Enterprise information isn’t helpful in a silo. Answering questions like, “Which of our merchandise have had declining gross sales over the previous three months, and what probably associated points are introduced up in buyer evaluations on numerous vendor websites?” requires reasoning throughout a mixture of structured and unstructured information sources, together with information lakes, evaluation information, and product data administration techniques. On this weblog, we show how Databricks Agent Bricks Supervisor Agent (SA) might help with these advanced, practical duties by means of multi-step reasoning grounded in a hybrid of structured and unstructured information.
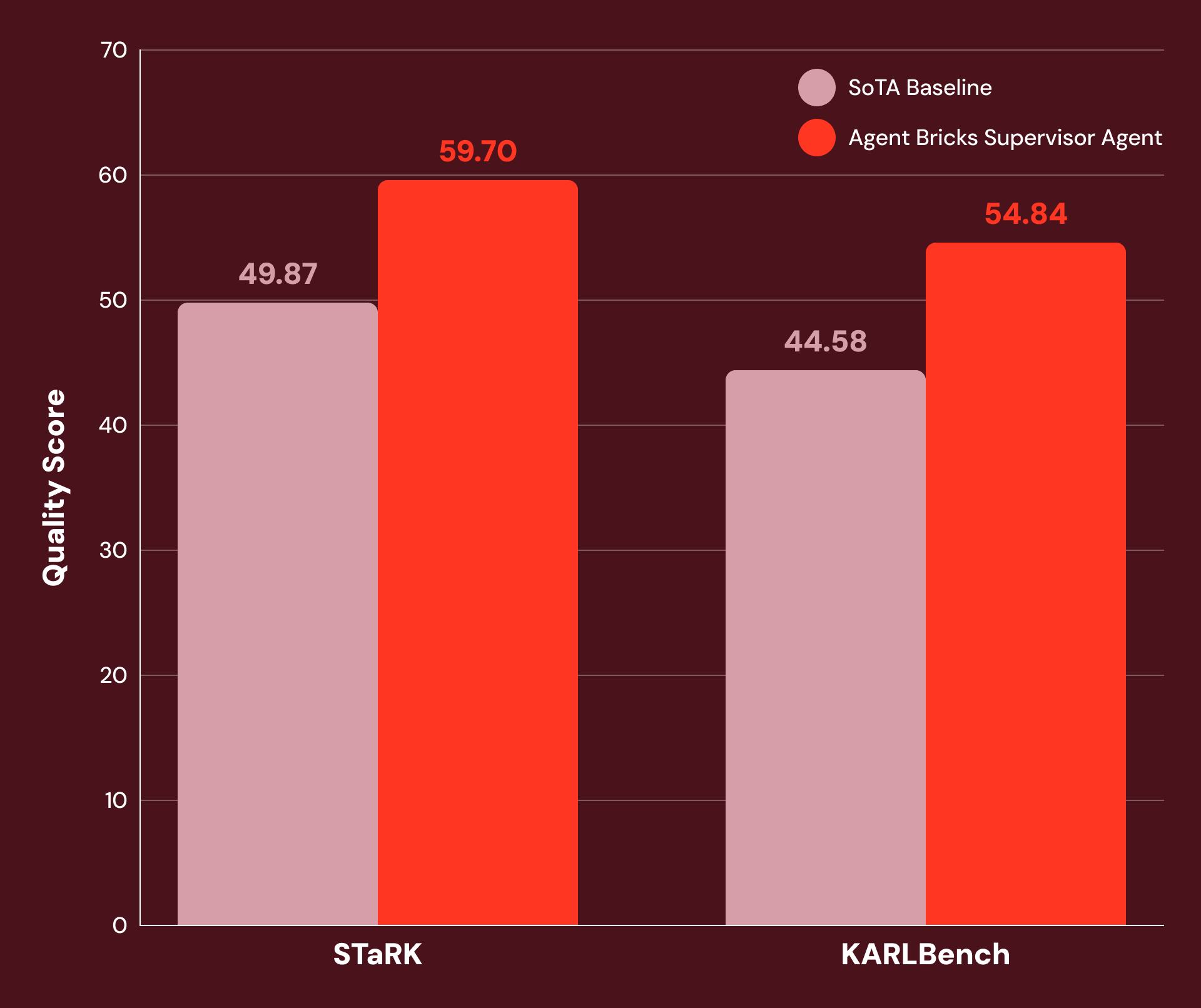
With tuned directions and cautious software configuration, we discover SA to be extremely performant on a variety of knowledge-intensive enterprise duties. Determine 1 exhibits that SA achieves 20% or extra enchancment over SoTA baselines on:
- STaRK: a set of three semi-structured retrieval duties printed by Stanford researchers.
