Most AI brokers in the present day comply with fastened directions and by no means get smarter on their very own. They end a job, overlook what occurred, and repeat the identical errors tomorrow. A brand new design known as the self-improving loop adjustments this. It lets brokers study from each consequence and enhance over time.
This information explains the self-improving loop in clear, easy language. You’ll study the way it works, why it beats conventional agent workflows, and the place it provides actual worth. We embrace a runnable code instance with dummy knowledge so each technical and non-technical readers can comply with alongside.
Understanding Conventional Agentic Workflows
Earlier than we transfer to self-improving brokers, we should perceive the techniques they improve. Conventional agentic workflows energy most AI assistants you utilize in the present day. They’re highly effective, common, and ok for a lot of jobs. Nonetheless, they share one massive weak point that limits long-term efficiency. Allow us to break down how they work.
The workflow is linear: sense → cause → act, after which the method ends or strikes to a brand new job with out studying from the consequence.
Typical Agent Structure
Most conventional brokers share a easy, repeatable construction underneath the hood. Understanding these components makes the later comparability a lot simpler to comply with. Under are the widespread constructing blocks of an ordinary agent.
- The immediate: Mounted directions that inform the agent what to do and the right way to behave.
- The reasoning step: The mannequin plans actions, usually utilizing a sample like reason-then-act.
- The instruments: Non-compulsory helpers equivalent to net search, code runners, or databases.
- The output: The ultimate response delivered again to the consumer as soon as the duty finishes.
Strengths of Conventional Brokers
Conventional brokers stay common as a result of they provide clear and dependable advantages. They don’t seem to be outdated, and lots of groups depend on them daily. Listed below are the strengths that hold them related.
- Predictable behaviour: The identical enter normally produces an analogous and secure output.
- Quick to construct: A succesful agent can ship in hours with fashionable frameworks.
- Simple to audit: Mounted prompts make the agent’s logic easy to evaluation and debug.
- Low complexity: Fewer shifting components imply fewer issues can break in manufacturing.
Key Limitations of Conventional Brokers
Regardless of their simplicity, conventional brokers have essential downsides:
- No Lengthy-Time period Studying: They don’t retain information past the quick job. Every job begins “contemporary,” so that they repeat the identical errors repeatedly.
