Trendy knowledge pipelines deal with huge volumes of structured and unstructured knowledge day by day. As datasets develop, poorly optimized Spark jobs change into slower, dearer, and tougher to scale. Frequent points embrace lengthy execution instances, extreme shuffling, reminiscence bottlenecks, and inefficient joins.
Efficient PySpark optimization can considerably enhance efficiency, scale back infrastructure prices, and improve cluster effectivity. On this article, we’ll discover 12 confirmed PySpark optimization methods with sensible examples and real-world efficiency methods utilized by knowledge engineers.
How Spark Executes Your Code
It’s essential to learn the way Spark executes your code earlier than you begin your optimization work. Builders write PySpark code with out understanding the underlying processes which energy their code. The absence of data leads to suboptimal efficiency choices. The core mechanics of this part allow readers to grasp each optimization approach which follows.
Understanding Spark Structure
Spark operates its distributed system which allows simultaneous knowledge processing throughout varied computer systems. Each Spark utility consists of two main elements which function in unison.
- Driver vs Executors
The Driver serves because the central command system on your Spark utility. It executes your most important program whereas creating the execution technique and supervising all operational actions. The Executors operate because the operational workers. The cluster distributes these staff to varied machines which retailer knowledge in reminiscence whereas conducting precise computational duties.
The Driver divides the work into smaller duties which it dispatches to Executors whenever you submit a Spark job. Every Executor operates on its designated knowledge phase with none dependencies on different methods. The mixture of parallel processing strategies allows Spark to ship high-speed efficiency.
- Jobs, Levels, and Duties
Spark organizes your computation work into three hierarchical layers.
- Job: An entire computation triggered by an motion (like
rely()orwrite()). - Stage: A set of duties that may run with out shuffling knowledge throughout the community.
- Activity: The smallest unit of labor. Every process processes one partition of information.
You could find efficiency issues within the Spark UI by utilizing this hierarchical construction to find varied system elements.
Lazy Analysis in Spark
The Spark framework is not going to execute your transformations in the intervening time you create them. The system information your supposed actions whenever you use the filter() and choose() and groupBy() features. The system creates a logical construction to signify your supposed actions. The system requires you to carry out an motion which incorporates present() and rely() and write() to provoke the execution course of.
Lazy analysis describes this sample of operation. The system allows Spark to design a complete question plan which it’ll execute in any case planning is completed. Earlier than any work begins Spark can change the order of duties and transfer knowledge supply filters nearer and take away unneeded elements.
Understanding Spark Transformations and Actions
All PySpark operations fall into two classes.
- Transformations: Transformations create new DataFrames by their execution of lazy operations. The features
filter(),choose(),be part of(),groupBy(), andwithColumn()create new DataFrames by their execution of lazy operations. Spark information these however doesn’t run them but. - Actions: Precise execution begins when actions are carried out. The features
rely(),gather(),present(),write(), andfirst()function examples of this conduct. Once you name an motion, Spark evaluates all of the queued transformations and runs the job.
A typical mistake happens when individuals execute a number of actions on the identical DataFrame without having them. The system executes all transformations once more for each motion except you utilize knowledge caching.
Studying Spark Execution Plans with clarify()
The clarify() methodology is your debugging instrument. The system shows its full question execution plan by this characteristic. The system means that you can observe two features of the operation as a result of it exhibits filter pushdown outcomes and broadcast be part of utilization and shuffle operation particulars.
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("ExplainDemo").getOrCreate()
df = spark.learn.parquet("/knowledge/gross sales.parquet")
df_filtered = df.filter(df["revenue"] > 5000).choose("product", "income")
# Learn the execution plan
df_filtered.clarify(True)Output:
== Parsed Logical Plan ==
'Undertaking ['product,'revenue]
+- 'Filter ('income > 5000)
+- Relation[...] parquet== Analyzed Logical Plan ==
...== Optimized Logical Plan ==
Undertaking [product#10,revenue#11]
+- Filter (isnotnull(income#11) AND (income#11 > 5000))
+- Relation[...] parquet== Bodily Plan ==
*(1) Undertaking [product#10,revenue#11]
+- *(1) Filter (isnotnull(income#11) AND (income#11 > 5000))
+- *(1) FileScan parquet [...] PushedFilters:[IsNotNull(revenue),GreaterThan(revenue,5000.0)]
You’ll be able to see PushedFilters current within the output. The filter applies on the file degree which serves as a wonderful efficiency indicator.
Methods to Optimise Your Spark Fashions
Now, we’ll undergo the methods that may assist to optimize your spark fashions.
Approach 1: Use Columnar File Codecs Like Parquet or ORC
The file format you choose leads to important results on Spark’s means to learn knowledge. Groups desire CSV and JSON as their commonplace codecs as a result of these codecs require minimal effort to provide. The usage of these codecs causes main efficiency points when operations attain their most limits.
Why CSV and JSON Are Slower
CSV and JSON are row-based codecs. To learn a single column, Spark should learn each row and parse all columns. This wastes I/O and CPU time. Additionally they don’t have any built-in schema, so Spark should infer it which provides further overhead.
Advantages of Parquet and ORC
Parquet and ORC operate as column-based knowledge codecs which help analytical operations. The system organizes knowledge storage based on columns as an alternative of storing knowledge based on rows.
- Columnar Storage: Columnar Storage permits Spark to entry solely the precise columns which you require. Once you select 3 columns from a dataset containing 50 columns Spark will exclude 47 columns from the processing.
- Compression Advantages: Columnar codecs obtain superior knowledge compression outcomes by utilizing their columnar storage construction. The compression course of works successfully as a result of comparable values inside a single column keep proximity. The system achieves storage price reductions whereas accelerating studying instances.
- Predicate Pushdown: Parquet and ORC keep statistical info (minimal and most values and null counts) for each column throughout all row teams. Spark makes use of these statistics to skip total chunks of information with out studying them.
PySpark Code Instance
from pyspark.sql import SparkSession
from pyspark.sql.sorts import (
StructType,
StructField,
StringType,
IntegerType,
DoubleType
)
spark = SparkSession.builder.appName("FileFormatDemo").getOrCreate()
# Create dummy gross sales knowledge
knowledge = [
("P001", "Laptop", "Electronics", 1200.50, 30),
("P002", "Phone", "Electronics", 800.00, 75),
("P003", "Desk", "Furniture", 350.00, 20),
("P004", "Chair", "Furniture", 200.00, 50),
("P005", "Monitor", "Electronics", 450.75, 40),
("P006", "Keyboard", "Electronics", 80.00, 100),
("P007", "Lamp", "Furniture", 60.00, 60),
("P008", "Tablet", "Electronics", 600.00, 25),
]
schema = StructType([
StructField("product_id", StringType(), True),
StructField("product_name", StringType(), True),
StructField("category", StringType(), True),
StructField("price", DoubleType(), True),
StructField("units_sold", IntegerType(), True),
])
df = spark.createDataFrame(knowledge, schema)
# Write as CSV (sluggish format)
df.write.mode("overwrite").csv("/tmp/sales_csv")
# Write as Parquet (quick columnar format)
df.write.mode("overwrite").parquet("/tmp/sales_parquet")
# Learn again Parquet — quick, schema-aware
df_parquet = spark.learn.parquet("/tmp/sales_parquet")
df_parquet.choose("product_name", "value").present()Output:
Finest Practices for File Codecs
- Use Parquet for analytical workloads and pipelines.
- Use ORC when working with Hive or HBase ecosystems.
- At all times write with Snappy compression for a great steadiness of velocity and dimension.
- Keep away from CSV and JSON for intermediate storage between pipeline steps.
Approach 2: Filter Information as Early as Doable
The best and only PySpark optimization methodology entails performing early knowledge filtering. The velocity of your total system improves when Spark processes a smaller quantity of information all through your total pipeline.
