Lots of of 1000’s of consumers construct synthetic intelligence and machine studying (AI/ML) and analytics functions on AWS, ceaselessly remodeling information via a number of levels for improved question efficiency—from uncooked information to processed datasets to closing analytical tables. Information engineers should remedy complicated issues, together with detecting what information has modified in base tables, writing and sustaining transformation logic, scheduling and orchestrating workflows throughout dependencies, provisioning and managing compute infrastructure, and troubleshooting failures whereas monitoring pipeline well being. Think about an ecommerce firm the place information engineers must constantly merge clickstream logs with orders information for analytics. Every transformation requires constructing strong change detection mechanisms, writing complicated joins and aggregations, coordinating a number of workflow steps, scaling compute sources appropriately, and sustaining operational oversight—all whereas supporting information high quality and pipeline reliability. This complexity calls for months of devoted engineering effort and ongoing upkeep, making information transformation pricey and time-intensive for organizations looking for to unlock insights from their information.
To handle these challenges, AWS introduced a brand new materialized view functionality for Apache Iceberg tables within the AWS Glue Information Catalog. The brand new materialized view functionality simplifies information pipelines and accelerates information lake question efficiency. A materialized view is a managed desk within the AWS Glue Information Catalog that shops pre-computed outcomes of a question in Iceberg format that’s incrementally up to date to replicate adjustments to the underlying datasets. This alleviates the necessity to construct and keep complicated information pipelines to generate remodeled datasets and speed up question efficiency. Apache Spark engines throughout Amazon Athena, Amazon EMR, and AWS Glue assist the brand new materialized views and intelligently rewrite queries to make use of materialized views that pace up efficiency whereas lowering compute prices.
On this publish, we present you the way Iceberg materialized view works and methods to get began.
How Iceberg materialized views work
Iceberg materialized views provide a easy, managed answer constructed on acquainted SQL syntax. As an alternative of constructing complicated pipelines, you’ll be able to create materialized views utilizing commonplace SQL queries from Spark, remodeling information with aggregates, filters, and joins with out writing customized information pipelines. Change detection, incremental updates, and monitoring supply tables are robotically dealt with within the AWS Glue Information Catalog and refreshing materialized views as new information arrive, assuaging the necessity for handbook pipeline orchestration. Information transformations run on absolutely managed compute infrastructure, eradicating the burden of provisioning, scaling, or sustaining servers.
The ensuing pre-computed information is saved as Iceberg tables in an Amazon Easy Storage Service (Amazon S3) normal goal bucket, or Amazon S3 Tables buckets inside the your account, making remodeled information instantly accessible to a number of question engines, together with Athena, Amazon Redshift, and AWS optimized Spark runtime. Spark engines throughout Athena, Amazon EMR, and AWS Glue assist an computerized question rewrite performance that intelligently makes use of materialized views, delivering computerized efficiency enchancment for information processing jobs or interactive pocket book queries.
Within the following sections, we stroll via the steps to create, question, and refresh materialized views.
Pre-requisite
To comply with together with this publish, you will need to have an AWS account.
To run the instruction on Amazon EMR, full the next steps to configure the cluster:
- Launch an Amazon EMR cluster 7.12.0 or greater.
- SSH login to the first node of your Amazon EMR cluster, and run the next command to begin a Spark utility with required configurations:
To run the instruction on AWS Glue for Spark, full the next steps to configure the job:
- Create an AWS Glue model 5.1 job or greater.
- Configure a job parameter
- Key:
--conf - Worth:
spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions
- Key:
- Configure your job with the next script:
- Run the next queries utilizing Spark SQL to arrange a base desk. In AWS Glue, you’ll be able to run them via
spark.sql("QUERY STATEMENT").
Within the subsequent sections, we create a materialized view with this base desk.
If you wish to retailer your materialized views in Amazon S3 Tables as an alternative of a normal Amazon S3 bucket, confer with Appendix 1 on the finish of this publish for the configuration particulars.
Create a materialized view
To create a materialized view, run the next command:
After you create a materialized view, AWS Spark’s in-memory metadata cache wants time to populate with details about the brand new materialized view. Throughout this cache inhabitants interval, queries in opposition to the bottom desk will run usually with out utilizing the materialized view. After the cache is absolutely populated (usually inside tens of seconds), Spark robotically detects that the materialized view can fulfill the question and rewrites it to make use of the pre-computed materialized view as an alternative, enhancing efficiency.
To see this habits, run the next EXPLAIN command instantly after creating the materialized view:
The next output exhibits the preliminary end result earlier than cache inhabitants:
On this preliminary execution plan, Spark scans the base_tbl instantly (BatchScan glue_catalog.iceberg_mv.base_tbl) and runs aggregations (COUNT and SUM) on the uncooked information. That is the habits earlier than the materialized view metadata cache is populated.
