In synthetic intelligence, evaluating the efficiency of language fashions presents a singular problem. Not like picture recognition or numerical predictions, language high quality evaluation doesn’t yield to easy binary measurements. Enter BLEU (Bilingual Analysis Understudy), a metric that has turn out to be the cornerstone of machine translation analysis since its introduction by IBM researchers in 2002.
BLEU stands for a breakthrough in pure language processing for it’s the very first analysis technique that manages to attain a fairly excessive correlation with human judgment and but retains the effectivity of automation. This text investigates the mechanics of BLEU, its functions, its limitations, and what the long run holds for it in an more and more AI-driven world that’s preoccupied with richer nuances in language-generated output.
Be aware: It is a sequence of Analysis Metrics of LLMs and I might be protecting all of the Prime 15 LLM Analysis Metrics to Discover in 2025.
The Genesis of BLEU Metric: A Historic Perspective
Previous to BLEU, evaluating machine translations was primarily guide—a resource-intensive course of requiring lingual specialists to manually assess every output. The introduction of BLEU by Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu at IBM Analysis represented a paradigm shift. Their 2002 paper, “BLEU: a Methodology for Automated Analysis of Machine Translation,” proposed an automatic metric that would rating translations with exceptional alignment to human judgment.
The timing was pivotal. As statistical machine translation techniques have been gaining momentum, the sector urgently wanted standardized analysis strategies. BLEU crammed this void, providing a reproducible, language-independent scoring mechanism that facilitated significant comparisons between totally different translation techniques.
How Does BLEU Metric Work?
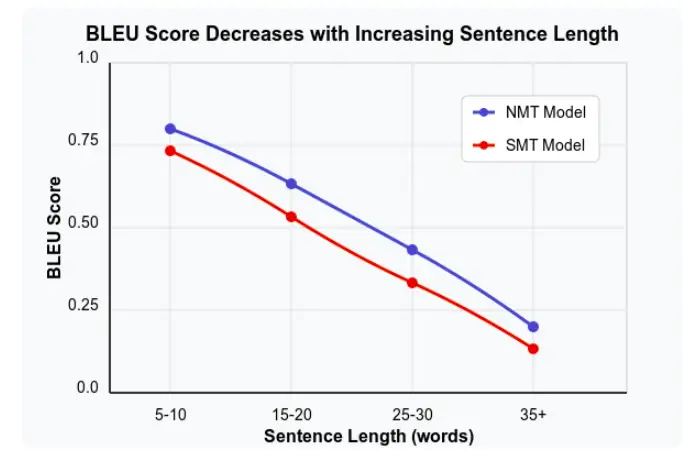
At its core, BLEU operates on a easy precept: evaluating machine-generated translations towards reference translations (usually created by human translators). It has been noticed that the BLEU rating decreases because the sentence size will increase, although it would range relying on the mannequin used for translations. Nevertheless, its implementation includes subtle computational linguistics ideas:
N-gram Precision
BLEU’s basis lies in n-gram precision—the share of phrase sequences within the machine translation that seem in any reference translation. Moderately than limiting itself to particular person phrases (unigrams), BLEU examines contiguous sequences of varied lengths:
- Unigrams (single phrases) Modified Precision: Measuring vocabulary accuracy
- Bigrams (two-word sequences) Modified Precision: Capturing primary phrasal correctness
- Trigrams and 4-grams Modified Precision: Evaluating grammatical construction and phrase order
BLEU calculates modified precision for every n-gram size by:
- Counting n-gram matches between the candidate and reference translations
- Making use of a “clipping” mechanism to forestall overinflation from repeated phrases
- Dividing by the overall variety of n-grams within the candidate translation
Brevity Penalty
To forestall techniques from gaming the metric by producing extraordinarily brief translations (which may obtain excessive precision by together with solely simply matched phrases), BLEU incorporates a brevity penalty that reduces scores for translations shorter than their references.
The penalty is calculated as:
BP = exp(1 - r/c) if c < r
1 if c ≥ rThe place r is the reference size and c is the candidate translation size.