- Static Immediate/Mannequin: The agent’s directions (prompts) and mannequin weights by no means change on the fly.
- No Suggestions Loop: They lack a built-in suggestions or analysis step. As soon as a solution is given, the loop stops.
- Repeated Errors: With out evaluation, a mistake (like a bug in reasoning or a improper truth) can persist indefinitely.
What’s the Self-Enhancing Loop in AI Brokers?
The self-improving loop is the improve that fixes the weaknesses above. It turns a one-shot employee right into a system that learns from expertise. This part defines the idea and explains its inside workings step-by-step. The concept is less complicated than it sounds, so allow us to stroll by way of it.
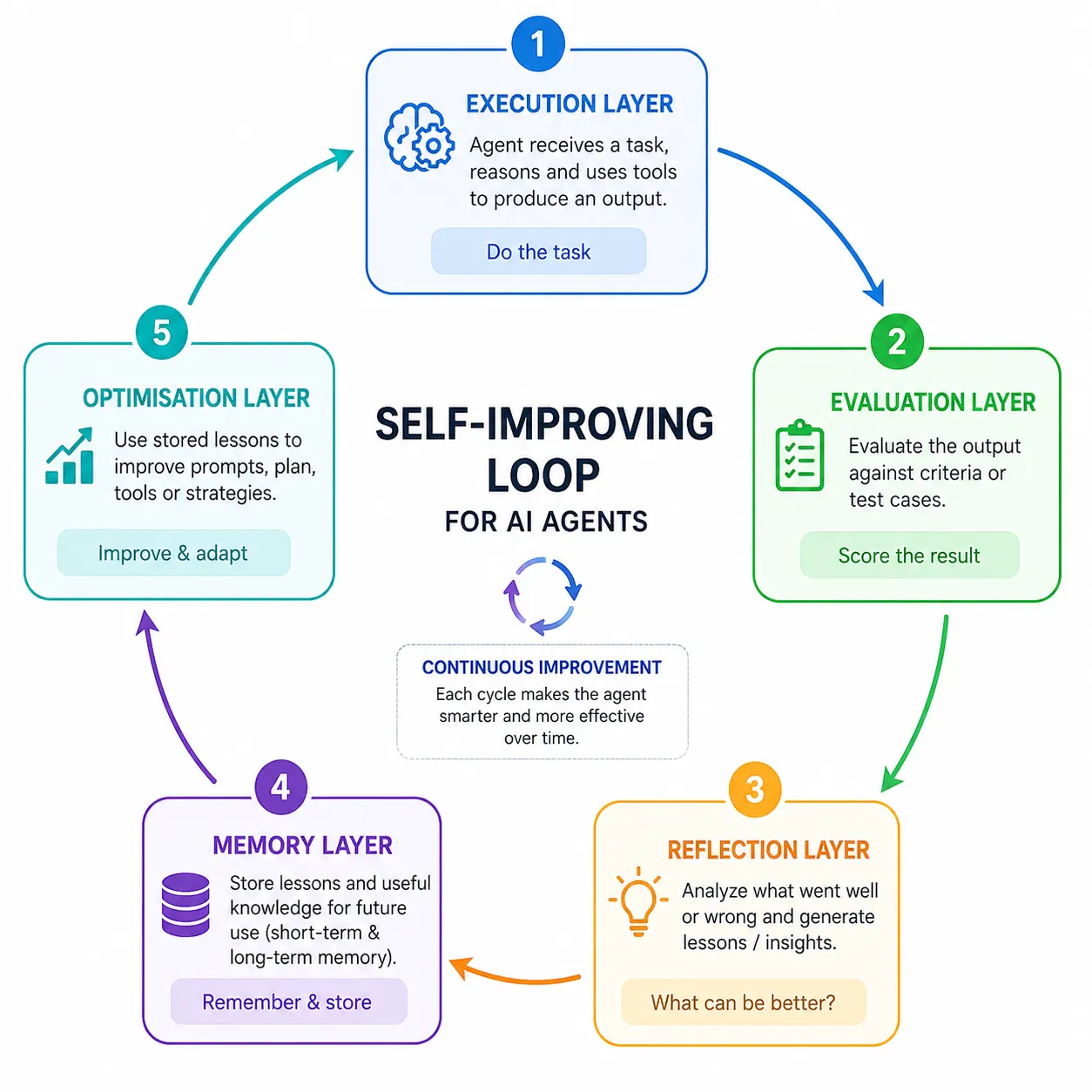
A self-improving agent does its job, checks its personal consequence, and learns from what occurred. It writes down helpful classes, shops them in reminiscence, and applies them subsequent time. With every cycle, the agent will get slightly sharper. This steady loop is the guts of self-improvement.
Why Self-Enchancment Issues for Agent Efficiency
Self-improvement issues as a result of it removes the necessity for fixed human statement. The agent learns from actual suggestions as an alternative of ready for an engineer to repair it. This part highlights why that shift adjustments efficiency so dramatically.
- Fewer repeated errors: Some groups report sharp drops in repeated errors as soon as reminiscence is added.
- Larger job completion: Research recommend memory-equipped brokers full much more multi-step duties efficiently.
- Much less handbook maintenance: The agent adapts by itself, so engineers spend much less time rewriting prompts.
- Compounding features: Small enhancements stack over time, very like curiosity in a financial savings account.
Core Parts of a Self-Enhancing Agent
A self-improving agent is constructed from 5 working layers. Every layer has one clear job, and collectively they type the loop. Understanding these 5 components makes the entire system straightforward to image.
- Execution Layer: The execution layer is the employee that does the duty. It reads the request, causes by way of a plan, and produces an output. This layer behaves very like a standard agent by itself. The distinction is that the opposite layers watch and information it.
- Analysis Layer: The analysis layer acts as a strict choose of the output. It scores the consequence towards clear high quality checks or check circumstances.
- Reflection Layer: The reflection layer asks a easy query: what went improper and why? It turns a low rating into plain-language classes the agent can reuse. This verbal suggestions acts like a coach stating a selected weak point.