What Is Predicate Pushdown?
A predicate is a filter situation that features each age > 30 and standing == "lively". Predicate pushdown means Spark strikes these filter circumstances as near the info supply as attainable, ideally into the file scan itself. Spark performs its studying course of by making use of filters as an alternative of retrieving all knowledge for subsequent filtering.
Why Early Filtering Improves Efficiency
The operation of filtering earlier than processing allows all subsequent duties to work with a smaller knowledge set which incorporates joins and aggregations and kinds. The method leads to decreased reminiscence necessities and lowered community calls for and shorter CPU processing instances for every stage of your venture.
PySpark Code Instance
from pyspark.sql import SparkSession
from pyspark.sql.features import col
spark = SparkSession.builder.appName("EarlyFilterDemo").getOrCreate()
# Dummy worker knowledge
knowledge = [
(1, "Alice", "Engineering", 95000, "active"),
(2, "Bob", "Marketing", 72000, "inactive"),
(3, "Charlie", "Engineering", 110000, "active"),
(4, "Diana", "HR", 65000, "active"),
(5, "Eve", "Engineering", 88000, "inactive"),
(6, "Frank", "Marketing", 78000, "active"),
(7, "Grace", "HR", 70000, "active"),
(8, "Hank", "Engineering", 120000, "active"),
]
schema = ["emp_id", "name", "department", "salary", "status"]
df = spark.createDataFrame(knowledge, schema)
# BAD: Filter late after be part of and aggregation
df_bad = (
df.groupBy("division")
.sum("wage")
.filter(col("sum(wage)") > 200000)
)
# GOOD: Filter early earlier than aggregation
df_good = (
df.filter(
(col("standing") == "lively") &
(col("wage") > 70000)
)
.groupBy("division")
.sum("wage")
)
df_good.present()Output:
Verifying Optimization Utilizing clarify()
df_good.clarify() Output:

Frequent Filtering Errors
- The system operates by its checking course of which executes after the becoming a member of operation.
- The method must execute knowledge assortment by
gather()which brings knowledge to Python earlier than customers begin their knowledge filtering work by Python loops. - The system permits for filters on calculated columns when customers ought to first apply filters on unique supply columns.
Approach 3: Choose Solely Required Columns
Studying pointless columns wastes I/O time and reminiscence. Many builders write choose("*") out of behavior however this observe causes your Spark jobs to undergo efficiency issues when working on extensive datasets.
The Downside with Huge DataFrames
A large DataFrame has many columns which may attain a whole lot in precise knowledge warehouse environments. The 200 columns have to be loaded as a result of your evaluation wants to make use of solely 5 of them.
Why choose(“*”) Hurts Efficiency
choose("*") forces Spark to learn all columns whereas it processes your job by its completely different phases. Spark can eradicate total columns from its processing whenever you select particular knowledge parts by columnar codecs corresponding to Parquet.
Column Pruning in Spark
Column pruning is the method of eliminating unused columns from the question plan. Spark’s Catalyst optimizer performs column pruning mechanically whenever you use express choose() statements. The system fully avoids studying these columns from the supply.
PySpark Code Instance
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("ColumnPruningDemo").getOrCreate()
# Huge dummy dataset
knowledge = [
("E001", "Alice", 30, "F", "Engineering", 95000, "New York", "[email protected]", "2018-05-10", "lively"),
("E002", "Bob", 35, "M", "Advertising and marketing", 72000, "Chicago", "[email protected]", "2019-03-15", "inactive"),
("E003", "Charlie", 28, "M", "Engineering", 110000, "San Francisco", "[email protected]", "2020-01-20", "lively"),
("E004", "Diana", 42, "F", "HR", 65000, "Austin", "[email protected]", "2015-07-08", "lively"),
]
schema = [
"emp_id",
"name",
"age",
"gender",
"department",
"salary",
"city",
"email",
"join_date",
"status"
]
df = spark.createDataFrame(knowledge, schema)
# BAD: Learn all columns
df_bad = df.choose("*").filter(df["status"] == "lively")
# GOOD: Choose solely what you want
df_good = (
df.choose("emp_id", "identify", "division", "wage")
.filter(df["status"] == "lively")
)
df_good.present()Output:
How Catalyst Optimizer Helps
The Catalyst optimizer of Spark mechanically removes columns from its bodily plan development course of. The system tracks wanted columns for complicated queries whereas eliminating unneeded ones by its tracing mechanism. The usage of express choose() statements allows Catalyst to carry out its process with higher precision.
Approach 4: Optimize Partitioning
Partitioning is among the most impactful areas of PySpark efficiency. Getting your partition technique incorrect could make even easy jobs run slowly.
Understanding Spark Partitions
A partition features as a DataFrame part which stays accessible by one executor. Spark conducts simultaneous processing of every DataFrame partition. The system achieves elevated processing capability by extra partitions but extreme tiny partitions lead to processing delays. Your cluster features at under its most capability as a result of you will have created excessively massive partitions.
Default Partitioning Habits
Spark establishes knowledge partitions from file enter based mostly on the variety of enter splits. HDFS and S3 methods create one partition for every file block. Spark creates 200 partitions for shuffle operations which embrace groupBy and be part of operations as a result of spark.sql.shuffle.partitions controls this default setting.
The usage of 200 shuffle partitions exceeds necessities for small datasets as a result of it leads to extreme tiny duties. The 200 partition rely may not adequately deal with very massive datasets.
How Partitions Have an effect on Parallelism
Spark permits execution of 1 process for every partition which makes use of one core of the system. Spark begins 20 duties concurrently throughout 10 execution phases when your cluster has 20 cores and your system has 200 partitions. The system requires 10 cores to function since you created 10 partitions.
The usual advice suggests utilizing 2 to 4 partitions for every CPU core current inside your cluster.
repartition() vs coalesce()
The 2 strategies each alter partition counts but their operational processes differ from one another.
- repartition(n): The operate
repartition(n)redistributes knowledge by a whole network-based shuffle operation. You need to use it whenever you need to create extra partitions or whenever you require equal-sized partitions. The method incurs excessive prices as a result of it transmits knowledge by the community system. - coalesce(n): The operate
coalesce(n)achieves partition discount by non-disruptive partition motion. The operate allows partition merging on executors when two partitions exist. You need to use it to lower partitions (for instance, earlier than writing output). The answer prices much less cash to implement but it produces partition sizes which don’t attain equal distribution.
