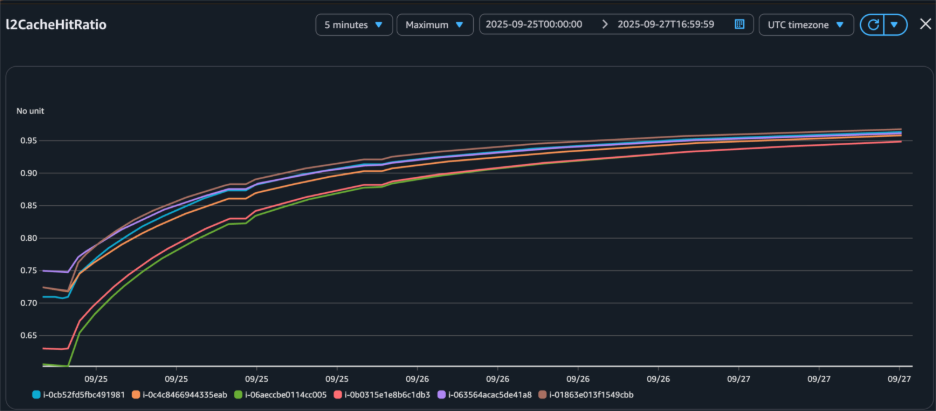
Determine 3 – Bucket cache hit ratio elevated after we loaded information to bucket cache by read-only workload.
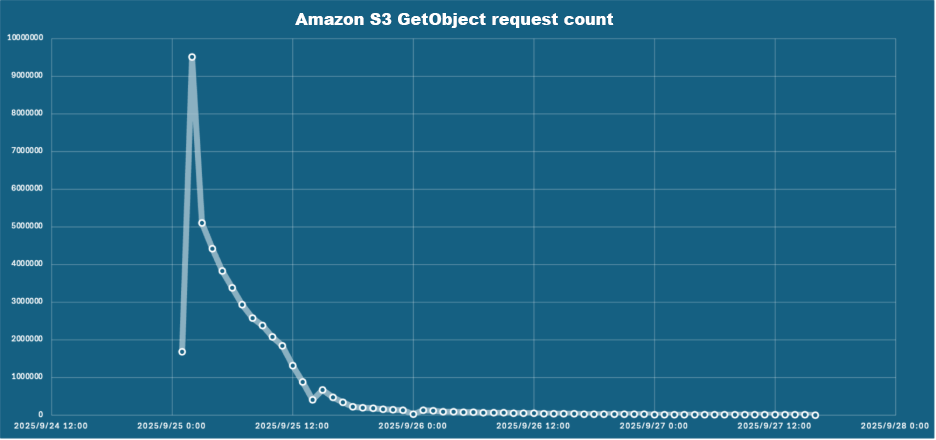
Determine 4 – Amazon S3 GetObject request rely decreased as bucket cache hit ratio elevated.
Key implementation: persistent bucket cache
One of many key options launched in HBase 2.6.0 after Amazon EMR 7.6.0 is persistent bucket cache, which maintains cache information throughout RegionServer restarts. This function is especially for manufacturing environments the place sustaining constant efficiency throughout upkeep operations is essential. The next part exhibit how you can configure persistent bucket cache.
Configuring persistent bucket cache
Arrange persistent bucket cache by implementing these configurations:
Efficiency influence of persistent cache
The next desk exhibits the checks demonstrated important enhancements in RegionServer restart efficiency. With persistent cache enabled, the HBase cluster maintained constant learn request efficiency and low latency after RegionServer restarts since information remained straight accessible within the bucket cache. In distinction, clusters with out persistent cache required 6 hours to reload bucket cache after RegionServer restarts earlier than reaching comparable learn operation efficiency and latency ranges. It demonstrates important enhancements from enabling persistent cache.
| Pre-restart throughput | Submit-restart throughput | Restoration time | |
| With out Persistent Cache | 888.67 ops/sec | 371.93 ops/sec | ~6 hours |
| With Persistent Cache | 889.08 ops/sec | 886.71 ops/sec |
Within the following graph, the RegionServer L2 cache dimension metrics revealed that the bucket cache dimension remained secure after RegionServer restart, confirming that the cached information was preserved fairly than reset in the course of the course of. The metrics had been unavailable between 16:30 and 16:35 as a result of the RegionServer was stopped and restarted.
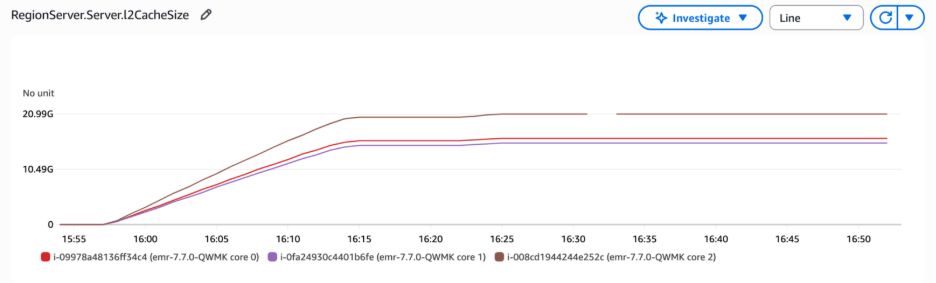
Determine 5 – The bucket cache dimension remained secure after RegionServer restart
L2 cache miss rely is a cumulative metric that tracks cache misses from RegionServer startup. When the RegionServer restarts, this metric resets to zero. Within the following graph, the L2 cache miss rely elevated steeply originally as a result of learn requests retrieved information from HFiles, as the info had not but been loaded into bucket cache. Over time, the bucket cache was populated with information by read-only workload, and the slope of the L2 cache miss rely decreased. We restarted RegionServer between 16:30 and 16:35 . Thus, L2 cache miss rely reset to 0. Notably, these metrics remained at zero even throughout subsequent consumer learn operations. The requests didn’t retrieve information from HFiles that triggered a rise in L2 cache miss rely. This confirmed that information endured within the bucket cache and was straight accessible with out requiring cache rebuilding.