- Reminiscence Layer: The reminiscence layer shops the teachings, so that they survive past a single job. Brief-term reminiscence holds the present dialog, whereas long-term reminiscence holds lasting information.
- Optimisation Layer: The optimisation layer applies saved classes to enhance future behaviour. It might refine the immediate, reorder steps, or choose higher instruments. Over many cycles, this layer reshapes how the agent works.
Self-Enhancing Loop vs Conventional Agent Workflow
Now we place each designs aspect by aspect to see the actual distinction. The distinction is sharpest while you watch how every one handles a mistake. This part compares structure, workflow, and options in plain phrases. The hole will turn out to be apparent in a short time.
Architectural Comparability
The 2 architectures differ primarily in what occurs after the output is produced. A standard agent stops on the output, whereas a self-improving agent retains going. That single addition adjustments every little thing about long-term efficiency. Right here is the structural distinction in easy phrases.
- Conventional agent: Immediate to reasoning to instruments to output, then it stops.
- Self-improving agent: Immediate to reasoning to output, then consider, mirror, keep in mind, and optimize.
- Reminiscence: Conventional brokers overlook; self-improving brokers retailer classes throughout duties.
- Suggestions: Conventional brokers have none; self-improving brokers grade and proper themselves.
Workflow Comparability: Step-by-Step
Trying on the workflow as a sequence makes the distinction very clear. Each begin the identical means however finish very in a different way. Under are the 2 workflows written out plainly.
Conventional Agent Workflow: The normal workflow is brief and linear from begin to end. It does the job as soon as and strikes on. These are its typical steps.
- Learn the immediate and the consumer request.
- Purpose by way of a plan and name any instruments.
- Produce the ultimate output.
- Cease, with no evaluation and no reminiscence saved.
Self-Enhancing Loop Workflow: The self-improving workflow provides a suggestions cycle after the primary output. It refuses to accept a weak consequence. These are its typical steps.
- Learn the immediate and produce a primary try.
- Consider the try towards high quality checks.
- Replicate on failures and write clear classes.
- Save these classes into long-term reminiscence.
- Retry with the teachings utilized, then reuse them on future duties.
Function-by-Function Comparability Desk
The desk under summarizes the sensible variations instantly. It covers the options that matter most for actual initiatives. Use it as a fast reference when selecting a design.
| Function | Conventional Agent | Self-Enhancing Loop Agent |
|---|---|---|
| Studying Functionality | No studying after deployment; behaviour stays static. | Constantly learns from outcomes, suggestions, and previous experiences. |
| Reminiscence Utilization | Forgets context and classes after job completion. | Shops and retrieves information for future duties. |
| Error Discount | Typically repeats the identical errors throughout comparable duties. | Identifies patterns in failures and reduces recurring errors over time. |
| Adaptability | Requires handbook immediate updates or workflow adjustments. | Adapts routinely primarily based on suggestions and new info. |
| Scalability | Progress relies upon closely on human upkeep and intervention. | Turns into more practical as its information and expertise enhance. |
| Operational Effectivity | Efficiency stays comparatively fixed over time. | Efficiency improves and compounds with every iteration. |
Actual-World Instance: Analysis and Evaluation Agent
Idea is useful however seeing the loop run makes it click on immediately. On this instance, a Analysis and Evaluation Agent reply market-research questions. A robust report should embrace market numbers, the highest competitor, the important thing danger, and a cited supply. We run the identical duties by way of each designs and examine the scores.
This model makes use of the actual gpt-4o-mini mannequin from OpenAI. The normal agent is a single mannequin name with a set immediate. The self-improving agent runs a LangGraph loop that grades and corrects itself. Non-technical readers can merely learn the output and watch the scores rise.
Dependencies and API Key
Earlier than working something, set up the libraries and set your OpenAI API key. These steps are the identical for each brokers proven under. The setup takes a couple of minute.