PySpark Code Instance
from pyspark.sql import SparkSession
spark = (
SparkSession.builder
.appName("PartitionDemo")
.config("spark.sql.shuffle.partitions", "10")
.getOrCreate()
)
# Create dummy transaction knowledge
knowledge = [
(
i,
f"TXN{i:05d}",
float(i * 15.5),
"completed" if i % 3 != 0 else "failed"
)
for i in range(1, 101)
]
schema = ["txn_id", "txn_ref", "amount", "status"]
df = spark.createDataFrame(knowledge, schema)
print(f"Preliminary partitions: {df.rdd.getNumPartitions()}")
# Enhance partitions for parallel processing
df_repartitioned = df.repartition(20)
print(
f"After repartition(20): "
f"{df_repartitioned.rdd.getNumPartitions()}"
)
# Cut back partitions earlier than writing output
df_coalesced = df_repartitioned.coalesce(4)
print(
f"After coalesce(4): "
f"{df_coalesced.rdd.getNumPartitions()}"
)
# Repartition by a column for be part of optimization
df_by_status = df.repartition(10, "standing")
df_by_status.groupBy("standing").rely().present()Output:
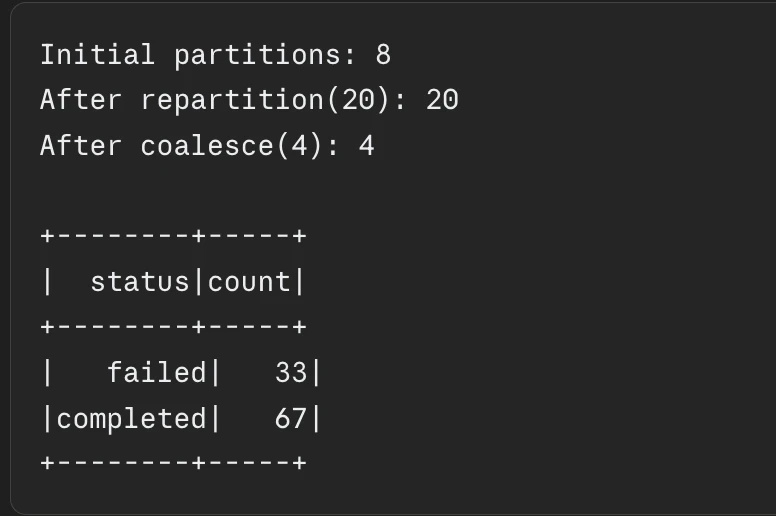
Approach 5: Use Broadcast Joins for Small Tables
Essentially the most resource-intensive operations in Spark methods change into their most costly operations as a result of they should transfer knowledge between completely different community places. A broadcast be part of means that you can take away the necessity for knowledge motion when one desk stays small.
Why Spark Joins Are Costly
The usual Spark be part of requires Each DataFrames to have matching keys on the identical executor. The Spark system achieves this consequence by transferring knowledge by the community which strikes machine rows till their matching keys attain the right location. The method of community knowledge switch incurs each excessive bills and prolonged time delays.
What Is a Broadcast Be a part of?
In a broadcast be part of, Spark sends a full copy of the small desk to each executor. The executors use their native massive desk partitions to carry out the be part of without having to shuffle knowledge between them. This strategy leads to a considerable lower of execution time.
When to Use Broadcast Joins
You need to use a broadcast be part of when one desk exists which could be totally saved within the reminiscence of every executor. Spark mechanically broadcasts tables smaller than spark.sql.autoBroadcastJoinThreshold (default 10 MB). You’ll be able to manually broadcast bigger tables in case your executors have sufficient reminiscence.
PySpark Code Instance
from pyspark.sql import SparkSession
from pyspark.sql.features import broadcast
spark = (
SparkSession.builder
.appName("BroadcastJoinDemo")
.getOrCreate()
)
# Giant truth desk — orders
orders_data = [
(1001, "C01", "P001", 2, 2401.00),
(1002, "C02", "P003", 1, 350.00),
(1003, "C01", "P002", 3, 2400.00),
(1004, "C03", "P001", 1, 1200.50),
(1005, "C02", "P005", 2, 901.50),
(1006, "C04", "P006", 5, 400.00),
(1007, "C03", "P004", 2, 400.00),
(1008, "C01", "P007", 1, 60.00),
]
orders = spark.createDataFrame(
orders_data,
["order_id", "customer_id", "product_id", "qty", "total_amount"]
)
# Small dimension desk — product classes
# (candidate for broadcast)
product_data = [
("P001", "Laptop", "Electronics"),
("P002", "Phone", "Electronics"),
("P003", "Desk", "Furniture"),
("P004", "Chair", "Furniture"),
("P005", "Monitor", "Electronics"),
("P006", "Keyboard", "Electronics"),
("P007", "Lamp", "Furniture"),
]
merchandise = spark.createDataFrame(
product_data,
["product_id", "product_name", "category"]
)
# BAD: Normal be part of (triggers shuffle)
df_standard = orders.be part of(
merchandise,
on="product_id",
how="internal"
)
# GOOD: Broadcast be part of
# (no shuffle for small desk)
df_broadcast = orders.be part of(
broadcast(merchandise),
on="product_id",
how="internal"
)
df_broadcast.choose(
"order_id",
"product_name",
"class",
"total_amount"
).present()Output:
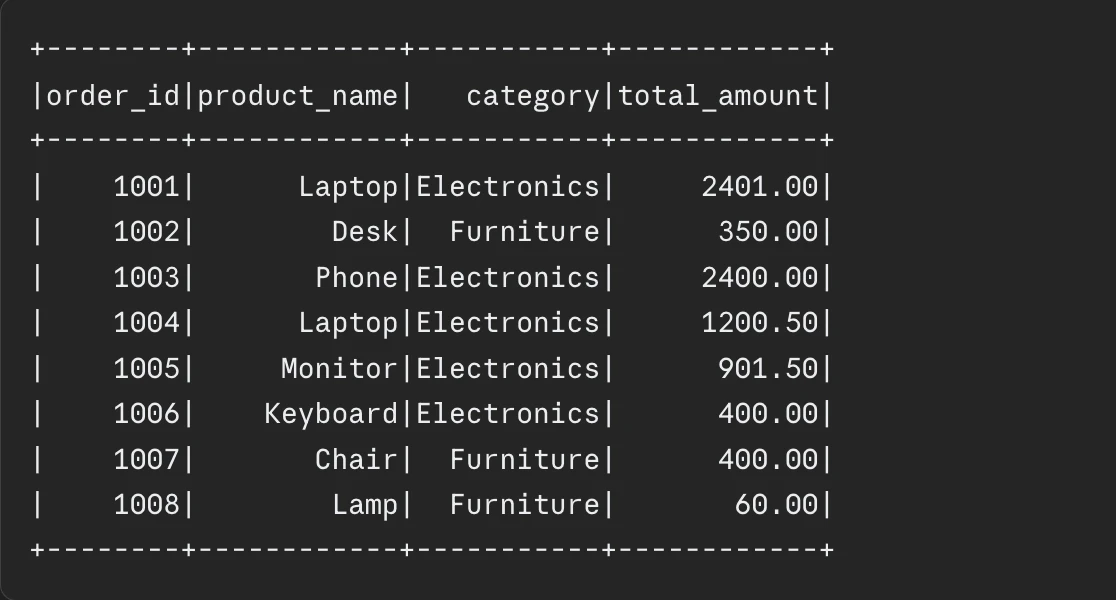
How Broadcast Joins Cut back Shuffle
When Spark sees broadcast(merchandise), it ships your entire merchandise desk to each executor upfront. Every executor retains the desk of their reminiscence storage. The be part of course of runs on each executor which manages its personal orders partition by matching rows with none community knowledge transmission. The consequence produces a be part of course of that completes at a velocity which exceeds regular efficiency.
Approach 6: Allow Adaptive Question Execution (AQE)
The introduction of Adaptive Question Execution (AQE) in Spark model 3.0 introduced probably the most important efficiency increase to Spark between its current time and its final main replace. The system permits Spark to switch your question optimizations throughout execution by utilizing actual knowledge metrics which it obtains by runtime operations.
What Is AQE in Spark?
Spark used to create a whole execution plan which it will comply with all through your entire course of with out making any changes based mostly on precise knowledge. The implementation of AQE allows this performance. The characteristic allows Spark to evaluate execution efficiency by precise knowledge evaluation which it obtains from every shuffle interval.
Runtime Question Optimization with AQE
The system consists of three main features which begin working instantly after customers activate the system.
- Dynamic Be a part of Technique Choice: The system permits AQE to alter its execution methodology from sort-merge be part of to broadcast be part of throughout runtime. Spark mechanically sends one aspect of a be part of to all nodes when it detects that the be part of’s dimension will probably be smaller than predicted after a shuffle operation. This strategy prevents a whole shuffle operation when the desk exceeds the published dimension restrict which base on file dimensions.