- KARLBench: a benchmark suite for advanced grounded reasoning not too long ago printed by Databricks.
Supervisor Agent demonstrates important features on a variety of economically useful duties: from educational retrieval (+21% on STaRK-MAG) to biomedical reasoning (+38% on STaRK Prime) and monetary evaluation (+23% on FinanceBench).
Agent Setup
Agent Bricks Supervisor Agent is a declarative agent builder that orchestrates brokers and instruments. It’s constructed on aroll — an inner agentic framework for constructing, evaluating, and deploying multi-step LLM workflows at scale.1 aroll and SA had been particularly designed for the superior agentic use instances our prospects ceaselessly encounter.
aroll permits including new instruments and customized directions by means of easy configuration modifications, can deal with 1000’s of concurrent conversations and parallel software executions, and incorporates superior agent orchestration and context administration strategies to refine queries and get better from partial solutions. All of those are tough to realize with SoTA single-turn techniques immediately.
As a result of SA is constructed on this versatile structure, its high quality will be frequently improved by means of easy person curation, resembling tweaking top-level directions or refining agent descriptions, with no need to put in writing any customized code.
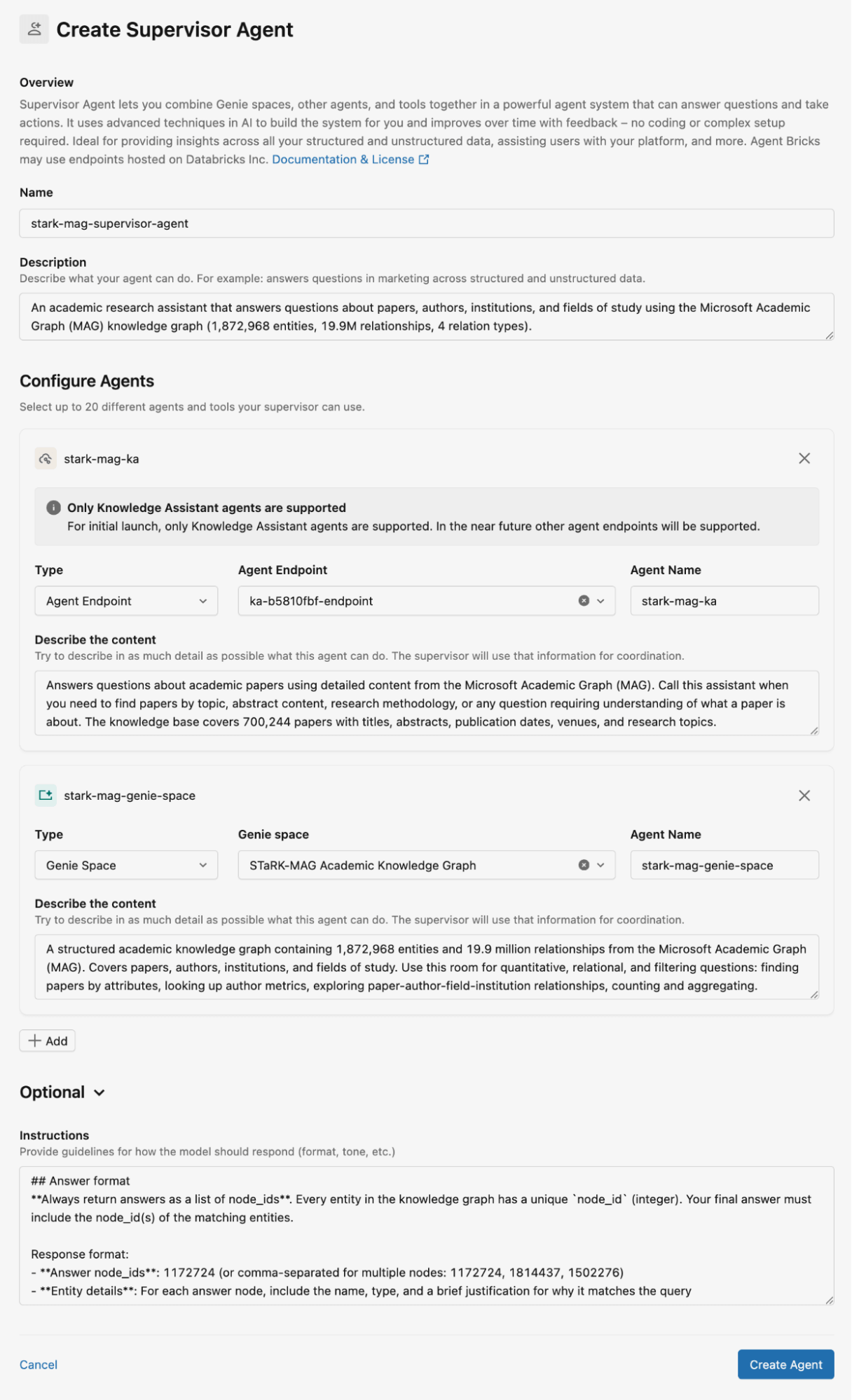
Determine 2 exhibits how we configured the Supervisor Agent for the STaRK-MAG dataset. On this weblog, we use Genie areas for storing the relational information bases and Data Assistants for storing unstructured paperwork for retrieval. We offer detailed descriptions for all Data Assistants and Genie areas, in addition to directions for the agent responses.
Hybrid Reasoning: Structured Meets Unstructured
To guage grounded reasoning primarily based on a hybrid of structured and unstructured information, we use the STaRK benchmark, which incorporates three domains:
- Amazon: product attributes (structured) and evaluations (unstructured)
- MAG: quotation networks (structured) and educational papers (unstructured)
- Prime: biomedical entities (structured) and literature (unstructured)
For instance, “Discover me a paper written by a co-author with 115 papers and is in regards to the Rydberg atom” requires the system to mix structured filtering (“co-author with 115 papers”) with unstructured understanding (“in regards to the Rydberg atom”). The finest printed baselines use vector similarity search with an LLM-based reranker — a powerful single-turn strategy, however one that can’t decompose queries throughout information varieties. To make sure a good comparability, we reran this baseline with the present SoTA foundational mannequin, offering a considerably stronger baseline.