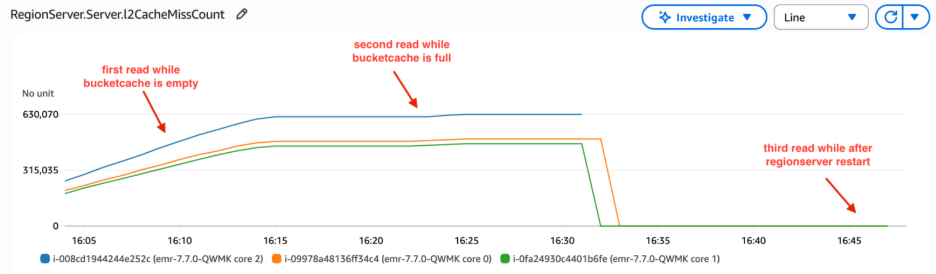
Determine 6 – Regionserver bucketcache miss rely remained 0 after restarting RegionServer
The RegionServer learn request rely metrics demonstrated constant learn operation volumes following restart. This indicated that RegionServers maintained learn efficiency ranges without having to fetch HFiles from Amazon S3, thus avoiding the elevated latency and diminished throughput usually related to S3 lookups. This persistent cache conduct straight reduces S3 prices by minimizing API calls—our above testing statistics confirmed S3 GET requests dropping from 95,000 per hour throughout preliminary cache warming to fewer than 1,000 per hour as soon as the cache reached optimum efficiency, representing a 99% discount in S3 API name quantity.
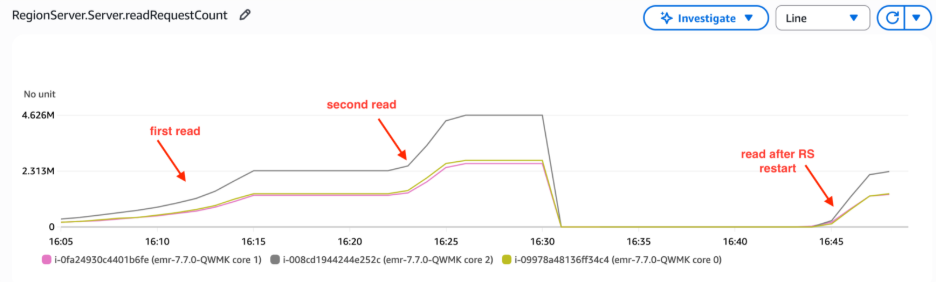
Determine 7 – Regionserver learn request rely
Greatest practices and proposals
On this part, we share tips to optimize HBase bucket cache efficiency.
cache sizing tips
For optimum efficiency, dimension your bucket cache appropriately by making certain the full cache dimension exceeds your goal cached information quantity. Inadequate bucket cache dimension will result in frequent information evictions, degrading system efficiency. Monitor free cache area utilizing Amazon CloudWatch metrics to forestall overflow points. Moreover, persistently analyze L2 cache hit ratio metrics to evaluate efficiency, and alter bucket cache dimension primarily based in your particular workload patterns and L2 hit ratio developments. These ongoing monitoring and adjustment practices will assist preserve optimum cache efficiency and useful resource utilization.
Efficiency optimization
To additional improve HBase learn efficiency, take into account implementing the next configuration settings. These optimizations are designed to enhance cache utilization, cut back disk I/O, and reduce latency for frequent learn operations:
Useful resource monitoring
Arrange Amazon CloudWatch dashboards to observe key metrics. These dashboards ought to observe L2 cache hit ratios, which offer perception into the effectiveness of your caching technique. Moreover, monitor Amazon S3 request patterns to grasp your information entry developments and optimize accordingly. Maintain a detailed eye on reminiscence utilization to make sure your cases have adequate sources to deal with the workload effectively. Lastly, repeatedly analyze rubbish assortment (GC) patterns to establish and tackle any potential reminiscence administration points that would influence efficiency.
Cleansing up
To keep away from incurring pointless expenses, clear up your sources if you’re achieved testing
Conclusion
On this put up, you discovered how you can implement and optimize HBase bucket cache with persistent storage on Amazon EMR. In our testing, we achieved 95%+ cache hit ratios with constant millisecond latencies. The implementation diminished Amazon S3 entry prices by minimizing the variety of direct Amazon S3 requests required. Learn efficiency noticed 138.8% enchancment in learn throughput. The system maintained secure efficiency throughout upkeep home windows, eliminating efficiency degradation throughout routine operations. Moreover, the answer demonstrated higher useful resource utilization, maximizing the effectivity of the allotted infrastructure whereas minimizing waste.
Associated sources
In regards to the writer