First, set up the required Python packages out of your terminal:
!pip set up langgraph langchain-openai langchain-core pydanticSubsequent, set your OpenAI API key as an setting variable:
export OPENAI_API_KEY="sk-your-key-here"Each brokers share the identical setup: the mannequin, the dummy knowledge, and a strict evaluator. We outline that shared basis as soon as under, then construct every agent on high of it. The bottom immediate is intentionally slim, which is what the self-improving loop will later increase.
from typing import TypedDict, Checklist, Dict
from pydantic import BaseModel, Subject
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage, HumanMessage
from langgraph.graph import StateGraph, START, END
# One mannequin writes, a SEPARATE mannequin grades.
# That is extra dependable than self-grading.
gen_llm = ChatOpenAI(mannequin="gpt-4o-mini", temperature=0.3)
eval_llm_base = ChatOpenAI(mannequin="gpt-4o-mini", temperature=0)
# Dummy knowledge: three comparable market-research duties
TASKS = [
{
"id": "T1",
"question": "Should we launch an electric scooter in Pune in 2026?",
"facts": {
"market_size_units": 240000,
"yoy_growth_pct": 31,
"top_competitor": "Bolt Mobility",
"avg_price_inr": 95000,
"key_risk": "monsoon road flooding reduces ridership",
"source": "Pune Transport Authority 2025 report",
},
},
{
"id": "T2",
"question": "Should we launch an electric scooter in Jaipur in 2026?",
"facts": {
"market_size_units": 180000,
"yoy_growth_pct": 27,
"top_competitor": "Ather Energy",
"avg_price_inr": 102000,
"key_risk": "summer heat shortens battery life",
"source": "Rajasthan EV Council 2025 brief",
},
},
{
"id": "T3",
"question": "Should we launch an electric scooter in Kochi in 2026?",
"facts": {
"market_size_units": 130000,
"yoy_growth_pct": 22,
"top_competitor": "Ola Electric",
"avg_price_inr": 88000,
"key_risk": "limited charging stations outside the city",
"source": "Kerala Mobility Board 2025 survey",
},
},
]
PASS_MARK = 4 # all 4 checks should move
MAX_ITERS = 4 # guardrail so the loop can by no means run endlessly
# The bottom transient is deliberately NARROW.
# Realized classes increase it later.
BASE_SYSTEM = (
"You're a market-research analyst.n"
"Write a brief launch advice in 2-3 sentences.n"
"Cowl solely the decision and the market measurement and progress. Preserve it transient."
)
def build_generator_system(classes: Checklist[str]) -> str:
system = BASE_SYSTEM
if classes:
system += "nnAlways comply with these discovered guidelines as nicely:n"
system += "n".be part of(f"- {rule}" for rule in classes)
return system
def facts_block(job: dict) -> str:
f = job["facts"]
return (
"FACTS:n"
f"- Market measurement: {f['market_size_units']:,} unitsn"
f"- Yr-over-year progress: {f['yoy_growth_pct']}%n"
f"- Prime competitor: {f['top_competitor']}n"
f"- Common worth: INR {f['avg_price_inr']:,}n"
f"- Key danger: {f['key_risk']}n"
f"- Information supply: {f['source']}"
)
def generate_report(job: dict, classes: Checklist[str]) -> str:
system = build_generator_system(classes)
consumer = f"QUESTION: {job['question']}nn{facts_block(job)}"
response = gen_llm.invoke(
[SystemMessage(content=system), HumanMessage(content=user)]
)
return response.content material.strip()
# Analysis layer: a separate mannequin returns a strict, structured rating.
class Analysis(BaseModel):
has_market_numbers: bool = Subject(description="States market measurement and progress.")
names_competitor: bool = Subject(description="Names the highest competitor.")
states_key_risk: bool = Subject(description="States the important thing danger.")
cites_source: bool = Subject(description="Cites the info supply.")
critique: str = Subject(description="One quick sentence on what to enhance.")
evaluator = eval_llm_base.with_structured_output(Analysis)
def evaluate_report(job: dict, report: str) -> Analysis:
system = (
"You're a strict QA evaluator for market-research studies.n"
"Examine the REPORT towards the ground-truth FACTS.n"
"Mark every ingredient true ONLY whether it is clearly current within the report."