- Skew Be a part of Optimization: Uneven knowledge distribution creates knowledge skew as a result of some partitions obtain larger knowledge volumes than different partitions. This example results in one or two sluggish duties which stop your entire job from progressing. The system makes use of AQE to search out runtime skewed partitions which it then divides into smaller components for higher distribution of duties.
- Publish-Shuffle Partition Coalescing: The system permits AQE to mix a number of low quantity shuffle partitions into one bigger partition after finishing the shuffle operation. This course of eliminates the requirement for a number of small duties which carry out minimal features due to their low execution quantity.
PySpark Code Instance
from pyspark.sql import SparkSession
spark = (
SparkSession.builder
.appName("AQEDemo")
.config("spark.sql.adaptive.enabled", "true")
.config("spark.sql.adaptive.coalescePartitions.enabled", "true")
.config("spark.sql.adaptive.skewJoin.enabled", "true")
.config("spark.sql.adaptive.localShuffleReader.enabled", "true")
.getOrCreate()
)
# Dummy gross sales transactions
sales_data = [
(
i,
f"CUST_{i % 50:03d}",
f"PROD_{i % 20:03d}",
float(i * 10.5)
)
for i in range(1, 201)
]
gross sales = spark.createDataFrame(
sales_data,
["sale_id", "customer_id", "product_id", "revenue"]
)
# Dummy product catalog
catalog_data = [
(
f"PROD_{i:03d}",
f"Product {i}",
"Category A" if i % 2 == 0 else "Category B"
)
for i in range(20)
]
catalog = spark.createDataFrame(
catalog_data,
["product_id", "product_name", "category"]
)
# AQE will optimize this be part of dynamically at runtime
consequence = (
gross sales.be part of(catalog, on="product_id")
.groupBy("class")
.agg({"income": "sum"})
)
consequence.present()Output:
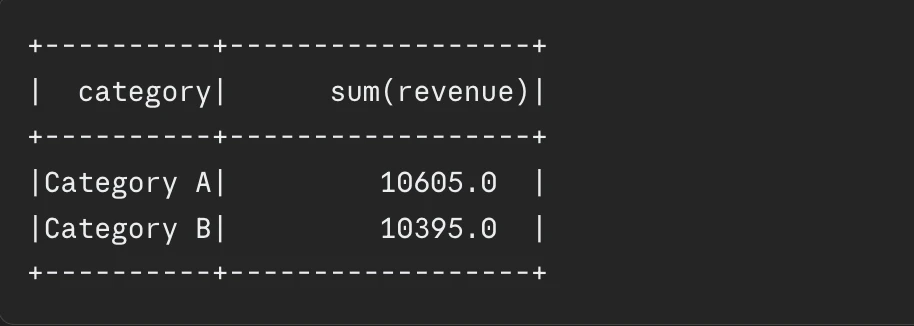
The implementation of AQE gives organizations with a bonus which requires minimal effort to realize. The system ought to be activated for all Spark model 3.x operations apart from circumstances which require particular exception dealing with.
Approach 7: Keep away from Python UDFs At any time when Doable
The Python Consumer Outlined Features UDFs create probably the most frequent efficiency issues in PySpark as a result of they introduce sudden delays. Python builders discover it straightforward to make use of these features however their utilization leads to important efficiency degradation.
Why Python UDFs Gradual Down Spark
Spark operates instantly on the Java Digital Machine which serves as its basic execution platform. Python operates outdoors the Java Digital Machine setting. Spark must execute a number of steps whenever you use a Python UDF as a result of it should convert knowledge from the JVM to Python, execute the operate, after which ship again the outcomes to the JVM. The system handles communication between elements by processing one row at a time.
Serialization Overhead
The system wants to remodel each knowledge row from Spark’s inside binary format into Python objects for processing earlier than it will probably create the Python objects. The method of serialization and deserialization incurs excessive prices as a result of it must deal with tens of millions of rows.
JVM-to-Python Communication Price
The system creates an unbiased Python course of for every executor in Spark. The JVM and Python processes change knowledge by a community socket. When working at scale, this communication bottleneck causes Python UDFs to carry out 10 instances slower than equal native Spark features.
Want Native Spark Features
The features from pyspark.sql.features execute fully inside the JVM setting which eliminates the necessity for Python knowledge conversion. The system achieves sooner execution speeds by compiled and optimized features that outperform customized Python UDFs.
PySpark Code Instance
from pyspark.sql import SparkSession
from pyspark.sql.features import (
col,
when,
regexp_replace,
udf,
initcap
)
from pyspark.sql.sorts import StringType
spark = (
SparkSession.builder
.appName("UDFDemo")
.getOrCreate()
)
knowledge = [
("alice smith", 85000, "engineering"),
("bob jones", 72000, "marketing"),
("charlie brown", 110000, "engineering"),
("diana prince", 65000, "hr"),
("eve white", 92000, "engineering"),
]
df = spark.createDataFrame(
knowledge,
["name", "salary", "department"]
)
# BAD: Python UDF — sluggish as a consequence of serialization
def format_name_udf(identify):
return identify.title().substitute(" ", "_")
format_udf = udf(format_name_udf, StringType())
df_udf = df.withColumn(
"formatted_name",
format_udf(col("identify"))
)
# GOOD: Native Spark features
# — quick, no serialization
df_native = (
df.withColumn(
"formatted_name",
regexp_replace(
initcap(col("identify")),
" ",
"_"
)
)
.withColumn(
"salary_band",
when(col("wage") >= 100000, "Senior")
.when(col("wage") >= 80000, "Mid")
.in any other case("Junior")
)
)
df_native.present()Output:

Approach 8: Cache Information Strategically
Spark form of recomputes your DataFrame from scratch each time you hit an motion on it. So for those who do rely() after which, later present() on the “identical” DataFrame, Spark finally ends up working the entire pipeline twice. Caching helps, however provided that you truly use it with a little bit of sense, not simply because it exists.
Understanding Spark Caching
Principally, caching means oncethe DataFrame will get computed the primary time, Spark shops the lead to reminiscence (or disk). Then for the subsequent motion, Spark can learn these saved rows and skip the recomputation from the unique sources.
When to Use cache()
You need to cache a DataFrame when stuff like that is true:
- You find yourself reusing the identical DataFrame greater than as soon as in your workflow.
- The DataFrame is dear to construct (assume a number of joins , heavy aggregations , or a lot of file reads).
- It may comfortably match contained in the reminiscence accessible on the executors.
When Caching Can Harm Efficiency
If you happen to cache a DataFrame that you just contact solely as soon as, you pay some overhead for nothing. And caching large DataFrames that don’t actually slot in reminiscence can result in spill to disk , which may find yourself slower than simply recomputing. So it’s price checking if caching helps in your state of affairs.
cache() vs persist()
cache() all the time shops the DataFrame in reminiscence in a deserialized type. persist() provides you choices , like reminiscence solely, reminiscence + disk, disk solely, or serialized in-memory. In circumstances the place you want extra management over storage conduct, persist() is often the higher alternative.