After ready roughly tens of seconds for the metadata cache inhabitants, run the identical EXPLAIN command once more. The next output exhibits the first variations within the question optimization plan after cache inhabitants:
After the cache is populated, Spark now scans the materialized view (BatchScan glue_catalog.iceberg_mv.mv) as an alternative of the bottom desk. The question has been robotically rewritten to learn from the pre-computed aggregated information within the materialized view. The output particularly exhibits the aggregation features now merely sum the pre-computed values (sum(mv_order_count) and sum(mv_total_amount)) slightly than recalculating COUNT and SUM from uncooked information.
Create a materialized view with scheduling computerized refresh
By default, a newly created materialized view incorporates the preliminary question outcomes. It’s not robotically up to date when the underlying base desk information adjustments. To maintain your materialized view synchronized with the bottom desk information, you’ll be able to configure computerized refresh schedules. To allow computerized refresh, use the REFRESH EVERY clause when creating the materialized view. This clause accepts a time interval and unit, so you’ll be able to specify how ceaselessly the materialized view is up to date.
The next instance creates a materialized view that robotically refreshes each 24 hours:
You possibly can configure the refresh interval utilizing any of the next time items: SECONDS, MINUTES, HOURS, or DAYS. Select an applicable interval based mostly in your information freshness necessities and question patterns.
In case you choose extra management over when your materialized view updates, or must refresh it outdoors of the scheduled intervals, you’ll be able to set off handbook refreshes at any time. We offer detailed directions on handbook refresh choices, together with full and incremental refresh, later on this publish.
Question a materialized view
To question a materialized view in your Amazon EMR cluster and retrieve its aggregated information, you should utilize a normal SELECT assertion:
This question retrieves all rows from the materialized view. The output exhibits the aggregated buyer order counts and complete quantities. The end result shows three prospects with their respective metrics:
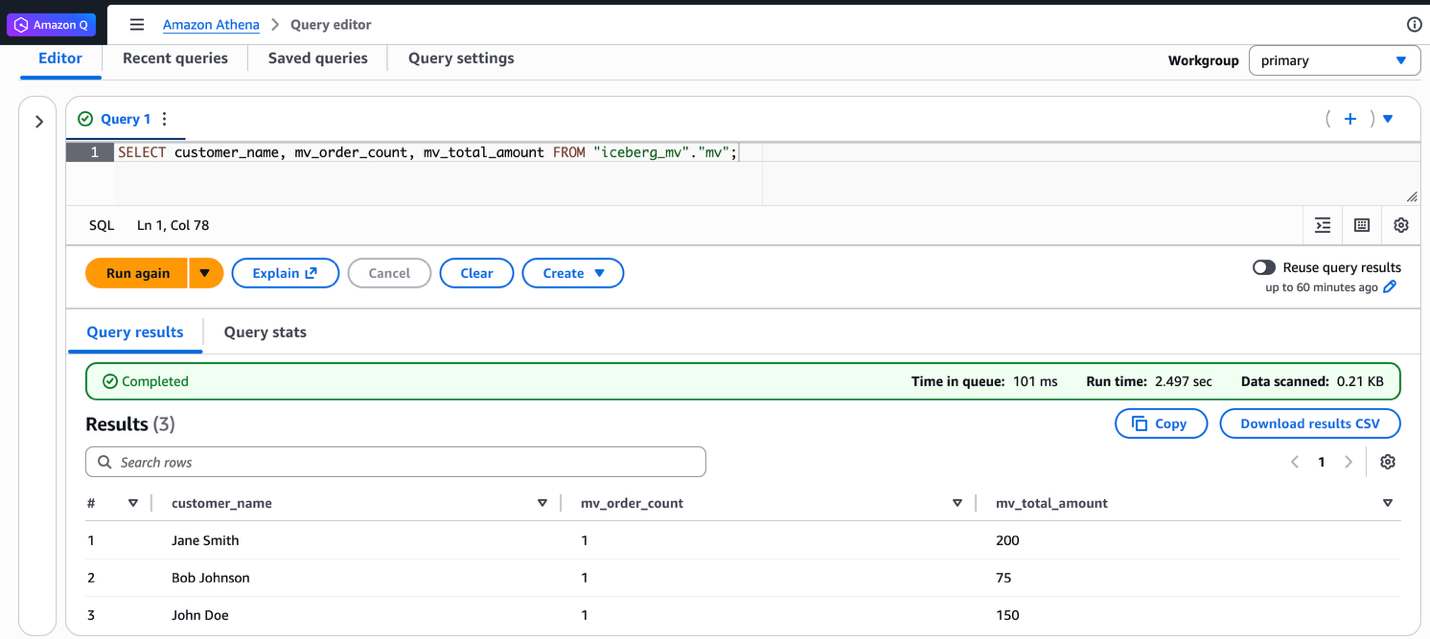
Moreover, you’ll be able to question the identical materialized view from Athena SQL. The next screenshot exhibits the identical question run on Athena and the ensuing output.