)
consumer = (
f"{facts_block(job)}nn"
"REQUIRED ELEMENTS: market numbers, high competitor, key danger, cited supply.nn"
f"REPORT:n{report}"
)
return evaluator.invoke(
[SystemMessage(content=system), HumanMessage(content=user)]
)
def score_of(ev: Analysis) -> int:
return (
int(ev.has_market_numbers)
+ int(ev.names_competitor)
+ int(ev.states_key_risk)
+ int(ev.cites_source)
)The Conventional Agent and Its Output
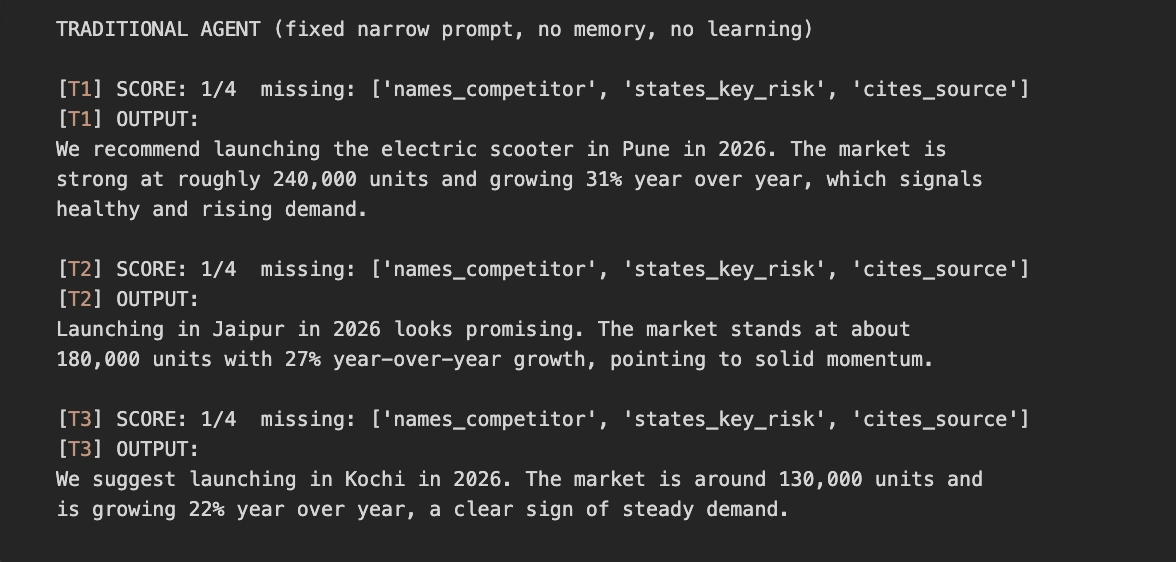
The normal agent makes one mannequin name per job utilizing the fastened, slim immediate. It has no loop and no reminiscence, so it by no means learns. We nonetheless rating its output, however solely to measure high quality. The agent itself by no means sees that suggestions.
def run_traditional():
print("TRADITIONAL AGENT (fastened slim immediate, no reminiscence, no studying)")
for job in TASKS:
report = generate_report(job, classes=[]) # by no means learns
ev = evaluate_report(job, report) # scored solely to measure
flags = {
"has_market_numbers": ev.has_market_numbers,
"names_competitor": ev.names_competitor,
"states_key_risk": ev.states_key_risk,
"cites_source": ev.cites_source,
}
lacking = [k for k, v in flags.items() if not v]
print(f"n[{task['id']}] SCORE: {score_of(ev)}/4 lacking: {lacking or 'none'}")
print(f"[{task['id']}] OUTPUT:n{report}")
run_traditional()As a result of the immediate solely asks for a verdict and market measurement, the agent at all times omits the competitor, danger, and supply. It repeats this similar hole on each job. Here’s a consultant run, although your precise wording will differ as a result of the mannequin just isn’t deterministic.
The Self-Enhancing Agent and Its Output
The self-improving agent runs a LangGraph loop as an alternative of a single name. It generates a draft, evaluates it, displays on the misses, shops classes in reminiscence, and retries. The teachings persist throughout duties, so later duties begin smarter. The loop stops at an ideal rating or the security cap.
