Right now, we’re exploring how Ethernet stacks up in opposition to InfiniBand in AI/ML environments, specializing in how Cisco Silicon One™ manages community congestion and enhances efficiency for AI/ML workloads. This submit emphasizes the significance of benchmarking and KPI metrics in evaluating community options, showcasing the Cisco Zeus Cluster geared up with 128 NVIDIA® H100 GPUs and cutting-edge congestion administration applied sciences like dynamic load balancing and packet spray.
Networking requirements to satisfy the wants of AI/ML workloads
AI/ML coaching workloads generate repetitive micro-congestion, stressing community buffers considerably. The east-to-west GPU-to-GPU visitors throughout mannequin coaching calls for a low-latency, lossless community material. InfiniBand has been a dominant know-how within the high-performance computing (HPC) atmosphere and these days within the AI/ML atmosphere.
Ethernet is a mature various, with superior options that may deal with the rigorous calls for of the AI/ML coaching workloads and Cisco Silicon One can successfully execute load balancing and handle congestion. We got down to benchmark and evaluate Cisco Silicon One versus NVIDIA Spectrum-X™ and InfiniBand.
Analysis of community material options for AI/ML
Community visitors patterns differ based mostly on mannequin measurement, structure, and parallelization methods utilized in accelerated coaching. To judge AI/ML community material options, we recognized related benchmarks and key efficiency indicator (KPI) metrics for each AI/ML workload and infrastructure groups, as a result of they view efficiency by totally different lenses.
We established complete checks to measure efficiency and generate metrics particular to AI/ML workload and infrastructure groups. For these checks, we used the Zeus Cluster, that includes devoted backend and storage with a typical 3-stage leaf-spine Clos material community, constructed with Cisco Silicon One–based mostly platforms and 128 NVIDIA H100 GPUs. (See Determine 1.)

We developed benchmarking suites utilizing open-source and industry-standard instruments contributed by NVIDIA and others. Our benchmarking suites included the next (see additionally Desk 1):
- Distant Direct Reminiscence Entry (RDMA) benchmarks—constructed utilizing IBPerf utilities—to guage community efficiency throughout congestion created by incast
- NVIDIA Collective Communication Library (NCCL) benchmarks, which consider software throughput throughout coaching and inference communication section amongst GPUs
- MLCommons MLPerf set of benchmarks, which evaluates essentially the most understood metrics, job completion time (JCT) and tokens per second by the workload groups
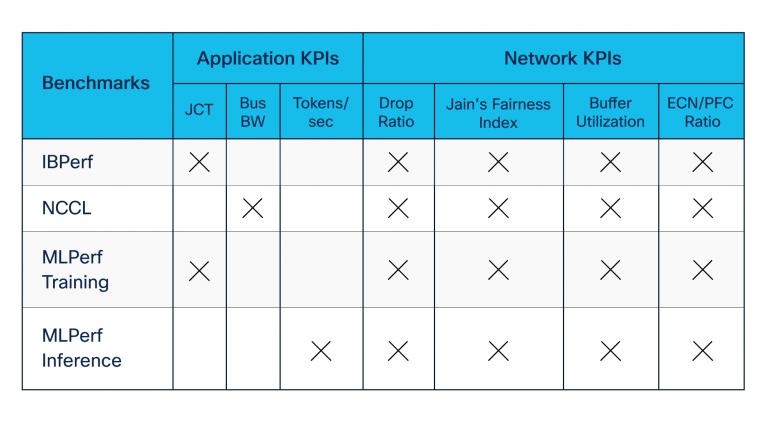
Legend:
JCT = Job Completion Time
Bus BW = Bus bandwidth
ECN/PFC = Specific Congestion Notification and Precedence Move Management
NCCL benchmarking in opposition to congestion avoidance options
Congestion builds up through the again propagation stage of the coaching course of, the place a gradient sync is required amongst all of the GPUs collaborating in coaching. Because the mannequin measurement will increase, so does the gradient measurement and the variety of GPUs. This creates huge micro-congestion within the community material. Determine 2 exhibits outcomes of the JCT and visitors distribution benchmarking. Notice how Cisco Silicon One helps a set of superior options for congestion avoidance, akin to dynamic load balancing (DLB) and packet spray methods, and Information Middle Quantized Congestion Notification (DCQCN) for congestion administration.