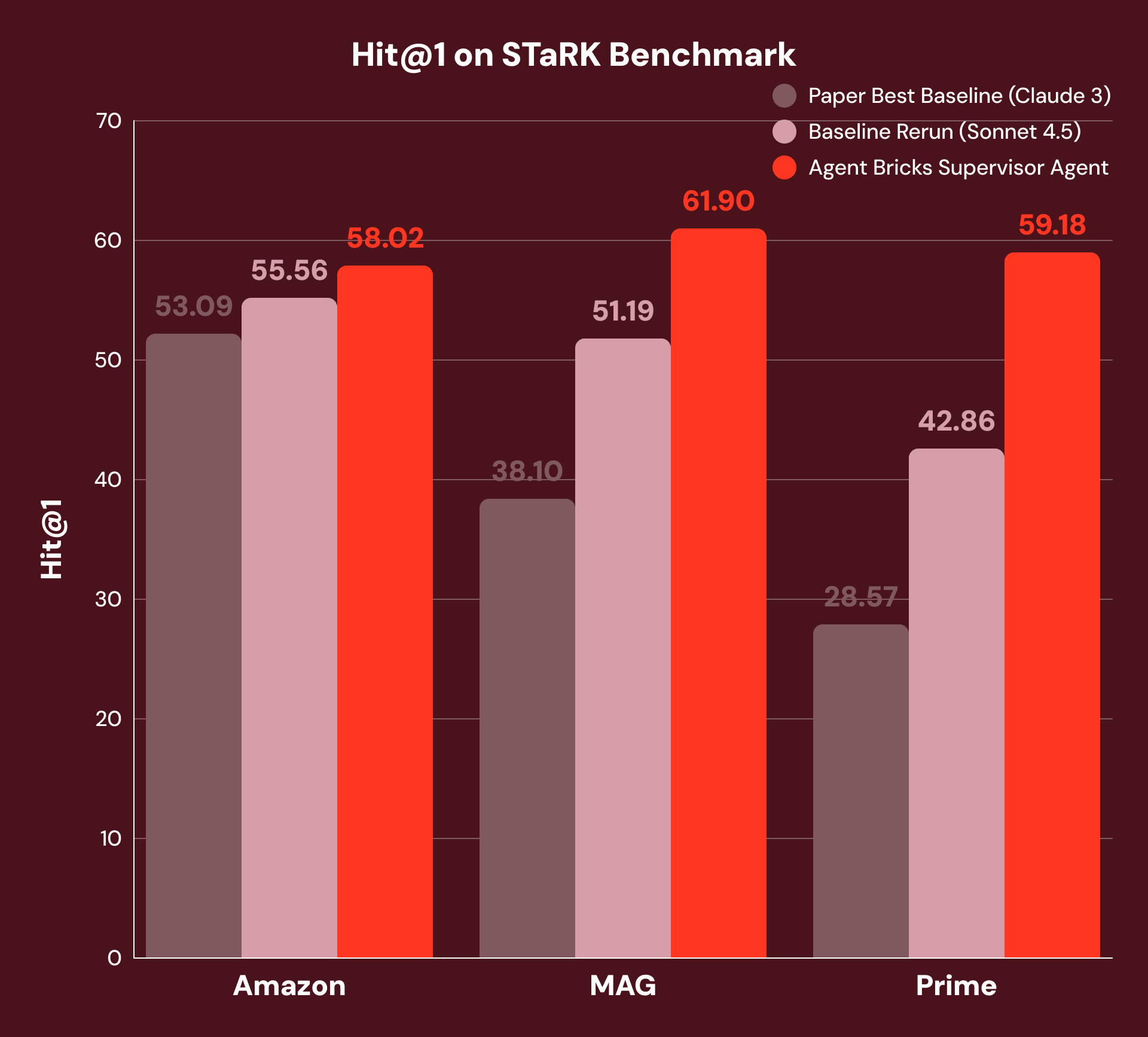
With our strategy, SA decomposes every query, routes sub-questions to the suitable software, and synthesizes outcomes throughout a number of reasoning steps. As Determine 3 exhibits, this achieves +4% Hit@1 on Amazon, +21% on MAG, and +38% on Prime over each the perfect of the unique baselines and our rerun baselines with the present SoTA foundational mannequin. We see the perfect enhancements in MAG and Prime the place the reply requires the tightest integration of structured and unstructured information.