# Reflection layer: flip misses into reusable, plain-language classes.
def mirror(ev: Analysis) -> Checklist[str]:
classes = []
if not ev.has_market_numbers:
classes.append("At all times embrace the market measurement and year-over-year progress.")
if not ev.names_competitor:
classes.append("At all times identify the highest competitor and the right way to beat it.")
if not ev.states_key_risk:
classes.append("At all times state the only largest danger to the launch.")
if not ev.cites_source:
classes.append("At all times cite the info supply on the finish of the report.")
return classes
# LangGraph state shared between the loop nodes
class LoopState(TypedDict, whole=False):
job: dict
classes: Checklist[str] # reminiscence threaded out and in
report: str
rating: int
flags: Dict[str, bool]
iterations: int
def node_generate(state: LoopState) -> dict:
try = state["iterations"] + 1
report = generate_report(state["task"], state["lessons"])
print(f" - generate (try {try})")
return {"report": report, "iterations": try}
def node_evaluate(state: LoopState) -> dict:
ev = evaluate_report(state["task"], state["report"])
flags = {
"has_market_numbers": ev.has_market_numbers,
"names_competitor": ev.names_competitor,
"states_key_risk": ev.states_key_risk,
"cites_source": ev.cites_source,
}
lacking = [k for k, v in flags.items() if not v]
print(f" - consider -> rating {score_of(ev)}/4, lacking: {lacking or 'none'}")
return {"rating": score_of(ev), "flags": flags}
def node_reflect(state: LoopState) -> dict:
fake_ev = Analysis(critique="", **state["flags"])
new_lessons = mirror(fake_ev)
merged = state["lessons"] + [
lesson for lesson in new_lessons if lesson not in state["lessons"]
]
print(f" - mirror -> added {len(new_lessons)} lesson(s)")
return {"classes": merged}
def route(state: LoopState) -> str:
if state["score"] >= PASS_MARK or state["iterations"] >= MAX_ITERS:
return "finished"
return "mirror"
# Construct the loop: generate -> consider -> (mirror -> generate)* -> finished
g = StateGraph(LoopState)
g.add_node("generate", node_generate)
g.add_node("consider", node_evaluate)
g.add_node("mirror", node_reflect)
g.add_edge(START, "generate")
g.add_edge("generate", "consider")
g.add_conditional_edges("consider", route, {"mirror": "mirror", "finished": END})
g.add_edge("mirror", "generate")
app = g.compile()
def run_self_improving():
print("SELF-IMPROVING AGENT (LangGraph loop: mirror, keep in mind, enhance)")
reminiscence: Checklist[str] = [] # long-term reminiscence, persists throughout duties
for job in TASKS:
print(f"n[{task['id']}] {job['question']}")
init: LoopState = {
"job": job,
"classes": reminiscence,
"report": "",
"rating": 0,
"flags": {},
"iterations": 0,
}
ultimate = app.invoke(init)
reminiscence = ultimate["lessons"] # carry classes to the subsequent job
print(
f"[{task['id']}] FINAL SCORE: {ultimate['score']}/4 "
f"in {ultimate['iterations']} try(s)"
)
print(f"[{task['id']}] FINAL OUTPUT:n{ultimate['report']}")
print("nMEMORY CARRIED FORWARD:")
for rule in reminiscence:
print(f" - {rule}")
run_self_improving()On the primary job, the agent scores low, displays, and saves three classes. It then retries and reaches an ideal rating. On the subsequent two duties, it passes on the primary try as a result of reminiscence already holds the teachings. Here’s a consultant run, although your precise wording will differ.
