Organizations face an ever-increasing must course of and analyze knowledge in actual time. Conventional batch processing strategies not suffice in a world the place instantaneous insights and quick responses to market adjustments are essential for sustaining aggressive benefit. Streaming knowledge has emerged because the cornerstone of recent knowledge architectures, serving to companies seize, course of, and act upon knowledge because it’s generated.
As prospects transfer from batch to real-time processing for streaming knowledge, organizations are going through one other problem: scaling knowledge administration throughout the enterprise, as a result of the centralized knowledge platform can turn into the bottleneck. Information mesh for streaming knowledge has emerged as an answer to deal with this problem, constructing on the next rules:
- Distributed domain-driven structure – Transferring away from centralized knowledge groups to domain-specific possession
- Information as a product – Treating knowledge as a first-class product with clear possession and high quality requirements
- Self-serve knowledge infrastructure – Enabling domains to handle their knowledge independently
- Federated knowledge governance – Following international requirements and insurance policies whereas permitting area autonomy
A streaming mesh applies these rules to real-time knowledge motion and processing. This mesh is a contemporary architectural strategy that permits real-time knowledge motion throughout decentralized domains. It supplies a versatile, scalable framework for steady knowledge move whereas sustaining the information mesh rules of area possession and self-service capabilities. A streaming mesh represents a contemporary strategy to knowledge integration and distribution, breaking down conventional silos and serving to organizations create extra dynamic, responsive knowledge ecosystems.
AWS supplies two major options for streaming ingestion and storage: Amazon Managed Streaming for Apache Kafka (Amazon MSK) or Amazon Kinesis Information Streams. These companies are key to constructing a streaming mesh on AWS. On this publish, we discover the right way to construct a streaming mesh utilizing Kinesis Information Streams.
Kinesis Information Streams is a serverless streaming knowledge service that makes it easy to seize, course of, and retailer knowledge streams at scale. The service can constantly seize gigabytes of information per second from lots of of 1000’s of sources, making it excellent for constructing streaming mesh architectures. Key options embody automated scaling, on-demand provisioning, built-in safety controls, and the flexibility to retain knowledge for as much as one year for replay functions.
Advantages of a streaming mesh
A streaming mesh can ship the next advantages:
- Scalability – Organizations can scale from processing 1000’s to tens of millions of occasions per second utilizing managed scaling capabilities corresponding to Kinesis Information Streams on-demand, whereas sustaining clear operations for each producers and customers.
- Velocity and architectural simplification – Streaming mesh permits real-time knowledge flows, assuaging the necessity for advanced orchestration and extract, rework, and cargo (ETL) processes. Information is streamed straight from supply to customers because it’s produced, simplifying the general structure. This strategy replaces intricate point-to-point integrations and scheduled batch jobs with a streamlined, real-time knowledge spine. For instance, as a substitute of working nightly batch jobs to synchronize stock knowledge of bodily items throughout areas, a streaming mesh permits for fast stock updates throughout all programs as gross sales happen, considerably decreasing architectural complexity and latency.
- Information synchronization – A streaming mesh captures supply system adjustments one time and permits a number of downstream programs to independently course of the identical knowledge stream. As an illustration, a single order processing stream can concurrently replace stock programs, delivery companies, and analytics platforms whereas sustaining replay functionality, minimizing redundant integrations and offering knowledge consistency.
The next personas have distinct duties within the context of a streaming mesh:
- Producers – Producers are liable for producing and emitting knowledge merchandise into the streaming mesh. They’ve full possession over the information merchandise they generate and should be sure these knowledge merchandise adhere to predefined knowledge high quality and format requirements. Moreover, producers are tasked with managing the schema evolution of the streaming knowledge, whereas additionally assembly service degree agreements for knowledge supply.
- Customers – Customers are liable for consuming and processing knowledge merchandise from the streaming mesh. They depend on the information merchandise supplied by producers to help their functions or analytics wants.
- Governance – Governance is liable for sustaining each the operational well being and safety of the streaming mesh platform. This consists of managing scalability to deal with altering workloads, implementing knowledge retention insurance policies, and optimizing useful resource utilization for effectivity. Additionally they oversee safety and compliance, implementing correct entry management, knowledge encryption, and adherence to regulatory requirements.