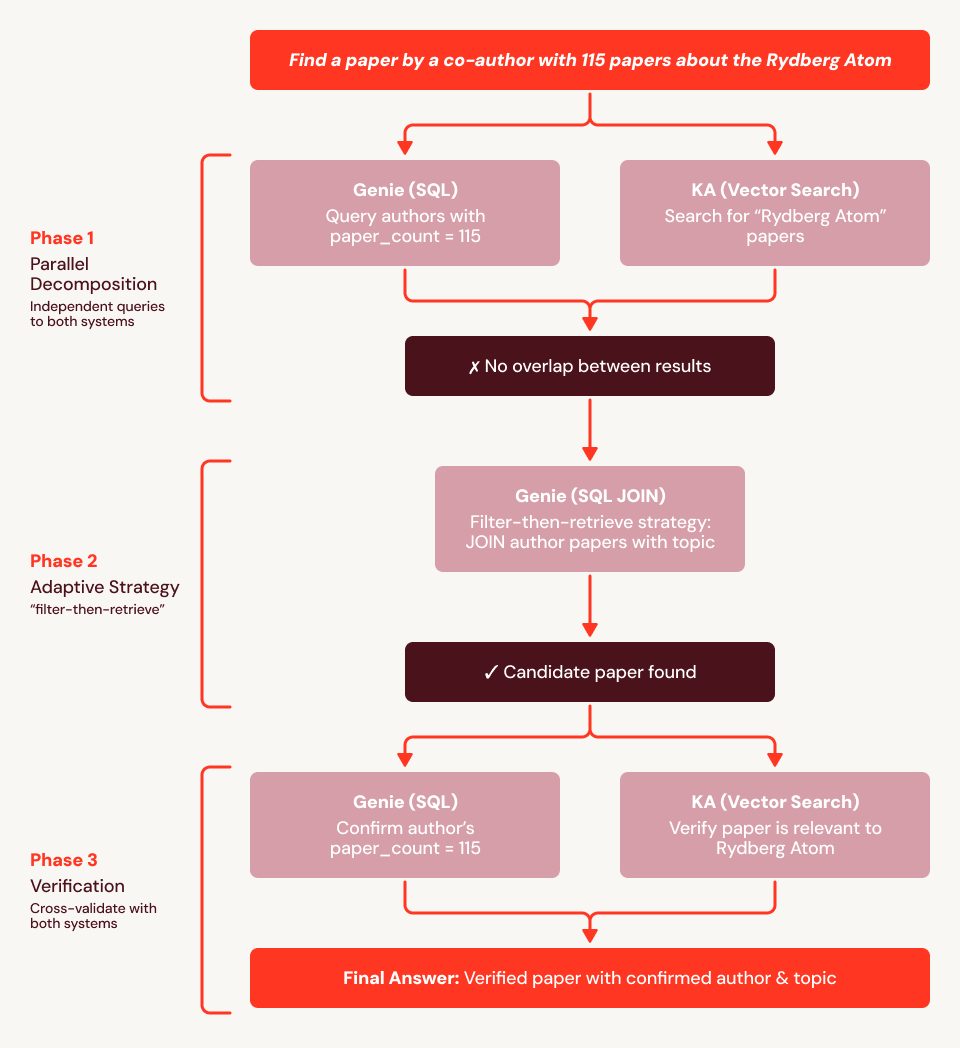
Utilizing our instance query from above (“Discover me a paper written by a co-author with 115 papers and is in regards to the Rydberg atom”), we discover the baseline fails as a result of the embeddings can’t encode the structural constraint (“co-author has precisely 115 papers”). In Determine 4, we present an execution hint for SA: it first makes use of Genie to seek out all 759 authors with 115 papers and Data Assistant to retrieve Rydberg papers, then cross-references the 2 units. When no overlap is discovered, SA adapts: it points a SQL JOIN of the 115-paper creator checklist towards all papers mentioning “Rydberg” within the title or summary, surfacing the reply instantly from the structured information. It then calls Data Assistant to confirm relevance and Genie to verify the creator’s paper depend, and efficiently returns the right paper.