Refresh a materialized view
You possibly can refresh materialized views utilizing two refresh varieties: full refresh or incremental refresh. Full refresh re-computes all the materialized view from all base desk information. Incremental refresh processes solely the adjustments because the final refresh. Full refresh is good whenever you want consistency or after vital information adjustments. Incremental refresh is most well-liked whenever you want rapid updates. The next examples present each refresh varieties.
To make use of full refresh, full the next steps:
- Insert three new information into the bottom desk to simulate new information arriving:
- Question the materialized view to confirm it nonetheless exhibits the previous aggregated values:
- Run a full refresh of the materialized view utilizing the next command:
- Question the materialized view once more to confirm the aggregated values now embrace the brand new information:
To make use of incremental refresh, full the next steps:
- Allow incremental refresh by setting the Spark configuration properties:
- Insert two further information into the bottom desk:
- Run an incremental refresh utilizing the
REFRESHcommand with out theFULLclause. To confirm if incremental refresh is enabled, confer with Appendix 2 on the finish of this publish. - Question the materialized view to verify the incremental adjustments are mirrored within the aggregated outcomes:
Along with utilizing Spark SQL, it’s also possible to set off handbook refreshes via AWS Glue APIs whenever you want updates outdoors your scheduled intervals. Run the next AWS CLI command:
The AWS Lake Formation console shows refresh historical past for API-triggered updates. Open your materialized view to see the refresh kind (INCREMENTAL or FULL), begin and finish time, standing and so forth:

You could have discovered methods to use Iceberg materialized views to make your environment friendly information processing and queries. You created a materialized view utilizing Spark on Amazon EMR, queried it from each Amazon EMR and Athena, and used two refresh mechanisms: full refresh and incremental refresh. Iceberg materialized views aid you rework and optimize your information pipelines effortlessly.
Concerns
There are necessary points to think about for optimum utilization of the aptitude:
- We launched new SQL syntax to handle materialized views within the AWS optimized Spark runtime engine solely. These new SQL instructions can be found in Spark model 3.5.6 and above throughout Athena, Amazon EMR, and AWS Glue. Open supply Spark is just not supported.
- Materialized views are finally according to base tables. When supply tables change, the materialized views are up to date via background refresh processes as outlined by customers within the refresh schedule at creation. Through the refresh window, queries instantly accessing materialized views may see outdated information. Nevertheless, prospects who want rapid entry to essentially the most up-to-date datasets can run a handbook refresh with a easy
REFRESH MATERIALIZED VIEWSQL command.
Clear up
To keep away from incurring future prices, clear up the sources you created throughout this walkthrough:
- Run the next instructions to delete a materialized view and tables:
- For Amazon EMR, terminate the Amazon EMR cluster.
- For AWS Glue, delete the AWS Glue job.
Conclusion
This publish demonstrated how Iceberg materialized views facilitate environment friendly information lake operations on AWS. The brand new materialized view functionality simplifies information pipelines and improves question efficiency by storing pre-computed outcomes which can be robotically up to date as base tables change. You possibly can create materialized views utilizing acquainted SQL syntax, utilizing each full and incremental refresh mechanisms to take care of information consistency. This answer alleviates the necessity for complicated pipeline upkeep whereas offering seamless integration with AWS companies like Athena, Amazon EMR, and AWS Glue. The automated question rewrite performance additional optimizes efficiency by intelligently using materialized views when relevant, making it a strong software for organizations seeking to streamline their information transformation workflows and speed up question efficiency.
Appendix 1: Spark configuration to make use of Amazon S3 Tables storing Apache Iceberg materialized views
As talked about earlier on this publish, materialized views are saved as Iceberg tables in Amazon S3 Tables buckets inside your account. Whenever you need to use Amazon S3 Tables because the storage location on your materialized views as an alternative of a normal Amazon S3 bucket, you will need to configure Spark with the Amazon S3 Tables catalog.
The distinction from the usual AWS Glue Information Catalog configuration proven within the stipulations part is the glue.id parameter format. For Amazon S3 Tables, use the format
After you configure Spark with these settings, you’ll be able to create and handle materialized views utilizing the identical SQL instructions proven on this publish, and the materialized views are saved in your Amazon S3 Tables bucket.
Appendix 2: Confirm refreshing a materialized view with Spark SQL
Run SHOW TBLPROPERTIES in Spark SQL to test which refresh methodology was used:
In regards to the authors