Introduction
Within the Databricks intelligence platform, we repeatedly discover and use new AI strategies to enhance engine efficiency and simplify the consumer expertise. Right here we current experimental outcomes on making use of frontier fashions to one of many oldest database challenges: be a part of ordering.
This weblog is a part of a analysis collaboration with UPenn.
The Drawback: Be a part of Ordering
Since their inception, question optimizers in relational databases have struggled to seek out good be a part of orderings for SQL queries. For example the problem of be a part of ordering, think about the next question:
What number of motion pictures have been produced by Sony and starred Scarlett Johansson?
Suppose we need to execute this question over the next schema:
| Desk title | Desk columns |
|---|---|
| Actor | actorID, actorName, actorDOB, … |
| Firm | companyID, companyName, … |
| Stars | actorID, movieID |
| Produces | companyID, movieID |
| Film | movieID, movieName, movieYear , … |
The Actor, Firm, and Film entity tables are related by way of the Produces and Stars relationship tables (e.g., by way of international keys). A model of this question in SQL may be:
Logically, we need to carry out a easy be a part of operation: Actor ⋈ Stars ⋈ Film ⋈ Produces ⋈ Firm. However bodily, since every of those joins are commutative and associative, we’ve got loads of choices. The question optimizer might select to:
- First discover all motion pictures starring Scarlett Johansson, then filter out for simply the flicks produced by Sony,
- First discover all motion pictures produced by Sony, then filter out these motion pictures starring Scarlett Johansson,
- In parallel, compute Sony motion pictures and Scarlett Johansson motion pictures, then take the intersection.
Which plan is perfect will depend on the information: if Scarlett Johansson has starred in considerably fewer motion pictures than Sony has produced, the primary plan may be optimum. Sadly, estimating this amount is as troublesome as executing the question itself (on the whole). Even worse, there are usually excess of 3 plans to select from, because the variety of attainable plans grows exponentially with the variety of tables — and analytics queries repeatedly be a part of 20-30 totally different tables.
How does be a part of ordering work in the present day? Conventional question optimizers remedy this drawback with three parts: a cardinality estimator designed to rapidly guess the dimensions of subqueries (e.g., to guess what number of motion pictures Sony has produced), a value mannequin to match totally different potential plans, and a search process that navigates the exponentially-large house. Cardinality estimation is particularly troublesome, and has led to a variety of analysis looking for to enhance estimation accuracy utilizing a variety of approaches [A].
All of those options add vital complexity to a question optimizer, and require vital engineering effort to combine, keep, and productionize. However what if LLM-powered brokers, with their skills to adapt to new domains with prompting, maintain the important thing to fixing this decades-old drawback?
Agentic be a part of ordering
When question optimizers choose a nasty be a part of ordering1, human consultants can repair it by diagnosing the difficulty (usually a misestimated cardinality), and instructing the question optimizer to decide on a distinct ordering. This course of usually requires a number of rounds of testing (e.g., executing the question) and manually inspecting the middleman outcomes.
Question optimizers usually want to select be a part of orders in a couple of hundred milliseconds, so integrating an LLM into the recent path of the question optimizer, whereas doubtlessly promising, shouldn’t be attainable in the present day. However, the iterative and handbook means of optimizing the be a part of order for a question, which could take a human knowledgeable a number of hours, might doubtlessly be automated with an LLM agent! This agent tries to automate that handbook tuning course of.
To check this, we developed a prototype question optimization agent. The agent has entry to a single device, which executes a possible be a part of order for a question and returns the runtime of the be a part of order (with a timeout of the unique question’s runtime) and the dimensions of every computed subplan (e.g., the EXPLAIN EXTENDED plan).