PySpark Code Instance
from pyspark.sql import SparkSession
from pyspark.sql.features import (
col,
sum as spark_sum,
avg
)
spark = (
SparkSession.builder
.appName("CachingDemo")
.getOrCreate()
)
# Dummy retail knowledge
knowledge = [
("2024-01", "Electronics", "Laptop", 1200.00, 30),
("2024-01", "Furniture", "Chair", 200.00, 50),
("2024-02", "Electronics", "Phone", 800.00, 75),
("2024-02", "Electronics", "Monitor", 450.00, 40),
("2024-03", "Furniture", "Desk", 350.00, 20),
("2024-03", "Electronics", "Tablet", 600.00, 25),
("2024-04", "Furniture", "Lamp", 60.00, 60),
("2024-04", "Electronics", "Keyboard", 80.00, 100),
]
schema = [
"month",
"category",
"product",
"price",
"units"
]
df = spark.createDataFrame(knowledge, schema)
# Compute income as soon as
df_revenue = df.withColumn(
"income",
col("value") * col("items")
)
# Cache as a result of we use df_revenue a number of instances
df_revenue.cache()
# Motion 1: Income by class
print("Income by Class:")
df_revenue.groupBy("class").agg(
spark_sum("income").alias("total_revenue")
).present()
# Motion 2: Income by month
print("Income by Month:")
df_revenue.groupBy("month").agg(
spark_sum("income").alias("monthly_revenue")
).present()
# Motion 3: Common unit value
print("Common Worth per Class:")
df_revenue.groupBy("class").agg(
avg("value").alias("avg_price")
).present()
# At all times unpersist when finished
df_revenue.unpersist()Output:
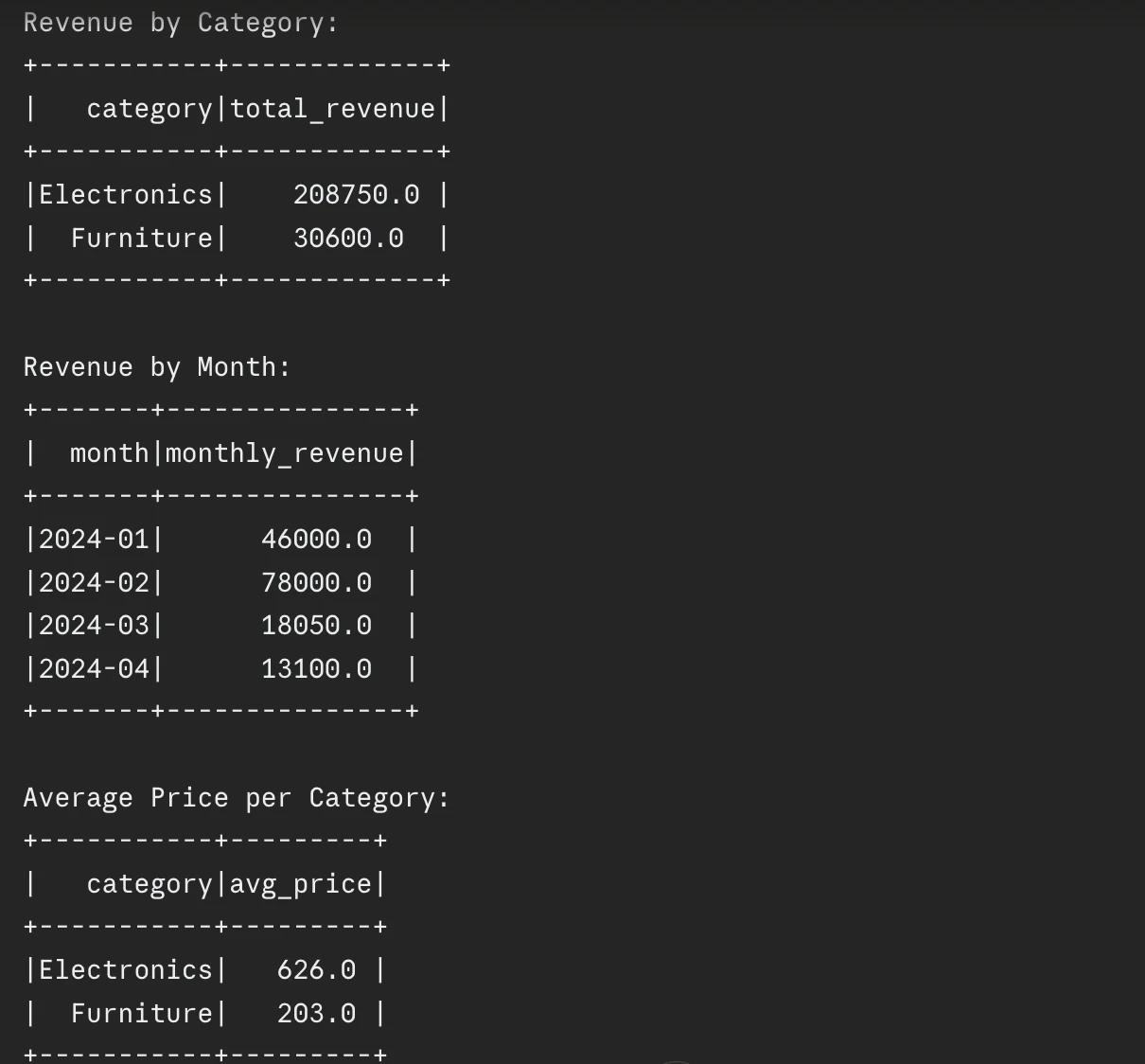
Eradicating Cached DataFrames
It’s essential to use unpersist() after you end working with a cached DataFrame. Cached DataFrames keep their reminiscence utilization till both the Spark session terminates otherwise you select to free them. Extreme caching of DataFrames will result in reminiscence stress which ends up in spilling.
Approach 9: Deal with Information Skew Effectively
Skewed knowledge distribution creates probably the most troublesome efficiency challenges for Spark methods. The system operates with out detection as a result of it creates prolonged process execution instances for particular duties which ends up in delayed job completion till the sluggish duties full their execution.
What Is Information Skew?
Information skew happens when some partitions include way more knowledge than others. A buyer orders dataset exhibits that one main buyer has 10 million orders whereas all different clients common 1,000 orders every. The client ID grouping operation in Spark creates one partition which comprises extreme knowledge.
Signs of Skewed Spark Jobs
Your job has reached 95% completion but it surely experiences a delay through the last duties. The scenario shows traditional skew conduct. Most duties full their operations shortly whereas a small variety of duties with heavy workloads create delays for your entire system.
Detecting Skew Utilizing Spark UI
You need to entry the Spark UI to look at the Levels tab. The duty metrics change into accessible when you choose a sluggish stage for evaluation. Information skew exists when some duties present larger values for “Enter Dimension” and “Shuffle Learn” and “Length” than their median values.
Methods to Repair Information Skew
- Salting: The method requires including a random prefix that ranges from 0 to N to the skewed key. This generates N smaller partitions which can consequence from processing the heavy partition. The salt ought to be deleted after the aggregation course of, and the outcomes ought to be mixed.
- AQE Skew Be a part of: Spark will mechanically handle the method whenever you allow the setting
spark.sql.adaptive.skewJoin.enabled. - Broadcast be part of: The system will broadcast the smaller be part of aspect when its dimension falls under the edge as a result of this methodology allows full operation without having a shuffle.
- Repartitioning: The system wants handbook repartitioning as a result of it requires higher distribution by particular column repartitioning.