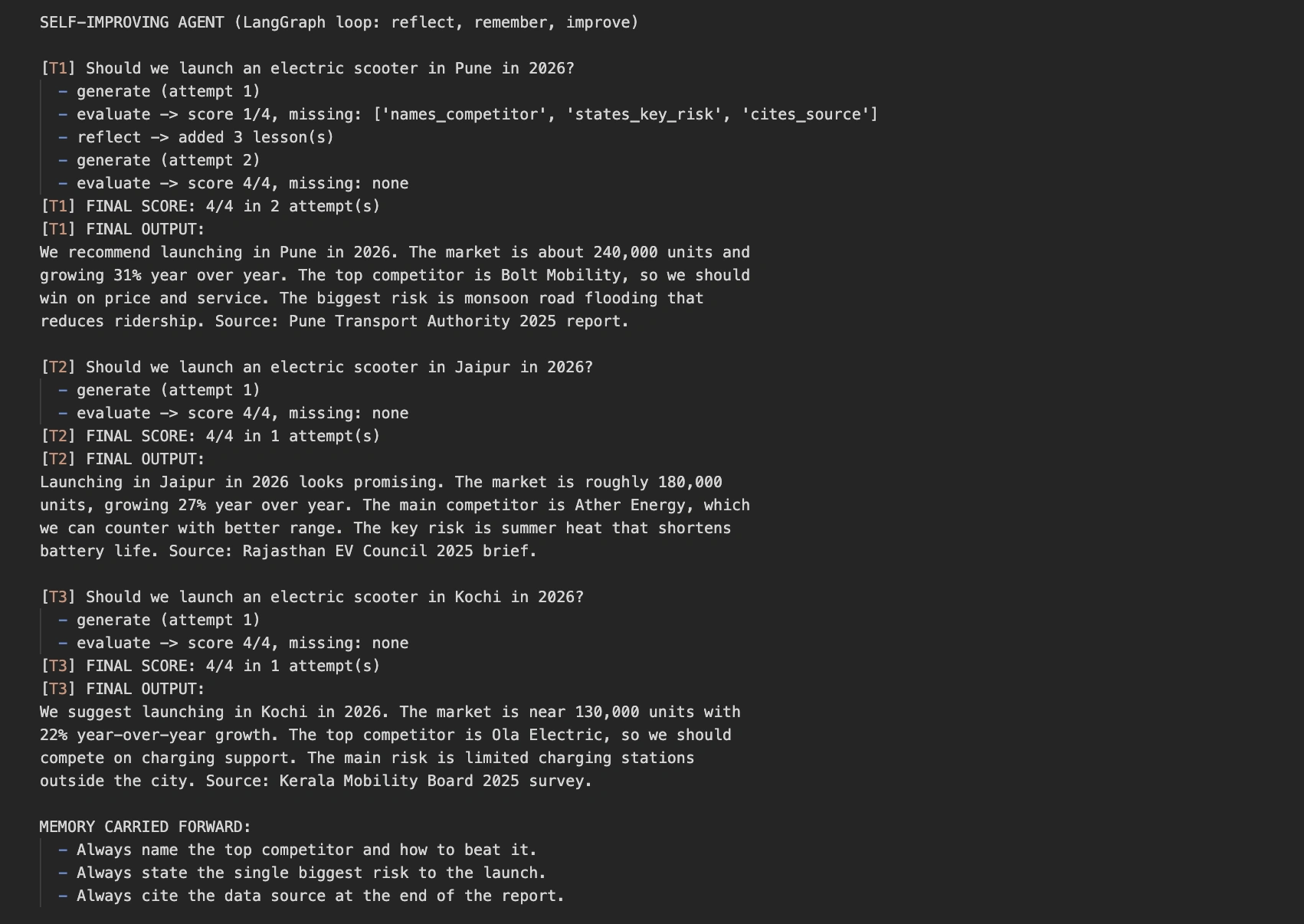
The distinction tells the entire story in two runs. The normal agent stays caught at 1 out of 4 on each job. The self-improving agent learns as soon as, then aces each job that follows. That soar from repeated failure to dependable success is the facility of the loop.
Key Applied sciences Behind Self-Enhancing Brokers
A number of confirmed applied sciences make the self-improving loop attainable in actual techniques. You do not want all of them without delay to begin. Nonetheless, understanding the toolbox helps you design higher brokers. This part covers the 5 most essential items.
- Reflection and Self-Critique Mechanisms: Reflection is the approach that lets an agent critique its personal work in phrases. The agent reads its consequence, names the issues, and writes steerage for subsequent time.
- Agent Reminiscence Techniques: Reminiscence is what lets reflection classes survive throughout duties and periods. With out reminiscence, an agent forgets every little thing the second a job ends. Fashionable brokers use a couple of distinct reminiscence sorts collectively. Right here is how every one works.
- Brief-Time period Reminiscence: Brief-term reminiscence holds the present dialog or the lively job particulars. It normally lives contained in the mannequin’s context window throughout one session.