The Agentic Benefit on Data-Intensive Duties
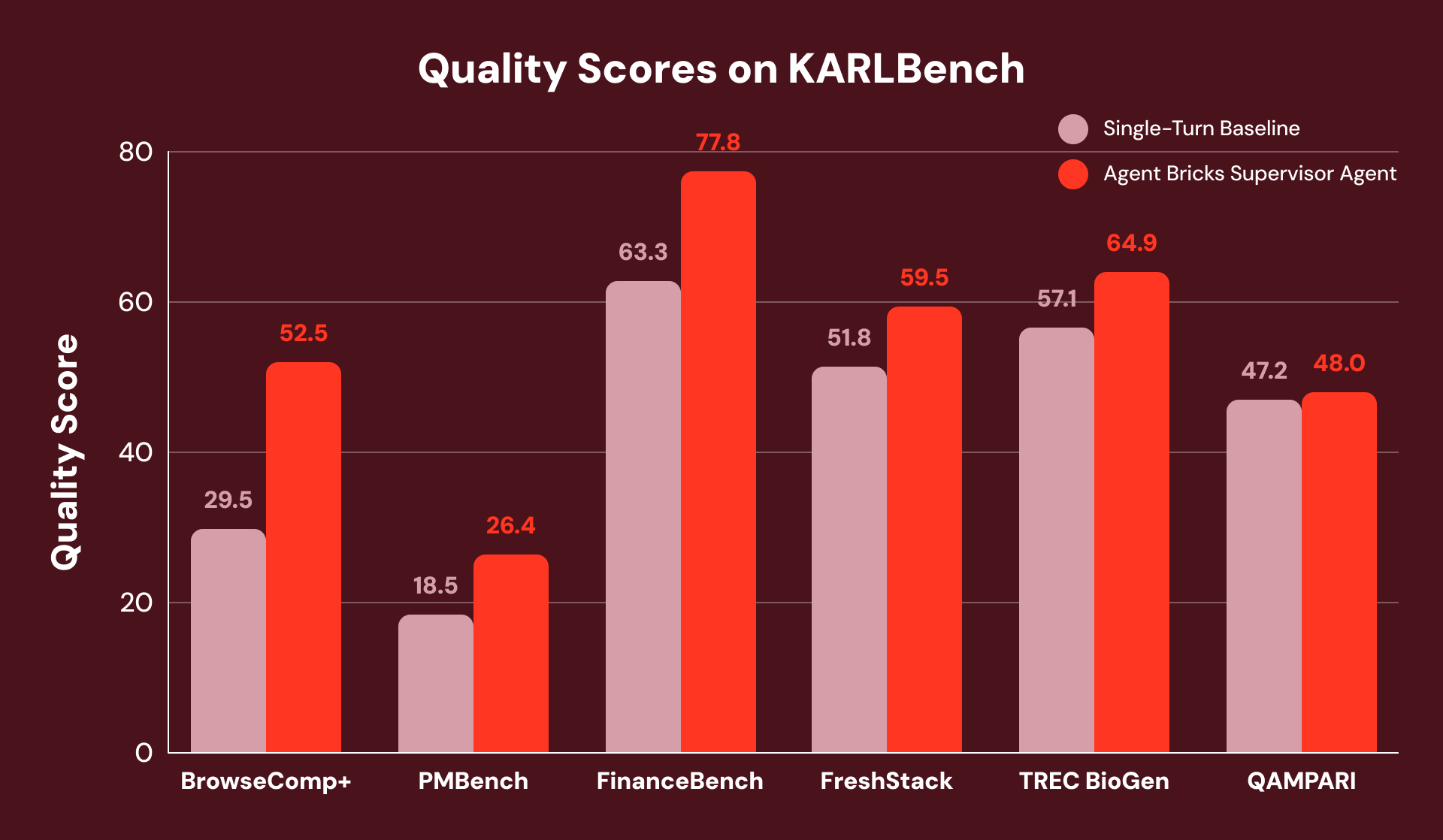
To check the efficiency of Agent Bricks SA with a powerful single-turn baseline (just like the perfect printed baseline for STaRK) the place no structured information is required, we consider them utilizing KARLBench, a grounded reasoning benchmark suite that collectively stress-tests totally different retrieval and reasoning capabilities:
- BrowseComp+: process-of-elimination entity search
- TREC BioGen: biomedical literature synthesis
- FinanceBench: numerical reasoning over monetary filings
- QAMPARI: exhaustive entity recall
- FreshStack: technical troubleshooting over documentation
- PMBench: Databricks inner enterprise doc comprehension
Total, the Supervisor Agent achieves constant features throughout all six benchmarks, with the biggest enhancements on duties that demand both exhaustive evaluation or self-correction. On FinanceBench, it recovers from initially incomplete retrieval by detecting gaps and reformulating queries, yielding general +23% enchancment.