PySpark Code Instance
from pyspark.sql import SparkSession
from pyspark.sql.features import (
col,
rand,
flooring,
concat,
lit,
sum as spark_sum
)
spark = (
SparkSession.builder
.appName("SkewDemo")
.config("spark.sql.adaptive.skewJoin.enabled", "true")
.getOrCreate()
)
# Skewed knowledge:
# buyer C001 has 80% of all orders
orders_data = (
[
(i, "C001", float(i * 12.5))
for i in range(1, 801)
] +
[
(
i + 800,
f"C{str(i % 10 + 2).zfill(3)}",
float(i * 9.9)
)
for i in range(1, 201)
]
)
orders = spark.createDataFrame(
orders_data,
["order_id", "customer_id", "amount"]
)
# Salting approach to repair skew manually
num_salts = 5
# Add salt to orders
orders_salted = orders.withColumn(
"salted_key",
concat(
col("customer_id"),
lit("_"),
(flooring(rand() * num_salts)).solid("string")
)
)
# Mixture with salted key
agg_salted = (
orders_salted
.groupBy("salted_key", "customer_id")
.agg(
spark_sum("quantity").alias("partial_sum")
)
)
# Remaining aggregation
# take away salt and sum partial outcomes
consequence = (
agg_salted
.groupBy("customer_id")
.agg(
spark_sum("partial_sum").alias("total_amount")
)
)
consequence.orderBy(
"total_amount",
ascending=False
).present(5)Output:
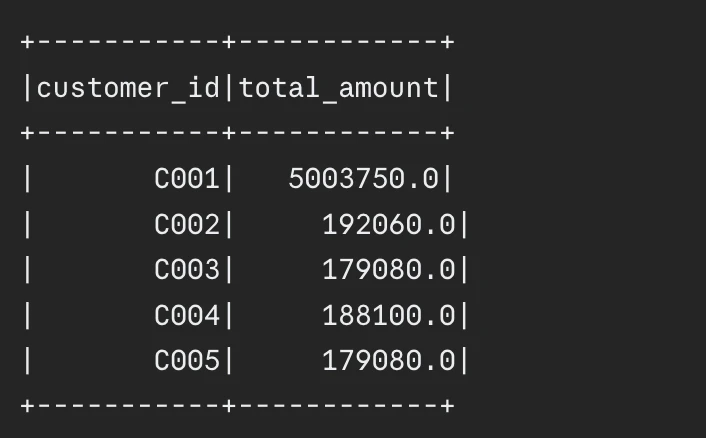
Actual-World Skew Optimization Instance
Information skew develops throughout actual pipelines when customers be part of on lively person IDs and prime product IDs and optionally available international keys which include default null values. At all times test your be part of key distributions earlier than writing your pipeline. The tactic to test for skew in knowledge makes use of groupBy("join_key").rely().orderBy("rely", ascending=False).present(10) to indicate outcomes.
Approach 10: Reduce Shuffle Operations
The costliest operation in Spark processing refers to shuffles as a result of these operations require community knowledge transfers between executors. The best optimization on your system happens by the method of decreasing shuffle operations.
Why Shuffles Are Costly
All rows should bear serialization earlier than Spark can course of them through the shuffle operation as a result of the system must retailer them on disk and ship them to the suitable executor after which convert them again into their unique format. The system operates all three elements collectively which embrace disk I/O and community I/O and CPU processing. The length of shuffles on intensive datasets can prolong from a number of minutes to a number of hours.
Operations That Set off Shuffles
The next frequent operations in Spark create shuffles:
- groupBy(): The operation teams knowledge based mostly on key values. The community switch course of turns into vital as a result of all rows sharing the identical key have to be processed on a single executor.
- be part of(): The operation performs a be part of between two DataFrames based mostly on matching keys. The be part of key partitioning requires each DataFrames to bear shuffling operations on one or each DataFrame sides.
- distinct(): The operation eliminates all duplicate rows by your entire dataset. The operation requires all duplicate row cases to assemble at a single location.
- orderBy(): The operation kinds all knowledge throughout each partition. The operation performs a world kind which mechanically creates a shuffle course of.
PySpark Code Instance
from pyspark.sql import SparkSession
from pyspark.sql.features import (
col,
sum as spark_sum,
countDistinct
)
spark = (
SparkSession.builder
.appName("ShuffleDemo")
.config("spark.sql.shuffle.partitions", "8")
.getOrCreate()
)
knowledge = [
("2024-Q1", "North", "Electronics", "Laptop", 1200.00, 30),
("2024-Q1", "South", "Electronics", "Phone", 800.00, 75),
("2024-Q2", "North", "Furniture", "Chair", 200.00, 50),
("2024-Q2", "East", "Electronics", "Monitor", 450.00, 40),
("2024-Q3", "West", "Electronics", "Tablet", 600.00, 25),
("2024-Q3", "North", "Furniture", "Desk", 350.00, 20),
("2024-Q4", "South", "Electronics", "Keyboard", 80.00, 100),
("2024-Q4", "East", "Furniture", "Lamp", 60.00, 60),
]
schema = [
"quarter",
"region",
"category",
"product",
"price",
"units"
]
df = spark.createDataFrame(knowledge, schema)
df = df.withColumn(
"income",
col("value") * col("items")
)
# BAD:
# A number of separate groupBy operations
# (a number of shuffles)
df_q1 = df.groupBy("class").agg(
spark_sum("income").alias("cat_revenue")
)
df_q2 = df.groupBy("area").agg(
spark_sum("income").alias("reg_revenue")
)
# GOOD:
# Mix aggregations in a single groupBy
# to scale back shuffles
df_combined = (
df.groupBy("class", "area")
.agg(
spark_sum("income").alias("total_revenue"),
spark_sum("items").alias("total_units")
)
)
df_combined.present()Output:
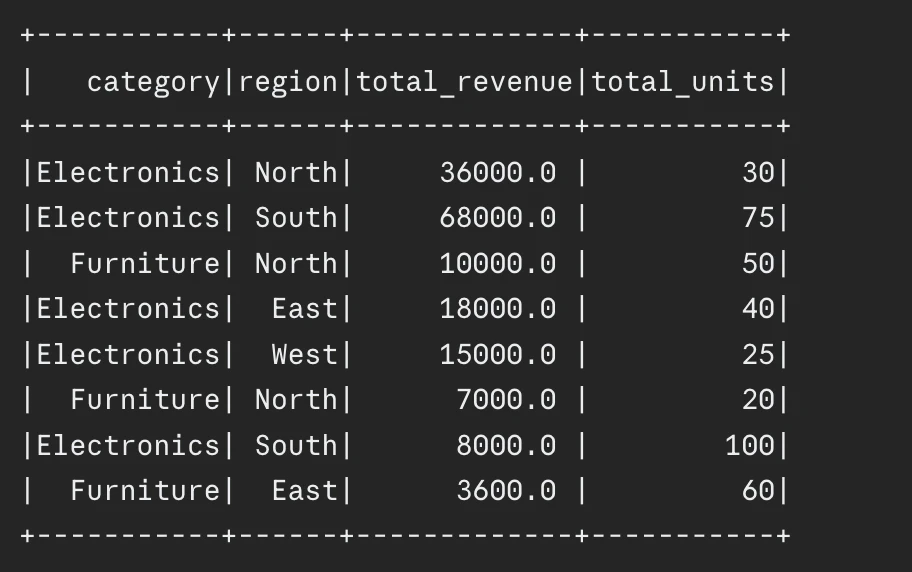
Monitoring Shuffle Metrics in Spark UI
The Levels tab in Spark UI shows each Shuffle Learn and Shuffle Write metrics. The operations require optimization from you after they produce massive shuffle sizes which ought to lead you to pre-partition your knowledge for capability discount. The SQL tab exhibits shuffle change nodes in your question plan.
Approach 11: Use Bucketing for Repeated Joins
The pipeline requires a number of joins of the identical massive tables which causes shuffle overhead to vanish by bucketing as a result of it creates disk-based knowledge group.
What Is Bucketing?
Bucketing is a way the place Spark writes knowledge to disk pre-sorted and pre-partitioned by a be part of key. Spark makes use of pre-existing knowledge partitions to conduct its joins as an alternative of performing knowledge shuffling. The result’s a be part of with no shuffle in any respect.
How Bucketing Improves Be a part of Efficiency
Once you bucket two tables on the identical key with the identical variety of buckets matching rows go into matching bucket recordsdata. When Spark reads these tables for a be part of it will probably instantly pair up corresponding bucket recordsdata with none community switch. The shuffle price drops to zero.