- Lengthy-Time period Reminiscence: Lengthy-term reminiscence shops information that should survive throughout many periods. It usually makes use of a database or information retailer that persists over time.
- Vector Database Reminiscence: A vector database shops previous experiences as numerical embeddings for sensible recall. It finds recollections by that means, not by precise phrase matching.
- Analysis and Suggestions Techniques: Analysis techniques determine whether or not the agent’s output is sweet sufficient. They use high quality checks, check circumstances, or scoring rubrics to evaluate outcomes.
- Reinforcement Studying and Agent Optimization: Reinforcement studying teaches an agent by way of rewards for good outcomes and penalties for dangerous ones. Over many trials, the agent learns which actions result in success.
- Multi-Agent Collaboration for Self-Enchancment: Generally one agent just isn’t sufficient to catch each weak point. Multi-agent setups break up the work amongst specialists who test one another.
Challenges and Limitations of Self-Enhancing Brokers
Self-improving brokers are highly effective, however they aren’t magic. They convey actual dangers that groups should plan for rigorously. Figuring out these limits helps you undertake the strategy safely. Listed below are the primary challenges to observe.
- Degeneration of thought: An agent could hold defending a flawed reply as an alternative of really fixing it.
- Infinite loops: With no cease rule, an agent can hold “enhancing” endlessly with out converging.
- Dangerous reminiscence writes: One improper lesson saved to reminiscence can poison many future duties.
- Larger value and latency: Further analysis and retries use extra compute, time, and cash.
- Weak self-evaluation: If the evaluator is poor, the agent learns the improper classes confidently.
- Security and management: Brokers that change their very own habits want guardrails and human oversight.
Verdict: Is the Self-Enhancing Loop the Way forward for AI Brokers?
The sincere reply is that each designs have a spot in actual merchandise. The self-improving loop just isn’t an entire substitute for each job. It shines in some settings and provides useless value in others. This part offers a balanced verdict to information your alternative.
The place Conventional Brokers Nonetheless Excel
Conventional brokers stay the proper device for a lot of easy, secure jobs. They value much less, run quicker, and behave predictably. These are the circumstances the place they nonetheless win.
- Easy, one-shot duties: Fast lookups, quick replies, and routine actions want no studying loop.
- Latency-critical apps: When pace is every little thing, additional analysis steps solely sluggish issues down.
- Tight budgets: Fewer mannequin calls imply decrease value for high-volume, low-complexity work.
- Extremely regulated steps: Predictable habits is less complicated to certify and audit.
The place Self-Enhancing Brokers Create the Most Worth
Self-improving brokers earn their carry on exhausting, repeated, high-stakes work. The educational loop pays off when high quality and adaptation really matter. These are the circumstances the place they shine.
- Complicated, multi-step duties: Analysis, coding, and evaluation profit from iterative refinement.
- Altering environments: Markets, insurance policies, and knowledge that shift reward an agent that adapts.
- Repeated workflows: Classes discovered as soon as repay throughout hundreds of comparable future duties.
- Accuracy-critical work: Domains the place errors are expensive justify the additional checks.
In the event you need assistance determining the proper vector database on your wants confer with Selecting the Proper Vector Database.
Regularly Requested Questions
A. It’s an AI agent structure the place brokers consider outputs, mirror on errors, retailer classes, and enhance future job efficiency.
A. It makes use of execution, analysis, reflection, reminiscence, and optimisation layers to create suggestions loops that assist AI brokers study from outcomes.
A. Conventional brokers overlook previous errors, whereas self-improving brokers use reminiscence and suggestions to cut back repeated errors over time.
Hi there! I am Vipin, a passionate knowledge science and machine studying fanatic with a robust basis in knowledge evaluation, machine studying algorithms, and programming. I’ve hands-on expertise in constructing fashions, managing messy knowledge, and fixing real-world issues. My purpose is to use data-driven insights to create sensible options that drive outcomes. I am wanting to contribute my abilities in a collaborative setting whereas persevering with to study and develop within the fields of Information Science, Machine Studying, and NLP.
Login to proceed studying and luxuriate in expert-curated content material.