For instance, BrowseComp+’s questions every have 5-10 interlocking constraints, like “Discover a participant who left a Russian membership (2015-2020), naturalized European (2010-2016), top 1.95-2.06m. What was their block success charge on the COVID-postponed Olympics?” The only-turn baseline points one broad question that accurately identifies the participant however fails to floor granular statistics paperwork and fails the query.
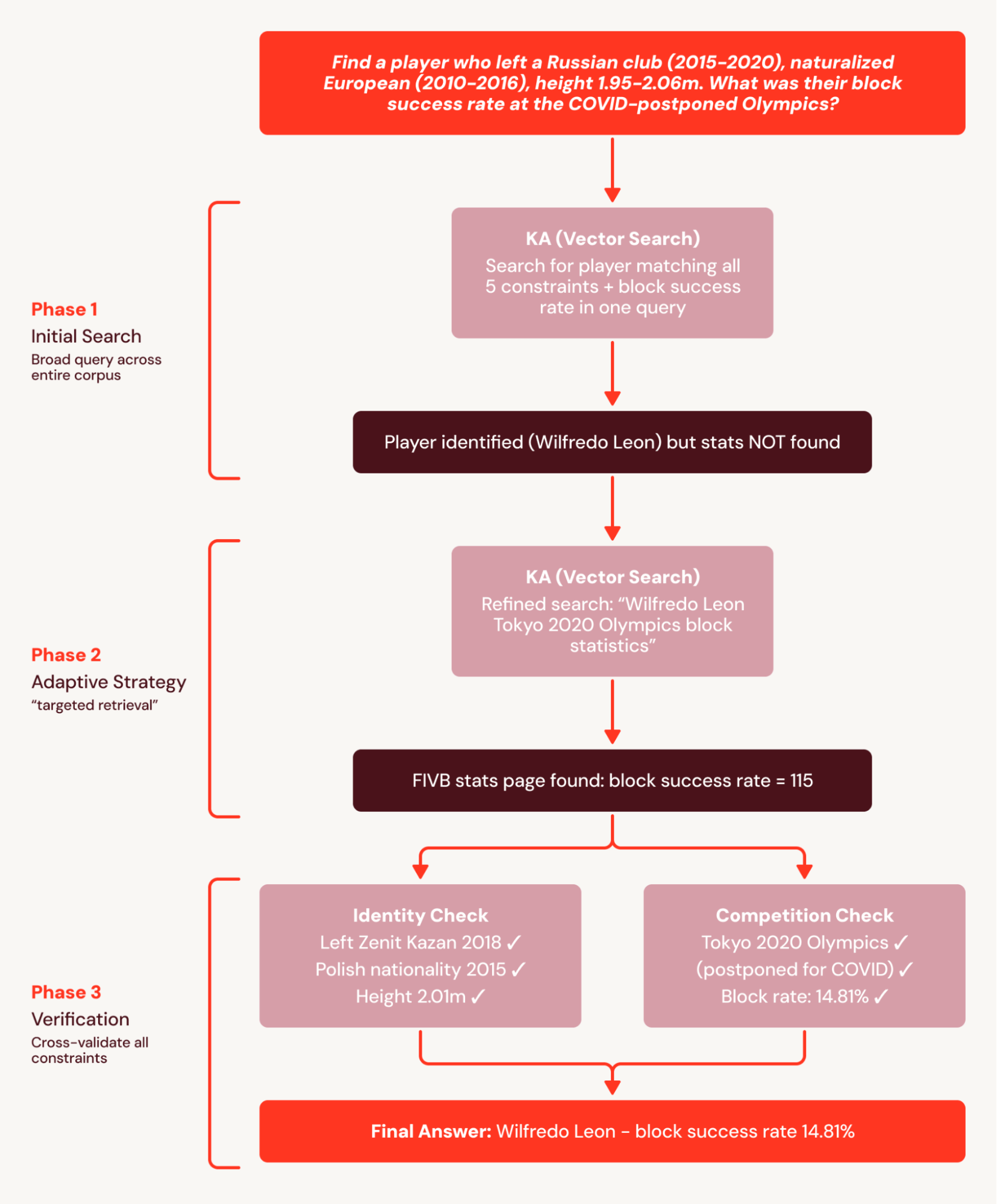
SA breaks this process right into a coordinated search plan and decomposes the plan into searchable subsets. This avoids the single-turn baseline failure the place stats aren’t discovered as a result of they’re retrieved in a subsequent search. In consequence, SA achieves a +78% relative enchancment.
In one other instance from PMBench, one of many questions is “what are the guardrail varieties prospects are utilizing” which requires 26 nuggets (see definition in KARL report) throughout 10+ buyer dialog paperwork for an exhaustive reply. Single-turn baseline finds just one buyer point out as a result of it can’t search throughout each guardrail class in a single query. SA searches every guardrail class individually (“PII detection,” “hallucination,” “toxicity,” “immediate injection”), and incrementally surfaces increasingly more buyer mentions within the course of.
What We Discovered
The outcomes throughout our experiments level to a couple key takeaways:
- Grounded reasoning brokers can profit from a hybrid of structured and unstructured information retrieval if given entry to the correct instruments and information representations.