PySpark Code Instance
from pyspark.sql import SparkSession
spark = (
SparkSession.builder
.appName("BucketingDemo")
.config(
"spark.sql.sources.bucketing.enabled",
"true"
)
.enableHiveSupport()
.getOrCreate()
)
# Giant orders desk
orders_data = [
(
i,
f"CUST_{i % 100:03d}",
float(i * 25.0),
"completed"
)
for i in range(1, 501)
]
orders = spark.createDataFrame(
orders_data,
["order_id", "customer_id", "amount", "status"]
)
# Buyer data desk
customers_data = [
(
f"CUST_{i:03d}",
f"Customer {i}",
f"Region_{i % 5}"
)
for i in range(100)
]
clients = spark.createDataFrame(
customers_data,
["customer_id", "customer_name", "region"]
)
# Write each tables bucketed on customer_id
# with the identical variety of buckets
orders.write
.bucketBy(10, "customer_id")
.sortBy("customer_id")
.mode("overwrite")
.saveAsTable("orders_bucketed")
clients.write
.bucketBy(10, "customer_id")
.sortBy("customer_id")
.mode("overwrite")
.saveAsTable("customers_bucketed")
# Now this be part of requires NO shuffle
# Spark matches bucket recordsdata instantly
consequence = (
spark.desk("orders_bucketed")
.be part of(
spark.desk("customers_bucketed"),
on="customer_id"
)
.groupBy("area")
.agg({"quantity": "sum"})
)
consequence.present()Output:
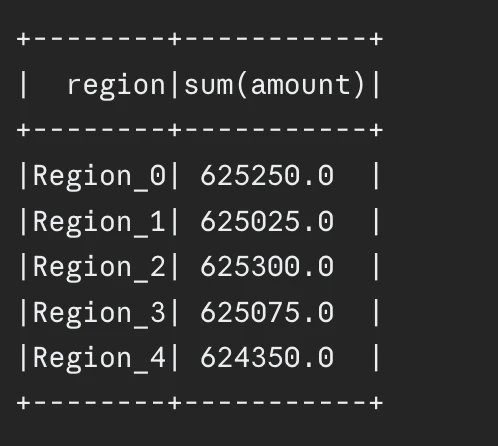
Finest Use Instances for Bucketing
- Your pipeline requires a number of joins with massive dimension tables which you course of repeatedly.
- Information warehouses use fact-to-dimension joins for his or her becoming a member of operations.
- Any two massive DataFrames that share the identical key could have a number of be part of operations all through the day.
- You need to use bucket-merge joins to interchange sort-merge joins in these particular conditions.
Approach 12: Tune Spark Configuration Settings
The right Spark configuration settings ship substantial efficiency enhancements which stay relevant even after implementing all code-level enhancements. Your jobs expertise efficiency degradation as a result of misconfigured executors both waste sources or generate reminiscence errors.
Vital Spark Configurations for Efficiency
Spark gives greater than 100 configuration settings. The next settings ship the strongest influence for general-purpose efficiency enhancements.
- Executor Reminiscence: Spark configuration by
spark.executor.reminiscenceunits the entire reminiscence allocation for executor-based calculations and knowledge preservation. Spark strikes knowledge to disk whenever you set this worth under the required degree. The extreme setting waste reminiscence sources which may help extra executor operations. - Executor Cores: The spark.executor.cores setting determines the variety of duties that every executor can course of on the identical time. The optimum vary for this worth lies between 2 and 5. The system experiences rubbish assortment stress when a number of cores entry the identical Java digital machine reminiscence house.
- Driver Reminiscence: The spark.driver.reminiscence setting establishes the entire reminiscence capability for the motive force. You need to enhance this parameter when your system collects intensive outcomes and wishes a number of broadcast variables whereas executing intricate question planning procedures.
PySpark Configuration Instance
from pyspark.sql import SparkSession
from pyspark.sql.features import (
col,
sum as spark_sum,
avg
)
spark = (
SparkSession.builder
.appName("ConfigTuningDemo")
.config("spark.executor.reminiscence", "4g")
.config("spark.executor.cores", "4")
.config("spark.driver.reminiscence", "2g")
.config("spark.sql.shuffle.partitions", "50")
.config("spark.sql.adaptive.enabled", "true")
.config(
"spark.sql.adaptive.coalescePartitions.enabled",
"true"
)
.config("spark.reminiscence.fraction", "0.8")
.config("spark.reminiscence.storageFraction", "0.3")
.config(
"spark.serializer",
"org.apache.spark.serializer.KryoSerializer"
)
.getOrCreate()
)
# Dummy payroll dataset
payroll_data = [
(
f"EMP_{i:04d}",
f"Dept_{i % 10}",
float(50000 + (i % 50) * 1000),
"FT" if i % 4 != 0 else "PT"
)
for i in range(1, 201)
]
df = spark.createDataFrame(
payroll_data,
[
"emp_id",
"department",
"annual_salary",
"employment_type"
]
)
consequence = (
df.filter(col("employment_type") == "FT")
.groupBy("division")
.agg(
spark_sum("annual_salary").alias("total_payroll"),
avg("annual_salary").alias("avg_salary")
)
.orderBy("total_payroll", ascending=False)
)
consequence.present(5)Output:
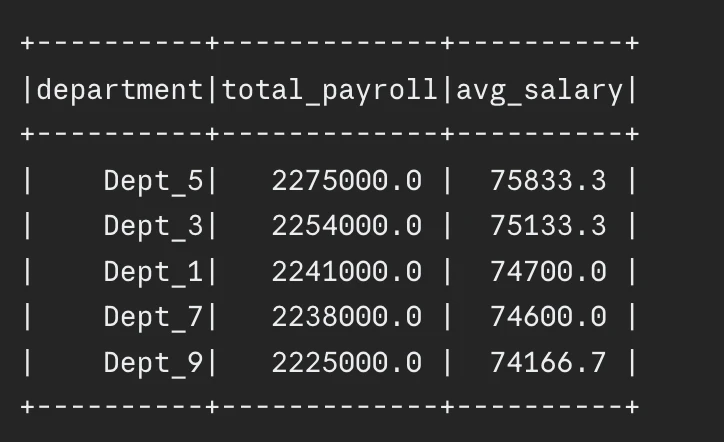
Cluster-Stage vs Utility-Stage Tuning
- Cluster-level settings: The cluster makes use of default settings from spark-defaults.conf to ascertain cluster-wide configuration for all Spark purposes. The baseline settings ought to be established by these settings.
- Utility-level settings: Utility-level settings (set in
SparkSession.builder.config()) override cluster defaults for a particular job. The system allows job-specific changes by these settings.
Finish-to-Finish PySpark Optimization Instance
Okay so now lets sew all these methods collectively into one thing that feels extra like an actual pipeline. We begin with a sluggish, kinda unoptimized job, then we work out the place it stalls, and solely after that we stack a number of methods to get the optimized model out.
Baseline Gradual Spark Job
from pyspark.sql import SparkSession
from pyspark.sql.features import (
col,
sum as spark_sum,
broadcast
)
spark = (
SparkSession.builder
.appName("OptimizedJob")
.config("spark.sql.adaptive.enabled", "true")
.getOrCreate()
)
# Giant transactions desk
# Learn as Parquet as an alternative of CSV for higher efficiency
transactions = spark.learn.parquet(
"/tmp/transactions_parquet"
)
# Product lookup desk
merchandise = spark.learn.parquet(
"/tmp/products_parquet"
)
# Filter early and choose solely required columns
transactions_filtered = (
transactions
.filter(col("standing") == "accomplished")
.choose(
"product_id",
"quantity"
)
)
products_selected = (
merchandise
.choose(
"product_id",
"class"
)
)
# Broadcast small lookup desk
consequence = (
transactions_filtered
.be part of(
broadcast(products_selected),
on="product_id"
)
.groupBy("class")
.agg(
spark_sum("quantity").alias("total_amount")
)
)
consequence.present()Figuring out Efficiency Bottlenecks
If we run consequence.clarify(True) on the sluggish job it exhibits a bunch of issues: there isn’t any predicate pushdown, which occurs as a result of CSV merely doesn’t help it, you get a full kind merge be part of which causes an enormous shuffle, it reads all columns from each recordsdata, and adaptive optimizations should not enabled in any respect.