The Last BLEU Rating
The ultimate BLEU rating combines these elements right into a single worth between 0 and 1 (typically offered as a proportion):
BLEU = BP × exp(∑ wn log pn)The place:
- BP is the brevity penalty
- wn represents weights for every n-gram precision (usually uniform)
- pn is the modified precision for n-grams of size n
Implementing BLEU Metric
Understanding BLEU conceptually is one factor; implementing it accurately requires consideration to element. Right here’s a sensible information to utilizing BLEU successfully:
Required Inputs
BLEU requires two main inputs:
- Candidate translations: The machine-generated translations you need to consider
- Reference translations: A number of human-created translations for every supply sentence
Each inputs should endure constant preprocessing:
- Tokenization: Breaking textual content into phrases or subwords
- Case normalization: Sometimes lowercasing all textual content
- Punctuation dealing with: Both eradicating punctuation or treating punctuation marks as separate tokens
Implementation Steps
A typical BLEU implementation follows these steps:
- Preprocess all translations: Apply constant tokenization and normalization
- Calculate n-gram precision for n=1 to N (usually N=4):
- Depend all n-grams within the candidate translation
- Depend matching n-grams in reference translations (with clipping)
- Compute precision as (matches / complete candidate n-grams)
- Calculate brevity penalty:
- Decide efficient reference size (shortest ref size in authentic BLEU)
- In comparison with the candidate size
- Apply brevity penalty method
- Mix elements into the ultimate rating:
- Apply weighted geometric imply of n-gram precisions
- Multiply by brevity penalty
A number of libraries present ready-to-use BLEU implementations:
NLTK: Python’s Pure Language Toolkit presents a easy BLEU implementation
from nltk.translate.bleu_score import sentence_bleu, corpus_bleu
from nltk.translate.bleu_score import SmoothingFunction
# Create a smoothing perform to keep away from zero scores resulting from lacking n-grams
smoothie = SmoothingFunction().method1
# Instance 1: Single reference, good match
reference = [['this', 'is', 'a', 'test']]
candidate = ['this', 'is', 'a', 'test']
rating = sentence_bleu(reference, candidate)
print(f"Excellent match BLEU rating: {rating}")
# Instance 2: Single reference, partial match
reference = [['this', 'is', 'a', 'test']]
candidate = ['this', 'is', 'test']
# Utilizing smoothing to keep away from zero scores
rating = sentence_bleu(reference, candidate, smoothing_function=smoothie)
print(f"Partial match BLEU rating: {rating}")
# Instance 3: A number of references (corrected format)
references = [[['this', 'is', 'a', 'test']], [['this', 'is', 'an', 'evaluation']]]
candidates = [['this', 'is', 'an', 'assessment']]
# The format for corpus_bleu is totally different - references want restructuring
correct_references = [[['this', 'is', 'a', 'test'], ['this', 'is', 'an', 'evaluation']]]
rating = corpus_bleu(correct_references, candidates, smoothing_function=smoothie)
print(f"A number of reference BLEU rating: {rating}")Output
Excellent match BLEU rating: 1.0
Partial match BLEU rating: 0.19053627645285995
A number of reference BLEU rating: 0.3976353643835253
SacreBLEU: A standardized BLEU implementation that addresses reproducibility issues
import sacrebleu
# For sentence-level BLEU with SacreBLEU
reference = ["this is a test"] # Checklist containing a single reference
candidate = "this can be a check" # String containing the speculation
rating = sacrebleu.sentence_bleu(candidate, reference)
print(f"Excellent match SacreBLEU rating: {rating}")
# Partial match instance
reference = ["this is a test"]
candidate = "that is check"
rating = sacrebleu.sentence_bleu(candidate, reference)
print(f"Partial match SacreBLEU rating: {rating}")
# A number of references instance
references = ["this is a test", "this is a quiz"] # Checklist of a number of references
candidate = "that is an examination"
rating = sacrebleu.sentence_bleu(candidate, references)
print(f"A number of references SacreBLEU rating: {rating}")Output
Excellent match SacreBLEU rating: BLEU = 100.00 100.0/100.0/100.0/100.0 (BP =
1.000 ratio = 1.000 hyp_len = 4 ref_len = 4)Partial match SacreBLEU rating: BLEU = 45.14 100.0/50.0/50.0/0.0 (BP = 0.717
ratio = 0.750 hyp_len = 3 ref_len = 4)A number of references SacreBLEU rating: BLEU = 31.95 50.0/33.3/25.0/25.0 (BP =
1.000 ratio = 1.000 hyp_len = 4 ref_len = 4)
Hugging Face Consider: Fashionable implementation built-in with ML pipelines
from consider import load
bleu = load('bleu')
# Instance 1: Excellent match
predictions = ["this is a test"]
references = [["this is a test"]]
outcomes = bleu.compute(predictions=predictions, references=references)
print(f"Excellent match HF Consider BLEU rating: {outcomes}")
# Instance 2: Multi-sentence analysis
predictions = ["the cat is on the mat", "there is a dog in the park"]
references = [["the cat sits on the mat"], ["a dog is running in the park"]]
outcomes = bleu.compute(predictions=predictions, references=references)
print(f"Multi-sentence HF Consider BLEU rating: {outcomes}")
# Instance 3: Extra advanced real-world translations
predictions = ["The agreement on the European Economic Area was signed in August 1992."]