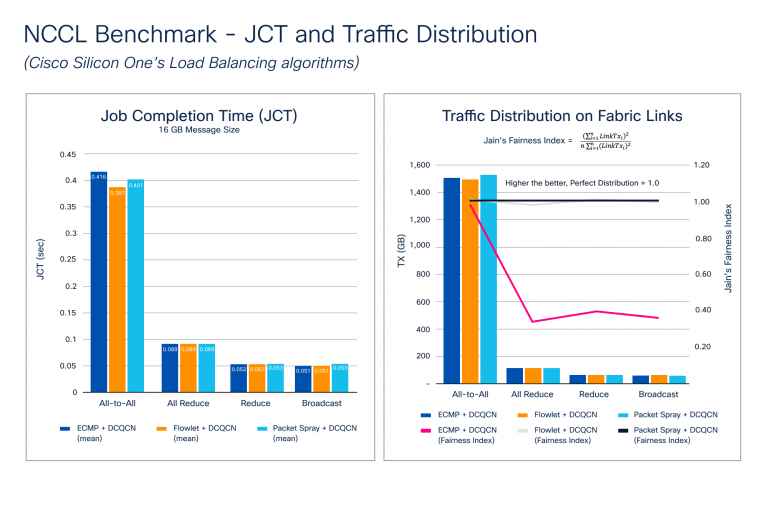
Determine 2 illustrates how the NCCL benchmarks stack up in opposition to totally different congestion avoidance options. We examined the commonest collectives with a number of totally different message sizes to focus on these metrics. The outcomes present that JCT improves with DLB and packet spray for All-to-All, which causes essentially the most congestion as a result of nature of communication. Though JCT is essentially the most understood metric from an software’s perspective, JCT doesn’t present how successfully the community is utilized—one thing the infrastructure group must know. This information may assist them to:
- Enhance the community utilization to get higher JCT
- Know what number of workloads can share the community material with out adversely impacting JCT
- Plan for capability as use instances enhance
To gauge community material utilization, we calculated Jain’s Equity Index, the place LinkTxᵢ is the quantity of transmitted visitors on material hyperlink:

The index worth ranges from 0.0 to 1.0, with greater values being higher. A price of 1.0 represents the proper distribution. The Visitors Distribution on Cloth Hyperlinks chart in Determine 2 exhibits how DLB and packet spray algorithms create a near-perfect Jain’s Equity Index, so visitors distribution throughout the community material is sort of excellent. ECMP makes use of static hashing, and relying on circulation entropy, it might result in visitors polarization, inflicting micro-congestion and negatively affecting JCT.
Silicon One versus NVIDIA Spectrum-X and InfiniBand
The NCCL Benchmark – Aggressive Evaluation (Determine 3) exhibits how Cisco Silicon One performs in opposition to NVIDIA Spectrum-X and InfiniBand applied sciences. The information for NVIDIA was taken from the SemiAnalysis publication. Notice that Cisco doesn’t understand how these checks had been carried out, however we do know that the cluster measurement and GPU to community material connectivity is much like the Cisco Zeus Cluster.
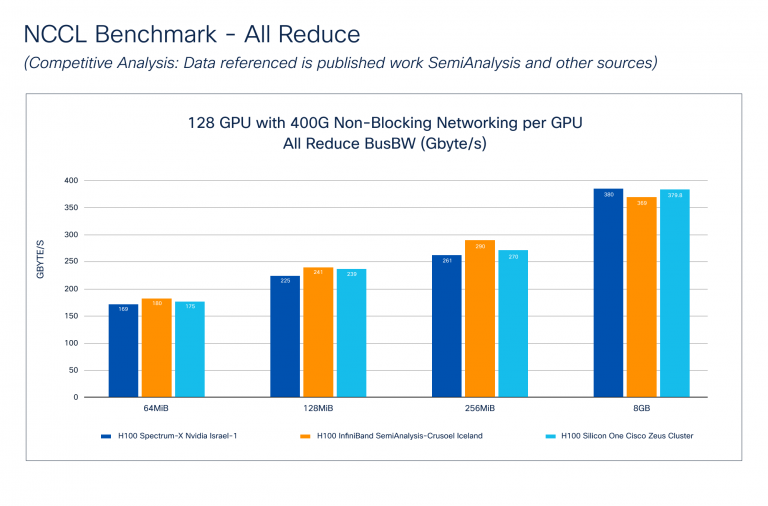
Bus Bandwidth (Bus BW) benchmarks the efficiency of collective communication by measuring the velocity of operations involving a number of GPUs. Every collective has a selected mathematical equation reported throughout benchmarking. Determine 3 exhibits that Cisco Silicon One – All Cut back performs comparably to NVIDIA Spectrum-X and InfiniBand throughout varied message sizes.
Community material efficiency evaluation
The IBPerf Benchmark compares RDMA efficiency in opposition to ECMP, DLB, and packet spray, that are essential for assessing community material efficiency. Incast situations, the place a number of GPUs ship knowledge to 1 GPU, typically trigger congestion. We simulated these situations utilizing IBPerf instruments.