The streaming mesh establishes a standard platform that permits seamless collaboration between producers, customers, and governance groups. By clearly defining duties and offering self-service capabilities, it removes conventional integration limitations whereas sustaining safety and compliance. This strategy helps organizations break down knowledge silos and obtain extra environment friendly, versatile knowledge utilization throughout the enterprise.A streaming mesh structure consists of two key constructs: stream storage and the stream processor. Stream storage serves all three key personas—governance, producers, and customers—by offering a dependable, scalable, on-demand platform for knowledge retention and distribution.
The stream processor is crucial for customers studying and remodeling the information. Kinesis Information Streams integrates seamlessly with numerous processing choices. AWS Lambda can learn from a Kinesis knowledge stream via occasion supply mapping, which is a Lambda useful resource that reads gadgets from the stream and invokes a Lambda perform with batches of data. Different processing choices embody the Kinesis Consumer Library (KCL) for constructing {custom} shopper functions, Amazon Managed Service for Apache Flink for advanced stream processing at scale, Amazon Information Firehose, and extra. To study extra, consult with Learn knowledge from Amazon Kinesis Information Streams.
This mixture of storage and versatile processing capabilities helps the various wants of a number of personas whereas sustaining operational simplicity.
Frequent entry patterns for constructing a streaming mesh
When constructing a streaming mesh, you must contemplate knowledge ingestion, governance, entry management, storage, schema management, and processing. When implementing the elements that make up the streaming mesh, you have to correctly deal with the wants of the personas outlined within the earlier part: producer, shopper, and governance. A key consideration in streaming mesh architectures is the truth that producers and customers may also exist exterior of AWS solely. On this publish, we look at the important thing eventualities illustrated within the following diagram. Though the diagram has been simplified for readability, it highlights crucial eventualities in a streaming mesh structure:
- Exterior sharing – This includes producers or customers exterior of AWS
- Inside sharing – This includes producers and customers inside AWS, doubtlessly throughout completely different AWS accounts or AWS Areas
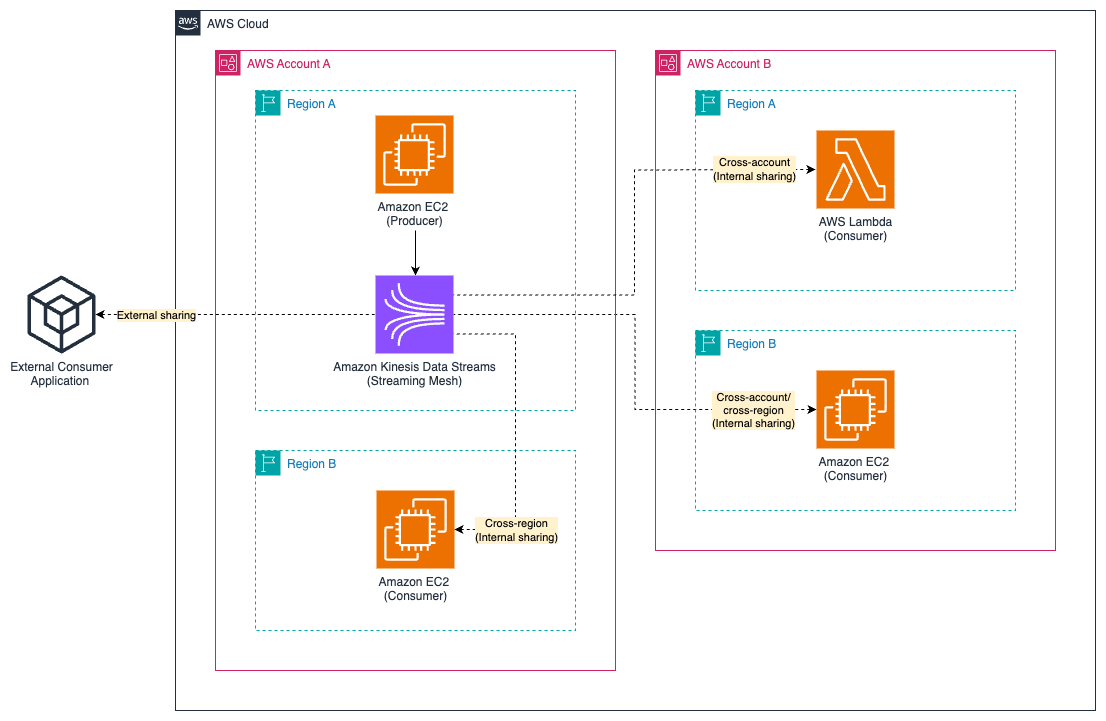
Constructing a streaming mesh on a self-managed streaming answer that facilitates inner and exterior sharing will be difficult as a result of producers and customers require the suitable service discovery, community connectivity, safety, and entry management to have the ability to work together with the mesh. This could contain implementing advanced networking options corresponding to VPN connections with authentication and authorization mechanisms to help safe connectivity. As well as, you have to contemplate the entry sample of the customers when constructing the streaming mesh.The next are frequent entry patterns:
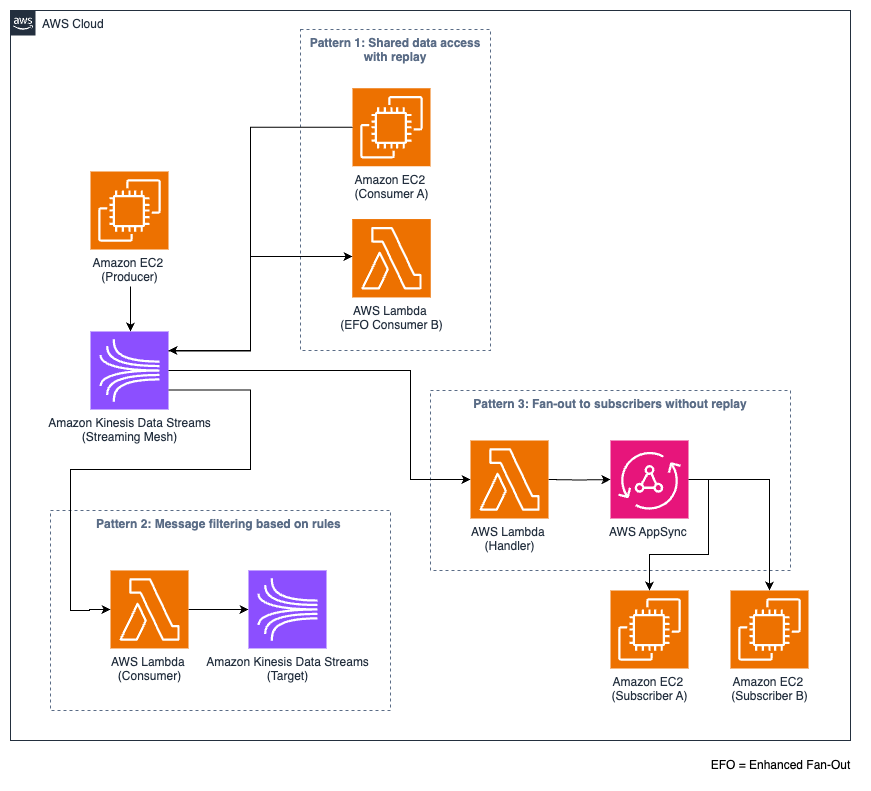
- Shared knowledge entry with replay – This sample permits a number of (customary or enhanced fan-out) customers to entry the identical knowledge stream in addition to the flexibility to replay knowledge as wanted. For instance, a centralized log stream would possibly serve numerous groups: safety operations for risk detection, IT operations for system troubleshooting, or improvement groups for debugging. Every group can entry and replay the identical log knowledge for his or her particular wants.
- Messaging filtering primarily based on guidelines – On this sample, you have to filter the information stream, and customers are solely studying a subset of the information stream. The filtering relies on predefined guidelines on the column or row degree.
- Fan-out to subscribers with out replay – This sample is designed for real-time distribution of messages to a number of subscribers with every subscriber or shopper. The messages are delivered below at-most-once semantics and will be dropped or deleted after consumption. The subscribers can’t replay the occasions. The information is consumed by companies corresponding to AWS AppSync or different GraphQL-based APIs utilizing WebSockets.
The next diagram illustrates these entry patterns.
Construct a streaming mesh utilizing Kinesis Information Streams
When constructing a streaming mesh that includes inner and exterior sharing, you should use Kinesis Information Streams. This service presents a built-in API layer that ship safe and extremely accessible HTTP/S endpoints accessible via the Kinesis API. Producers and customers can securely write and browse from the Kinesis Information Streams endpoints utilizing the AWS SDK, the Amazon Kinesis Producer Library (KPL), or Kinesis Consumer Library (KCL), assuaging the necessity for {custom} REST proxies or extra API infrastructure.
Safety is inherently built-in via AWS Id and Entry Administration (IAM), supporting fine-grained entry management that may be centrally managed. You may as well use attribute-based entry management (ABAC) with stream tags assigned to Kinesis Information Streams assets for managing entry management to the streaming mesh, as a result of ABAC is especially useful in advanced and scaling environments. As a result of ABAC is attribute-based, it permits dynamic authorization for knowledge producers and customers in actual time, mechanically adapting entry permissions as organizational and knowledge necessities evolve. As well as, Kinesis Information Streams supplies built-in fee limiting, request throttling, and burst dealing with capabilities.
Within the following sections, we revisit the beforehand talked about frequent entry patterns for customers within the context of a streaming mesh and focus on the right way to construct the patterns utilizing Kinesis Information Streams.
Shared knowledge entry with replay
Kinesis Information Stream has built-in help for the shared knowledge entry with replay sample. The next diagram illustrates this entry sample, specializing in same-account, cross-account, and exterior customers.
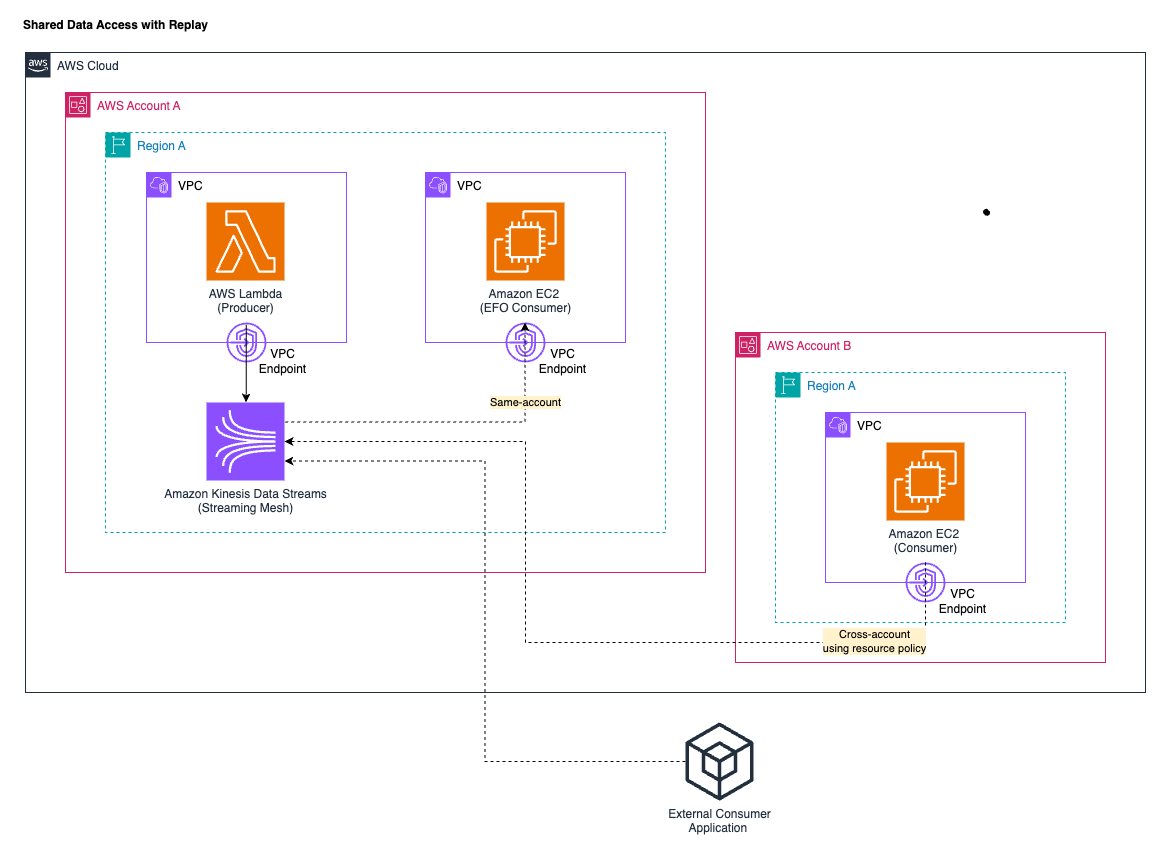
Governance
Once you create your knowledge mesh with Kinesis Information Streams, you must create a knowledge stream with the suitable variety of provisioned shards or on-demand mode primarily based in your throughput wants. On-demand mode must be thought-about for extra dynamic workloads. Word that message ordering can solely be assured on the shard degree.
Configure the information retention interval of as much as one year. The default retention interval is 24 hours and will be modified utilizing the Kinesis Information Streams API. This fashion, the information is retained for the required retention interval and will be replayed by the customers. Word that there’s an extra charge for long-term knowledge retention charge past the default 24 hours.
To reinforce community safety, you should use interface VPC endpoints. They be sure the visitors between your producers and customers residing in your digital non-public cloud (VPC) and your Kinesis knowledge streams stay non-public and don’t traverse the web. To offer cross-account entry to your Kinesis knowledge stream, you should use useful resource insurance policies or cross-account IAM roles. Useful resource-based insurance policies are straight hooked up to the useful resource that you simply wish to share entry to, such because the Kinesis knowledge stream, and a cross-account IAM position in a single AWS account delegates particular permissions, corresponding to learn entry to the Kinesis knowledge stream, to a different AWS account. On the time of writing, Kinesis Information Streams doesn’t help cross-Area entry.
Kinesis Information Streams enforces quotas on the shard and stream degree to forestall useful resource exhaustion and preserve constant efficiency. Mixed with shard-level Amazon CloudWatch metrics, these quotas assist determine sizzling shards and forestall noisy neighbor eventualities that would influence total stream efficiency.
Producer
You may construct producer functions utilizing the AWS SDK or the KPL. Utilizing the KPL can facilitate the writing as a result of it supplies built-in capabilities corresponding to aggregation, retry mechanisms, pre-shard fee limiting, and elevated throughput. The KPL can incur an extra processing delay. It is best to contemplate integrating Kinesis Information Streams with the AWS Glue Schema Registry to centrally management uncover, management, and evolve schemas and ensure produced knowledge is constantly validated by a registered schema.
You could be sure your producers can securely connect with the Kinesis API whether or not from inside or exterior the AWS Cloud. Your producer can doubtlessly reside in the identical AWS account, throughout accounts, or exterior of AWS solely. Usually, you need your producers to be as shut as attainable to the Area the place your Kinesis knowledge stream is working to attenuate latency. You may allow cross-account entry by attaching a resource-based coverage to your Kinesis knowledge stream that grants producers in different AWS accounts permission to put in writing knowledge. On the time of writing, the KPL doesn’t help specifying a stream Amazon Useful resource Title (ARN) when writing to a knowledge stream. You could use the AWS SDK to put in writing to a cross-account knowledge stream (for extra particulars, see Share your knowledge stream with one other account). There are additionally limitations for cross-Area help if you wish to produce knowledge to Kinesis Information Streams from Information Firehose in a distinct Area utilizing the direct integration.
To securely entry the Kinesis knowledge stream, producers want legitimate credentials. Credentials shouldn’t be saved straight within the consumer software. As a substitute, you must use IAM roles to offer non permanent credentials utilizing the AssumeRole API via AWS Safety Token Service (AWS STS). For producers exterior of AWS, it’s also possible to contemplate AWS IAM Roles Wherever to acquire non permanent credentials in IAM. Importantly, solely the minimal permissions which might be required to put in writing the stream must be granted. With ABAC help for Kinesis Information Streams, particular API actions will be allowed or denied when the tag on the information stream matches the tag outlined within the IAM position precept.
Client
You may construct customers utilizing the KCL or AWS SDK. The KCL can simplify studying from Kinesis knowledge streams as a result of it mechanically handles advanced duties corresponding to checkpointing and cargo balancing throughout a number of customers. This shared entry sample will be carried out utilizing customary in addition to enhanced fan-out customers. In the usual consumption mode, the learn throughput is shared by all customers studying from the identical shard. The utmost throughput for every shard is 2 MBps. Data are delivered to the customers in a pull mannequin over HTTP utilizing the GetRecords API. Alternatively, with enhanced fan-out, customers can use the SubscribeToShard API with knowledge pushed over HTTP/2 for lower-latency supply. For extra particulars, see Develop enhanced fan-out customers with devoted throughput.
Each consumption strategies permit customers to specify the shard and sequence quantity from which to start out studying, enabling knowledge replay from completely different factors throughout the retention interval. Kinesis Information Streams recommends to concentrate on the shard restrict that’s shared and use fan-out when attainable. KCL 2.0 or later makes use of enhanced fan-out by default, and you have to particularly set the retrieval mode to POLLING to make use of the usual consumption mannequin. Concerning connectivity and entry management, you must intently observe what’s already recommended for the producer aspect.
Messaging filtering primarily based on guidelines
Though Kinesis Information Streams doesn’t present built-in filtering capabilities, you may implement this sample by combining it with Lambda or Managed Service for Apache Flink. For this publish, we concentrate on utilizing Lambda to filter messages.
Governance and producer
Governance and producer personas ought to observe the very best practices already outlined for the shared knowledge entry with replay sample, as described within the earlier part.
Client
It is best to create a Lambda perform that consumes (shared throughput or devoted throughput) from the stream and create a Lambda occasion supply mapping with your filter standards. On the time of writing, Lambda helps occasion supply mappings for Amazon DynamoDB, Kinesis Information Streams, Amazon MQ, Managed Streaming for Apache Kafka or self-managed Kafka, and Amazon Easy Queue Service (Amazon SQS). Each the ingested knowledge data and your filter standards for the information area should be in a sound JSON format for Lambda to correctly filter the incoming messages from Kinesis sources.
When utilizing enhanced fan-out, you configure a Kinesis dedicated-throughput shopper to behave because the set off on your Lambda perform. Lambda then filters the (aggregated) data and passes solely these data that meet your filter standards.
Fan-out to subscribers with out replay
When distributing streaming knowledge to a number of subscribers with out the flexibility to replay, Kinesis Information Streams helps an middleman sample that’s significantly efficient for net and cellular purchasers needing real-time updates. This sample introduces an middleman service to bridge between Kinesis Information Streams and the subscribers, processing data from the information stream (utilizing an ordinary or enhanced fan-out shopper mannequin) and delivering the information data to the subscribers in actual time. Subscribers don’t straight work together with the Kinesis API.
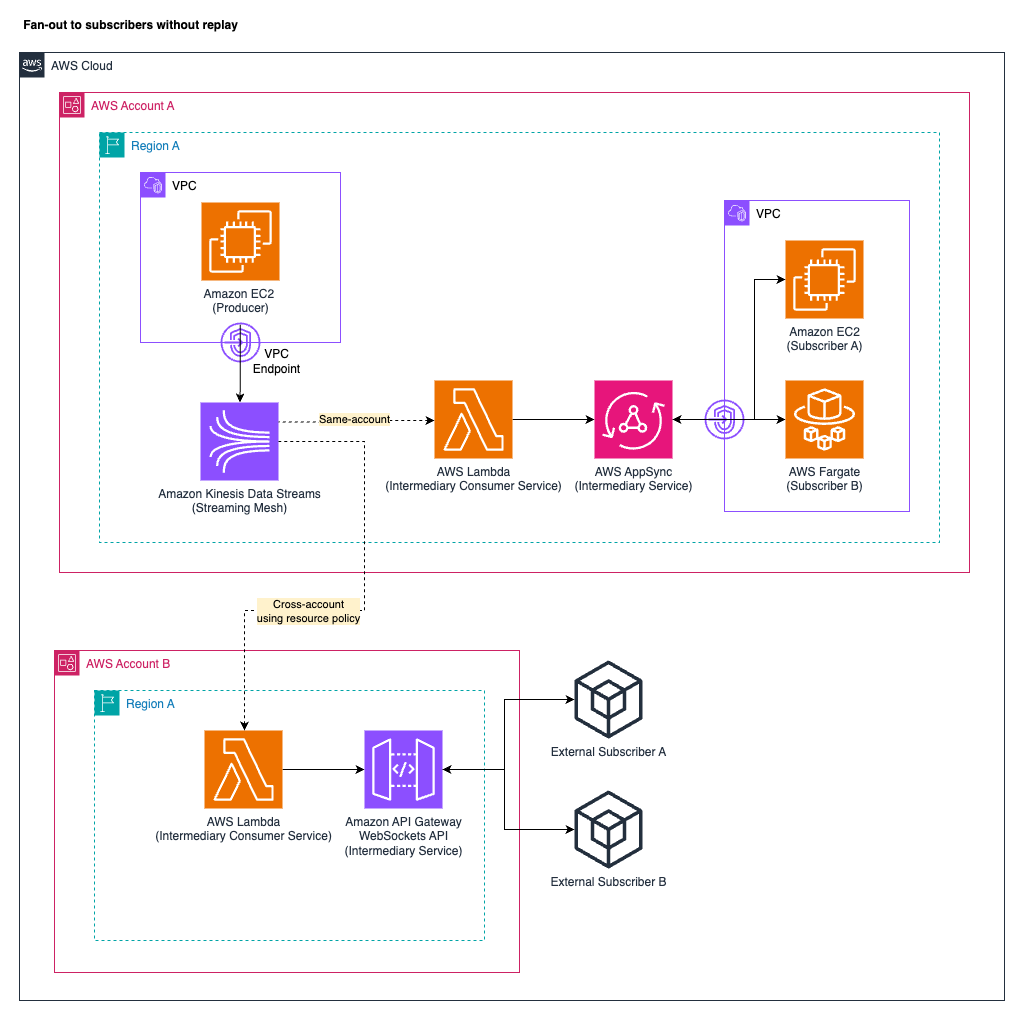
A typical strategy makes use of GraphQL gateways corresponding to AWS AppSync, WebSockets API companies just like the Amazon API Gateway WebSockets API, or different appropriate companies that make the information accessible to the subscribers. The information is distributed to the subscribers via networking connections corresponding to WebSockets.
The next diagram illustrates the entry sample of fan-out to subscribers with out replay. The diagram shows the managed AWS companies AppSync and API Gateway as middleman shopper choices for illustration functions.
Governance and producer
Governance and producer personas ought to observe the very best practices already outlined for the shared knowledge entry with replay sample.
Client
This consumption mannequin operates otherwise from conventional Kinesis consumption patterns. Subscribers join via networking connections corresponding to WebSockets to the middleman service and obtain the information data in actual time with out the flexibility to set offsets, replay historic knowledge, or management knowledge positioning. The supply follows at-most-once semantics, the place messages is perhaps misplaced if subscribers disconnect, as a result of consumption is ephemeral with out persistence for particular person subscribers. The middleman shopper service should be designed for prime efficiency, low latency, and resilient message distribution. Potential middleman service implementations vary from managed companies corresponding to AppSync or API Gateway to custom-built options like WebSocket servers or GraphQL subscription companies. As well as, this sample requires an middleman shopper service corresponding to Lambda that reads the information from the Kinesis knowledge stream and instantly writes it to the middleman service.
Conclusion
This publish highlighted the advantages of a streaming mesh. We demonstrated why Kinesis Information Streams is especially suited to facilitate a safe and scalable streaming mesh structure for inner in addition to exterior sharing. The explanations embody the service’s built-in API layer, complete safety via IAM, versatile networking connection choices, and versatile consumption fashions. The streaming mesh patterns demonstrated—shared knowledge entry with replay, message filtering, and fan-out to subscribers—showcase how Kinesis Information Streams successfully helps producers, customers, and governance groups throughout inner and exterior boundaries.
For extra info on the right way to get began with Kinesis Information Streams, consult with Getting began with Amazon Kinesis Information Streams. For different posts on Kinesis Information Streams, flick thru the AWS Massive Information Weblog.
Concerning the authors