references = [["The agreement on the European Economic Area was signed in August 1992.", "An agreement on the European Economic Area was signed in August of 1992."]]
outcomes = bleu.compute(predictions=predictions, references=references)
print(f"Complicated instance HF Consider BLEU rating: {outcomes}")Output
Excellent match HF Consider BLEU rating: {'bleu': 1.0, 'precisions': [1.0, 1.0,
1.0, 1.0], 'brevity_penalty': 1.0, 'length_ratio': 1.0,
'translation_length': 4, 'reference_length': 4}Multi-sentence HF Consider BLEU rating: {'bleu': 0.0, 'precisions':
[0.8461538461538461, 0.5454545454545454, 0.2222222222222222, 0.0],
'brevity_penalty': 1.0, 'length_ratio': 1.0, 'translation_length': 13,
'reference_length': 13}
Complicated instance HF Consider BLEU rating: {'bleu': 1.0, 'precisions': [1.0,
1.0, 1.0, 1.0], 'brevity_penalty': 1.0, 'length_ratio': 1.0,
'translation_length': 13, 'reference_length': 13}
Decoding BLEU Outputs
BLEU scores usually vary from 0 to 1 (or 0 to 100 when offered as percentages):
- 0: No matches between candidate and references
- 1 (or 100%): Excellent match with references
- Typical ranges:
- 0-15: Poor translation
- 15-30: Comprehensible however flawed translation
- 30-40: Good translation
- 40-50: Excessive-quality translation
- 50+: Distinctive translation (doubtlessly approaching human high quality)
Nevertheless, these ranges range considerably between language pairs. For example, translations between English and Chinese language usually rating decrease than English-French pairs, resulting from linguistic variations relatively than precise high quality variations.
Rating Variants
Totally different BLEU implementations might produce various scores resulting from:
- Smoothing strategies: Addressing zero precision values
- Tokenization variations: Particularly vital for languages with out clear phrase boundaries
- N-gram weighting schemes: Customary BLEU makes use of uniform weights, however alternate options exist
For extra data watch this video:
Past Translation: BLEU’s Increasing Functions
Whereas BLEU was designed for machine translation analysis, its affect has prolonged all through pure language processing:
- Textual content Summarization – Researchers have tailored BLEU to guage automated summarization techniques, evaluating model-generated summaries towards human-created references. Although summarization poses distinctive challenges—resembling the necessity for semantic preservation relatively than actual wording—modified BLEU variants have confirmed invaluable on this area.
- Dialogue Programs and Chatbots – Conversational AI builders use BLEU to measure response high quality in dialogue techniques, although with vital caveats. The open-ended nature of dialog means a number of responses will be equally legitimate, making reference-based analysis significantly difficult. However, BLEU supplies a place to begin for assessing response appropriateness.
- Picture Captioning – In multimodal AI, BLEU helps consider techniques that generate textual descriptions of photographs. By evaluating model-generated captions towards human annotations, researchers can quantify caption accuracy whereas acknowledging the artistic features of description.
- Code Era – An rising software includes evaluating code era fashions, the place BLEU can measure the similarity between AI-generated code and reference implementations. This software highlights BLEU’s versatility throughout various kinds of structured language.
The Limitations: Why BLEU Isn’t Excellent?
Regardless of its widespread adoption, BLEU has well-documented limitations that researchers should think about:
- Semantic Blindness – Maybe BLEU’s most important limitation is its incapability to seize semantic equivalence. Two translations can convey equivalent meanings utilizing solely totally different phrases, but BLEU would assign a low rating to the variant that doesn’t match the reference lexically. This “surface-level” analysis can penalize legitimate stylistic decisions and various phrasings.