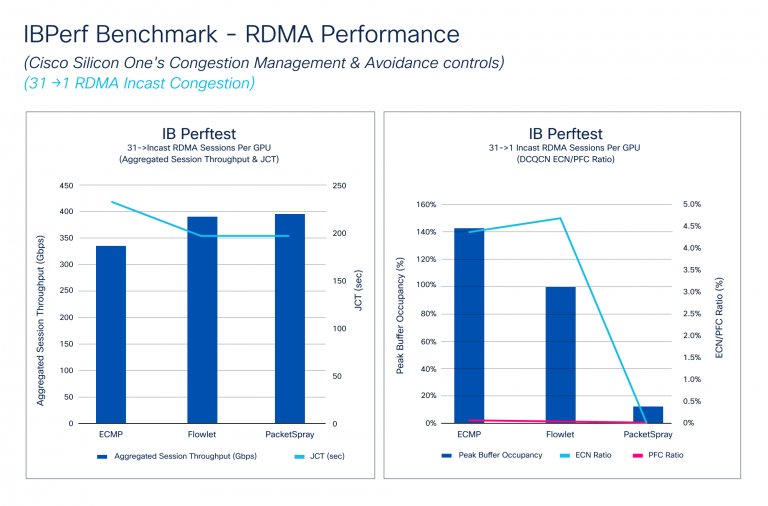
Determine 4 exhibits how Aggregated Session Throughput and JCT reply to totally different congestion avoidance algorithms: ECMP, DLB, and packet spray. DLB and packet spray attain Hyperlink Bandwidth, bettering JCT. It additionally illustrates how DCQCN handles micro-congestions, with PFC and ECN ratios bettering with DLB and considerably dropping with packet spray. Though JCT improves barely from DLB to packet spray, the ECN ratio drops dramatically as a result of packet spray’s splendid visitors distribution.
Coaching and inference benchmark
The MLPerf Benchmark – Coaching and Inference, revealed by the MLCommons group, goals to allow truthful comparability of AI/ML techniques and options.
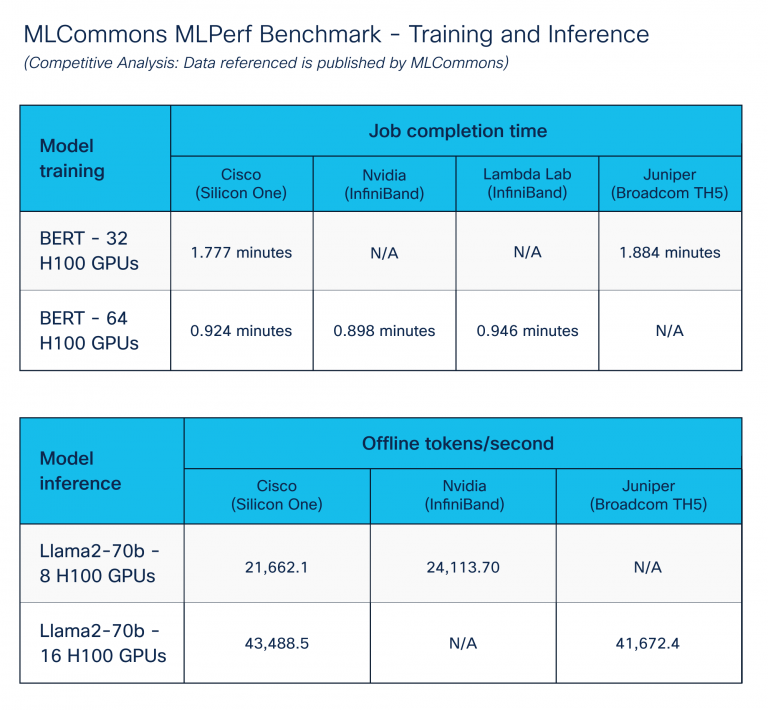
We targeted on AI/ML knowledge heart options by executing coaching and inference benchmarks. To realize optimum outcomes, we extensively tuned throughout compute, storage, and networking elements utilizing congestion administration options of Cisco Silicon One. Determine 5 exhibits comparable efficiency throughout varied platform distributors. Cisco Silicon One with Ethernet performs like different vendor options for Ethernet.
Conclusion
Our deep dive into Ethernet and InfiniBand inside AI/ML environments highlights the exceptional prowess of Cisco Silicon One in tackling congestion and boosting efficiency. These revolutionary developments showcase the unwavering dedication of Cisco to offer sturdy, high-performance networking options that meet the rigorous calls for of in the present day’s AI/ML purposes.
Many due to Vijay Tapaskar, Will Eatherton, and Kevin Wollenweber for his or her assist on this benchmarking course of.
Discover safe AI infrastructure
Uncover safe, scalable, and high-performance AI infrastructure it’s essential develop, deploy, and handle AI workloads securely whenever you select Cisco Safe AI Manufacturing unit with NVIDIA.
Share: