With the Amazon EMR 7.10 runtime, Amazon EMR has launched EMR S3A, an improved implementation of the open supply S3A file system connector. This enhanced connector is now mechanically set because the default S3 file system connector for Amazon EMR deployment choices, together with Amazon EMR on EC2, Amazon EMR Serverless, Amazon EMR on Amazon EKS, and Amazon EMR on AWS Outposts, sustaining full API compatibility with open supply Apache Spark.
Within the Amazon EMR 7.10 runtime for Apache Spark, the EMR S3A connector reveals efficiency corresponding to EMRFS for learn workloads, as demonstrated by TPC-DS question benchmark. The connector’s most important efficiency positive factors are evident in write operations, with a 7% enchancment in static partition overwrites and a 215% enchancment for dynamic partition overwrites when in comparison with EMRFS. On this submit, we showcase the improved learn and write efficiency benefits of utilizing Amazon EMR 7.10.0 runtime for Apache Spark with EMR S3A as in comparison with EMRFS and the open supply S3A file system connector.
Learn workload efficiency comparability
To judge the learn efficiency, we used a take a look at atmosphere based mostly on Amazon EMR runtime model 7.10.0 working Spark 3.5.5 and Hadoop 3.4.1. Our testing infrastructure featured an Amazon Elastic Compute Cloud (Amazon EC2) cluster comprised of 9 r5d.4xlarge cases. The first node has 16 vCPU and 128 GB reminiscence, and the eight core nodes have a complete of 128 vCPU and 1024 GB reminiscence.
The efficiency analysis was performed utilizing a complete testing methodology designed to supply correct and significant outcomes. For the supply knowledge, we selected the three TB scale issue, which comprises 17.7 billion information, roughly 924 GB of compressed knowledge partitioned in Parquet file format. The setup directions and technical particulars could be discovered within the GitHub repository. We used Spark’s in-memory knowledge catalog to retailer metadata for TPC-DS databases and tables.
To supply a good and correct comparability between EMR S3A vs. EMRFS and open supply S3A implementations, we carried out a three-phase testing method:
- Part 1: Baseline efficiency:
- Established a baseline utilizing default Amazon EMR configuration with EMR’s S3A connector
- Created a reference level for subsequent comparisons
- Part 2: EMRFS evaluation:
- Maintained the default file system as EMRFS
- Preserved different configuration settings
- Part 3: Open supply S3A testing:
- Modified solely the
hadoop-aws.jarfile by changing it with the open supply Hadoop S3A 3.4.1 model - Maintained similar configurations throughout different parts
- Modified solely the
This managed testing atmosphere was essential for our analysis for the next causes:
- We might isolate the efficiency affect particularly to the S3A connector implementation
- It eliminated potential variables that might skew the outcomes
- It offered correct measurements of efficiency enhancements between Amazon’s S3A implementation and the open supply various
Take a look at execution and outcomes
All through the testing course of, we maintained consistency in take a look at situations and configurations, ensuring any noticed efficiency variations may very well be straight attributed to the S3A connector implementation variations. A complete of 104 SparkSQL queries have been run in 10 iterations sequentially, and a median of every question’s runtime in these 10 iterations was used for comparability. The typical of the ten iterations’ runtime on the Amazon EMR 7.10 runtime for Apache Spark with EMR S3A was 1116.87 seconds, which is 1.08 instances sooner than open supply S3A and comparable with EMRFS. The next determine illustrates the entire runtime in seconds.
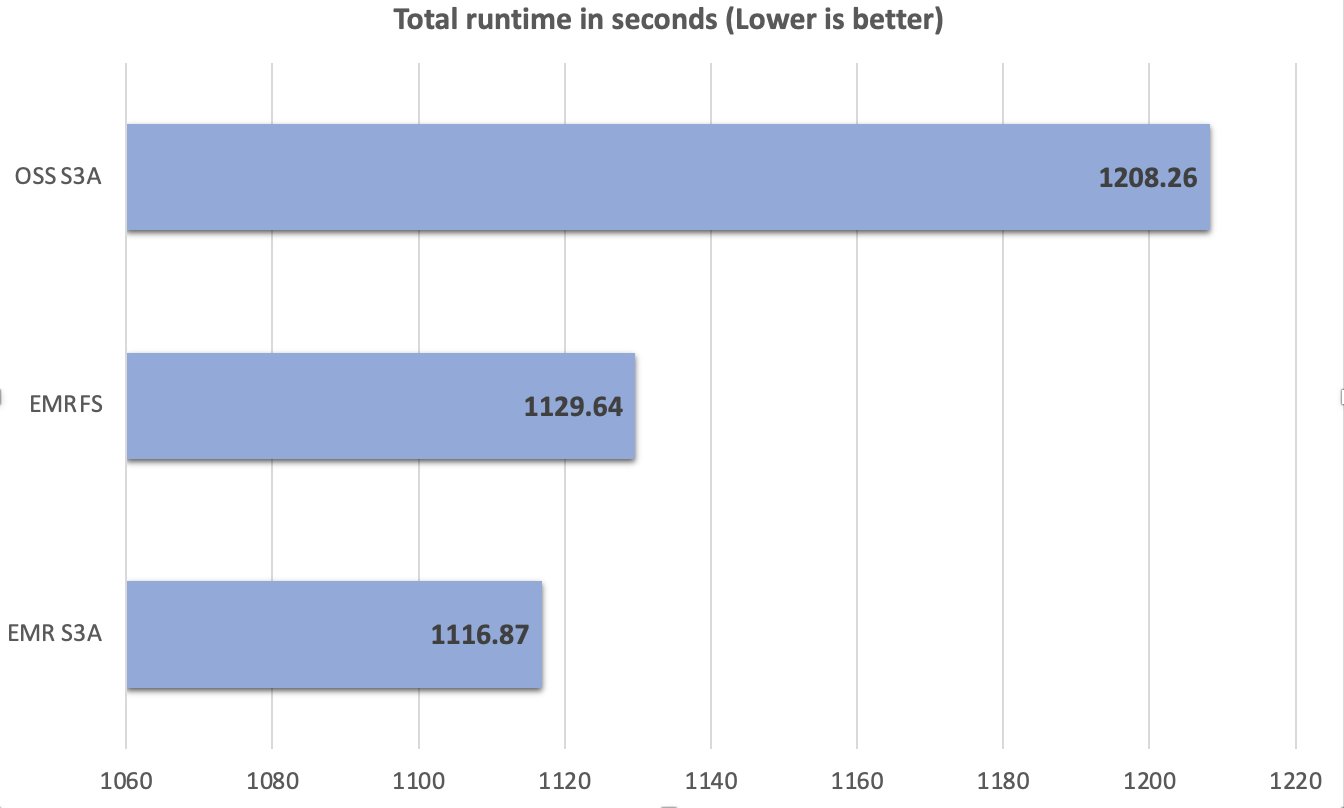
The next desk summarizes the metrics.
| Metric | OSS S3A | EMRFS | EMR S3A |
| Common runtime in seconds | 1208.26 | 1129.64 | 1116.87 |
| Geometric imply over queries in seconds | 7.63 | 7.09 | 6.99 |
| Complete value * | $6.53 | $6.40 | $6.15 |
*Detailed value estimates are mentioned later on this submit.
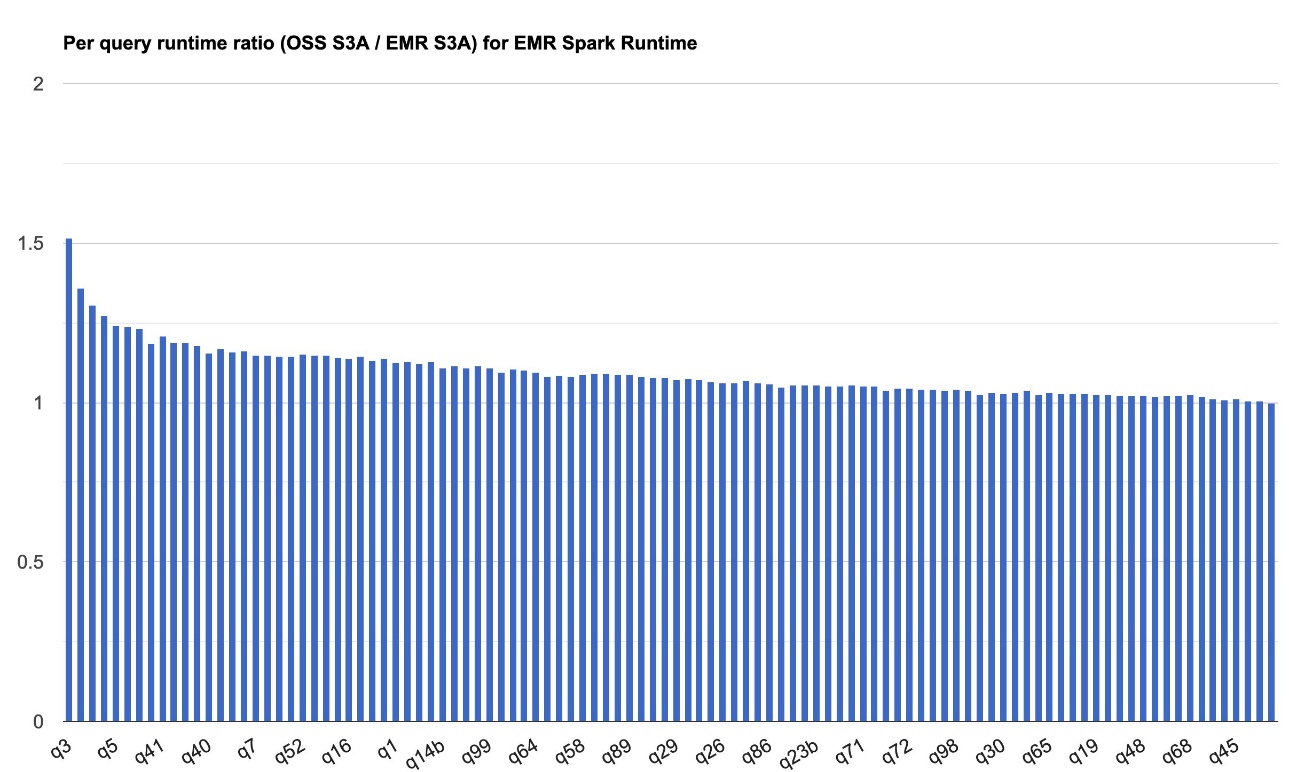
The next chart demonstrates the per-query efficiency enchancment of EMR S3A relative to open supply S3A on the Amazon EMR 7.10 runtime for Apache Spark. The extent of the speedup varies from one question to a different, with the quickest as much as 1.51 instances sooner for q3, with Amazon EMR S3A outperforming open supply S3A. The horizontal axis arranges the TPC-DS 3TB benchmark queries in descending order based mostly on the efficiency enchancment seen with Amazon EMR, and the vertical axis depicts the magnitude of this speedup as a ratio.
Learn value comparability
Our benchmark outputs the entire runtime and geometric imply figures to measure the Spark runtime efficiency. The associated fee metric can present us with extra insights. Price estimates are computed utilizing the next formulation. They consider Amazon EC2, Amazon Elastic Block Retailer (Amazon EBS), and Amazon EMR prices, however don’t embody Amazon Easy Storage Service (Amazon S3) GET and PUT prices.
- Amazon EC2 value (embody SSD value) = variety of cases * r5d.4xlarge hourly charge * job runtime in hours
- r5d.4xlarge hourly charge = $1.152 per hour
- Root Amazon EBS value = variety of cases * Amazon EBS per GB-hourly charge * root EBS quantity measurement * job runtime in hours