- Lack of Contextual Understanding – BLEU treats sentences as remoted items, disregarding document-level coherence and contextual appropriateness. This limitation turns into significantly problematic when evaluating translations of texts the place context considerably influences phrase selection and that means.
- Insensitivity to Important Errors – Not all translation errors carry equal weight. A minor word-order discrepancy may barely have an effect on comprehensibility, whereas a single mistranslated negation may reverse a sentence’s total that means. BLEU treats these errors equally, failing to tell apart between trivial and demanding errors.
- Reference Dependency – BLEU’s reliance on reference translations introduces inherent bias. The metric can’t acknowledge the advantage of a legitimate translation that considerably differs from the supplied references. This dependency additionally creates sensible challenges in low-resource languages the place acquiring a number of high-quality references is troublesome.
Past BLEU: The Evolution of Analysis Metrics
BLEU’s limitations have spurred the event of complementary metrics, every addressing particular shortcomings:
- METEOR (Metric for Analysis of Translation with Express ORdering) – METEOR enhances analysis by incorporating:
- Stemming and synonym matching to acknowledge semantic equivalence
- Express word-order analysis
- Parameterized weighting of precision and recall
- chrF (Character n-gram F-score) – This metric operates on the character degree relatively than phrase degree, making it significantly efficient for morphologically wealthy languages the place slight phrase variations can proliferate.
- BERTScore – Leveraging contextual embeddings from transformer fashions like BERT, this metric captures semantic similarity between translations and references, addressing BLEU’s semantic blindness.
- COMET (Crosslingual Optimized Metric for Analysis of Translation) – COMET makes use of neural networks educated on human judgments to foretell translation high quality, doubtlessly capturing features of translation that correlate with human notion however elude conventional metrics.
The Way forward for BLEU in an Period of Neural Machine Translation
As neural machine translation techniques more and more produce human-quality outputs, BLEU faces new challenges and alternatives:
- Ceiling Results – Prime-performing NMT techniques now obtain BLEU scores approaching or exceeding human translators on sure language pairs. This “ceiling impact” raises questions on BLEU’s continued utility in distinguishing between high-performing techniques.
- Human Parity Debates – Current claims of “human parity” in machine translation have sparked debates about analysis methodology. BLEU has turn out to be central to those discussions, with researchers questioning whether or not present metrics adequately seize translation high quality at near-human ranges.
- Customization for Domains – Totally different domains prioritize totally different features of translation high quality. Medical translations demand terminology precision, whereas advertising content material might worth artistic adaptation. Future BLEU implementations might incorporate domain-specific weightings to mirror these various priorities.
- Integration with Human Suggestions – Probably the most promising path could also be hybrid analysis approaches that mix automated metrics like BLEU with focused human assessments. These strategies may leverage BLEU’s effectivity whereas compensating for its blind spots via strategic human intervention.
Conclusion
Regardless of its limitations, BLEU stays basic to machine translation analysis and growth. Its simplicity, reproducibility, and correlation with human judgment have established it because the lingua franca of translation analysis. Whereas newer metrics tackle particular BLEU weaknesses, none has totally displaced it.
The story of BLEU displays a broader sample in synthetic intelligence: the stress between computational effectivity and nuanced analysis. As language applied sciences advance, our strategies for assessing them should evolve in parallel. BLEU’s best contribution might in the end function the muse upon which extra subtle analysis paradigms are constructed.
With the robotic mediation of communication between people, metrics resembling BLEU have grown to be not simply an act of analysis however a safeguard making certain that AI-powered language instruments fulfill human wants. Understanding BLEU Metric in all its glory and limitations is indispensable for anybody working the place know-how meets language.
Gen AI Intern at Analytics Vidhya
Division of Laptop Science, Vellore Institute of Know-how, Vellore, India
I’m presently working as a Gen AI Intern at Analytics Vidhya, the place I contribute to progressive AI-driven options that empower companies to leverage knowledge successfully. As a final-year Laptop Science pupil at Vellore Institute of Know-how, I carry a strong basis in software program growth, knowledge analytics, and machine studying to my function.
Be happy to attach with me at [email protected]
Login to proceed studying and luxuriate in expert-curated content material.