Making use of A number of Optimization Methods
Now allow us to rewrite the job, with all of the optimizations turned on and utilized, step-by-step so it behaves correctly.
from pyspark.sql import SparkSession
from pyspark.sql.features import (
broadcast,
col,
sum as spark_sum
)
spark = (
SparkSession.builder
.appName("OptimizedJob")
.config("spark.sql.adaptive.enabled", "true")
.config(
"spark.sql.adaptive.coalescePartitions.enabled",
"true"
)
.config(
"spark.sql.adaptive.skewJoin.enabled",
"true"
)
.config("spark.sql.shuffle.partitions", "20")
.config(
"spark.serializer",
"org.apache.spark.serializer.KryoSerializer"
)
.getOrCreate()
)
# Create dummy transactions
# (in an actual job, learn from Parquet)
txn_data = [
(
f"TXN{i:05d}",
f"PROD_{i % 10:03d}",
float(i * 14.5),
"completed" if i % 5 != 0 else "failed",
f"CUST_{i % 50:03d}"
)
for i in range(1, 1001)
]
transactions = spark.createDataFrame(
txn_data,
[
"txn_id",
"product_id",
"amount",
"status",
"customer_id"
]
)
# Small merchandise desk
# excellent for broadcasting
prod_data = [
(
f"PROD_{i:03d}",
f"Product {i}",
"Electronics" if i % 2 == 0 else "Furniture"
)
for i in range(10)
]
merchandise = spark.createDataFrame(
prod_data,
[
"product_id",
"product_name",
"category"
]
)Optimizing Partitions
# Repartition transactions on product_id earlier than be part of
transactions_repartitioned = transactions.repartition(20, "product_id")Including Broadcast Be a part of
# Use broadcast for the small merchandise desk — eliminates shuffle
joined = transactions_repartitioned.be part of(broadcast(merchandise), on="product_id")Enabling AQE
Already enabled within the SparkSession config above. AQE handles dynamic partition coalescing and skew joins mechanically, prefer it simply… effectively, takes care of it on the fly.
Lowering Shuffle
# Filter early, choose solely required columns, mixture in a single cross
consequence = joined
.filter(col("standing") == "accomplished")
.choose("txn_id", "class", "quantity")
.groupBy("class")
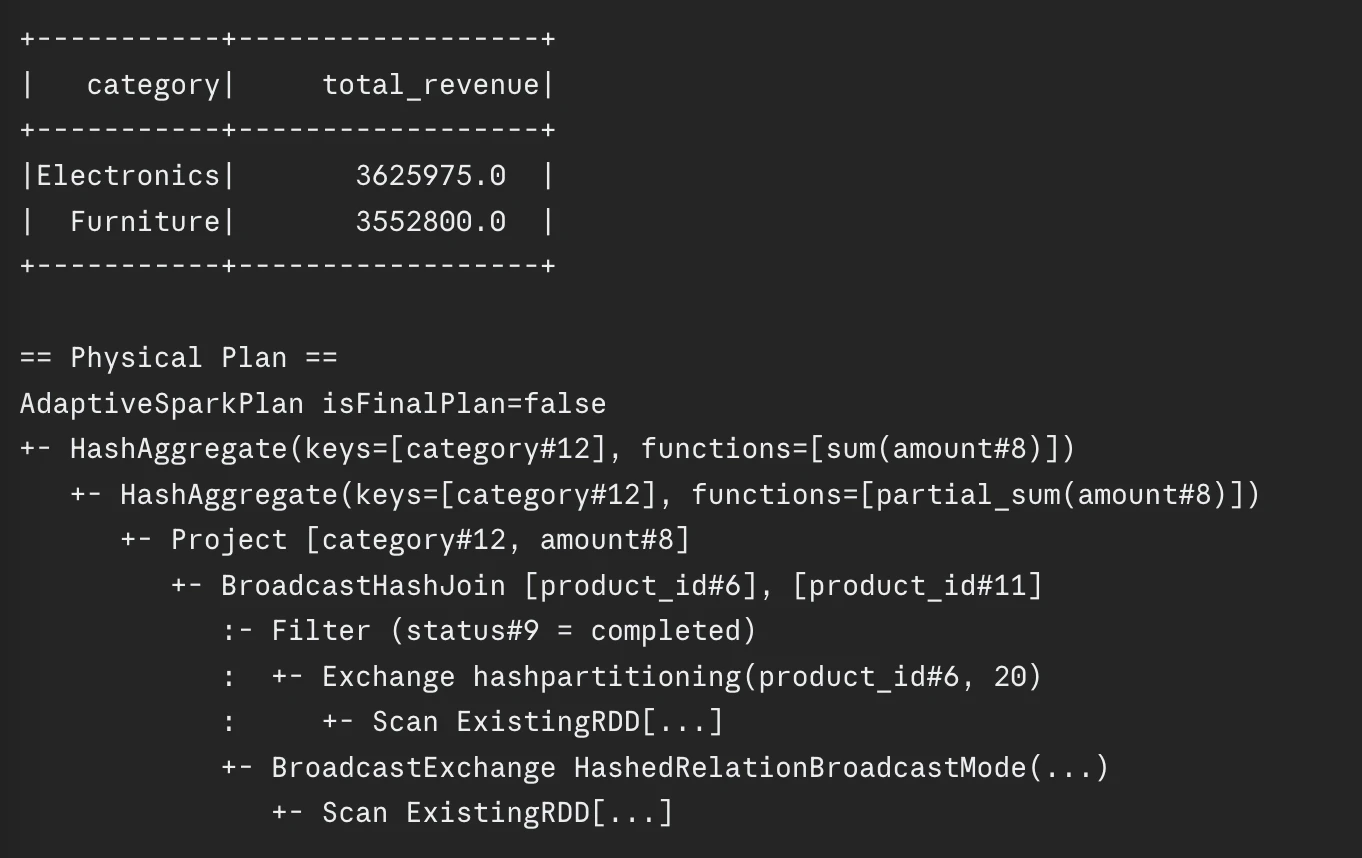
.agg(spark_sum("quantity").alias("total_revenue"))Remaining Optimized Model
consequence.present()
consequence.clarify()Output:
Conclusion
PySpark optimization is not only one single repair, its extra like this stacked set of layered selections that snowball into large efficiency wins. Begin with the excessive influence fundamentals, use Parquet, flip on AQE , filter early and solely pull the columns you really need. After that, transfer into the be part of technique stuff, assume partitioning and cope with skew.
With these 12 methods in your toolkit you may usually drag hours-long Spark runs right down to minutes, however it’s important to apply them in a scientific means. Additionally measure it utilizing the Spark UI, and preserve tuning as you be taught. The hole between a sluggish Spark job and a quick one is often very apparent when you take a look at the execution plan.
Howdy! I am Vipin, a passionate knowledge science and machine studying fanatic with a robust basis in knowledge evaluation, machine studying algorithms, and programming. I’ve hands-on expertise in constructing fashions, managing messy knowledge, and fixing real-world issues. My objective is to use data-driven insights to create sensible options that drive outcomes. I am desirous to contribute my abilities in a collaborative setting whereas persevering with to be taught and develop within the fields of Information Science, Machine Studying, and NLP.
Login to proceed studying and revel in expert-curated content material.