We let the agent run for 50 iterations, permitting the agent to freely check out totally different be a part of orders. The agent is free to make use of these 50 iterations to check out promising plans (“exploitation”), or to discover risky-but-informative options (“exploration”). Afterwards, we acquire the perfect performing be a part of order examined by the agent, which turns into our ultimate outcome. However how do we all know the agent picked a legitimate be a part of order? To make sure correctness, every device name generates a be a part of ordering utilizing structured mannequin outputs, which forces the mannequin’s output to match a grammar we specify to solely admit legitimate be a part of reorderings. Word that this differs from prior work [B] that asks the LLM to select a be a part of order immediately within the “sizzling path” of the question optimizer; as a substitute, the LLM will get to behave like an offline experimenter that tries many candidate plans and learns from the noticed outcomes – identical to a human tuning a be a part of order by hand!.
To judge our agent in DBR, we used the Be a part of Order Benchmark (JOB), a set of queries that have been designed to be troublesome to optimize. Because the dataset utilized by JOB, the IMDb dataset, is barely round 2GB (and subsequently Databricks might course of even poor be a part of orderings pretty rapidly), we scaled up the dataset by duplicating every row 10 occasions [C].
We let our agent check 15 be a part of orders (rollouts) per question for all 113 queries within the be a part of order benchmark. We report outcomes on the perfect be a part of order discovered for every question. When utilizing a frontier mannequin, the agent was in a position to enhance question latency by an element of 1.288 (geomean). This outperforms utilizing good cardinality estimates (intractable in apply), smaller fashions, and the latest BayesQO offline optimizer (though BayesQO was designed for PostgreSQL, not Databricks).
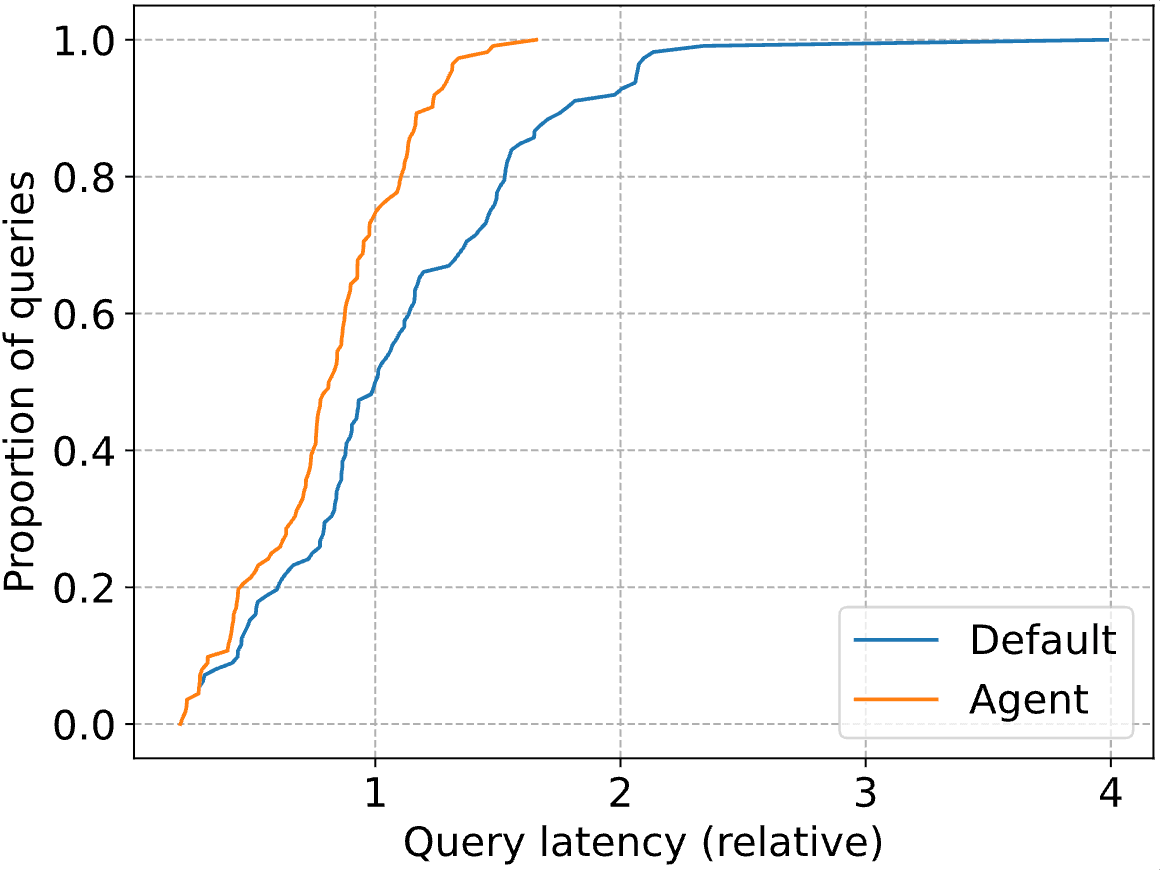
The true spectacular positive factors are within the tail of the distribution, with the P90 question latency dropping by 41%. Beneath, we plot the whole CDF for each the usual Databricks optimizer (”Default”) and our agent (”Agent). Question latencies are normalized to the median latency of the Databricks optimizer (i.e., at 1, the blue line reaches a proportion of 0.5).
Our agent progressively improves the workload with every examined plan (generally known as a rollout), making a easy “anytime algorithm” the place bigger time budgets might be translated into additional question efficiency. After all, ultimately question efficiency will cease enhancing.
One of many largest enhancements our agent discovered was in question 5b, a easy 5-way be a part of which appears to be like for American manufacturing corporations that launched a post-2010 film on VHS with a observe referencing 1994. The Databricks optimizer targeted first on discovering American VHS manufacturing corporations (which is certainly selective, producing solely 12 rows). The agent finds a plan that first appears to be like for VHS releases referencing 1994, which seems to be considerably sooner. It is because the question makes use of LIKE predicates to determine VHS releases, that are exceptionally troublesome for cardinality estimators.
Our prototype demonstrates the promise of agentic techniques autonomously repairing and enhancing database queries. This train raised a number of questions on agent design in our minds:
- What instruments ought to we give the agent? In our present strategy, the agent can execute candidate be a part of orders. Why not let the agent difficulty particular cardinality queries (e.g., compute the dimensions of a specific subplan), or queries to check sure assumptions in regards to the information (e.g., to find out that there have been no DVD releases previous to 1995).
- When ought to this agentic optimization be triggered? Certainly, a consumer can flag a problematic question manually for intervention. However might we additionally proactively apply this optimization to regularly-running queries? How can we decide if a question has “potential” for optimization?
- Can we robotically perceive enhancements? When the agent finds a greater be a part of order than the one discovered by the default optimizer, this be a part of order might be considered as a proof that the default optimizer is selecting a suboptimal order. If the agent corrects a scientific error within the underlying optimizer, can we uncover this and use it to enhance the optimizer?
After all, we’re not the one ones excited about the potential of LLMs for question optimization [D]. At Databricks, we’re enthusiastic about the opportunity of harnessing the generalizability of LLMs to enhance information techniques themselves.
If you’re on this subject, see additionally our followup UCB weblog on “How do LLM brokers suppose via SQL be a part of orders?“.
Be a part of Us
As we glance forward, we’re excited to maintain pushing the boundaries of how AI can form database optimizations. When you’re obsessed with constructing the following technology of database engines, be a part of us!
1 Databricks use strategies like runtime filters to mitigate the influence of poor be a part of orders. The outcomes offered right here embody these strategies.
Notes
A. Methods for cardinality estimation have included, for instance, adaptive suggestions, deep studying, distribution modeling, database principle, studying principle, and issue decompositions. Prior work has additionally tried to completely change the normal question optimizer structure with deep reinforcement studying, multi-armed bandits, Bayesian optimization, or extra superior be a part of algorithms.
B. RAG-based approaches, for instance, have been used to construct “LLM within the sizzling path” techniques.
C. Whereas crude, this strategy has been utilized in prior work.
D. Different researchers have proposed RAG-based question restore techniques, LLM-powered question rewrite techniques, and even whole database techniques synthesized by LLMs.