- For prime-quality retrieval eventualities, constructing customized RAG pipelines over heterogeneous datasets must be prevented, even when SoTA fashions are used for the re-ranking stage. Multi-step reasoning the place, at every step, the agent selects the correct information supply and displays on its utility, is essential for upleveling efficiency.
- A declarative strategy to agent constructing such because the one applied by the Databricks Supervisor Agent offers a superb trade-off between ease of use and high quality.
We use the Databricks Supervisor Agent to construct brokers for all three STaRK domains and 6 unstructured datasets in KARLBench. The one issues that differ throughout these 9 duties are the directions and instruments — no customized code was required to course of these numerous datasets. Thus, constructing a performant agent for a brand new enterprise process is essentially a matter of writing exact directions and equipping it with the correct instruments, fairly than constructing a brand new system from scratch.
Agent Bricks Supervisor Agent is obtainable to all our prospects. You may get began with Agent Bricks SA just by creating an agent and connecting it to your present brokers, instruments and MCP servers. Discover the documentation to see how Supervisor Agent suits into your manufacturing workflows.
Authors: Xinglin Zhao, Arnav Singhvi, Mark Rizkallah, Jonathan Li, Jacob Portes, Elise Gonzales, Sabhya Chhabria, Kevin Wang, Yu Gong, Moonsoo Lee, Michael Bendersky and Matei Zaharia.
1See our current publication “KARL: Data Brokers through Reinforcement Studying” for extra particulars how aroll is used for artificial information era, scalable RL coaching and on-line inference for agentic process.