- Amazon EMR value = variety of cases * r5d.4xlarge Amazon EMR value * job runtime in hours
- r5d.4xlarge Amazon EMR value = $0.27 per hour
- Complete value = Amazon EC2 value + root Amazon EBS value + Amazon EMR value
The next desk summarizes these prices.
| Metric | EMRFS | EMR S3A | OSS S3A |
| Runtime in hours | 0.5 | 0.48 | 0.51 |
| Variety of EC2 cases | 9 | 9 | 9 |
| Amazon EBS measurement | 0 gb | 0 gb | 0 gb |
| Amazon EC2 value | $5.18 | $4.98 | $5.29 |
| Amazon EBS value | $0.00 | $0.00 | $0.00 |
| Amazon EMR value | $1.22 | $1.17 | $1.24 |
| Complete value | $6.40 | $6.15 | $6.53 |
| Price financial savings | Baseline | EMR S3A is 1.04 instances higher than EMRFS | EMR S3A is 1.06 instances higher than OSS S3A |
Write workload efficiency comparability
We performed benchmark checks to evaluate the write efficiency of the Amazon EMR 7.10 runtime for Apache Spark.
Static desk/partition overwrite
We evaluated the static desk/partition overwrite write efficiency of the completely different file system by executing the next INSERT OVERWRITE Spark SQL question. The SELECT * FROM vary(...) clause generated knowledge at execution time. This produced roughly 15 GB of knowledge throughout precisely 100 Parquet recordsdata in Amazon S3.
The take a look at atmosphere was configured as follows:
- EMR cluster with emr-7.10.0 launch label
- Single m5d.2xlarge occasion (major group)
- Eight m5d.2xlarge cases (core group)
- S3 bucket in the identical AWS Area because the EMR cluster
- The
trial_idproperty used a UUID generator to keep away from battle between take a look at runs
Outcomes
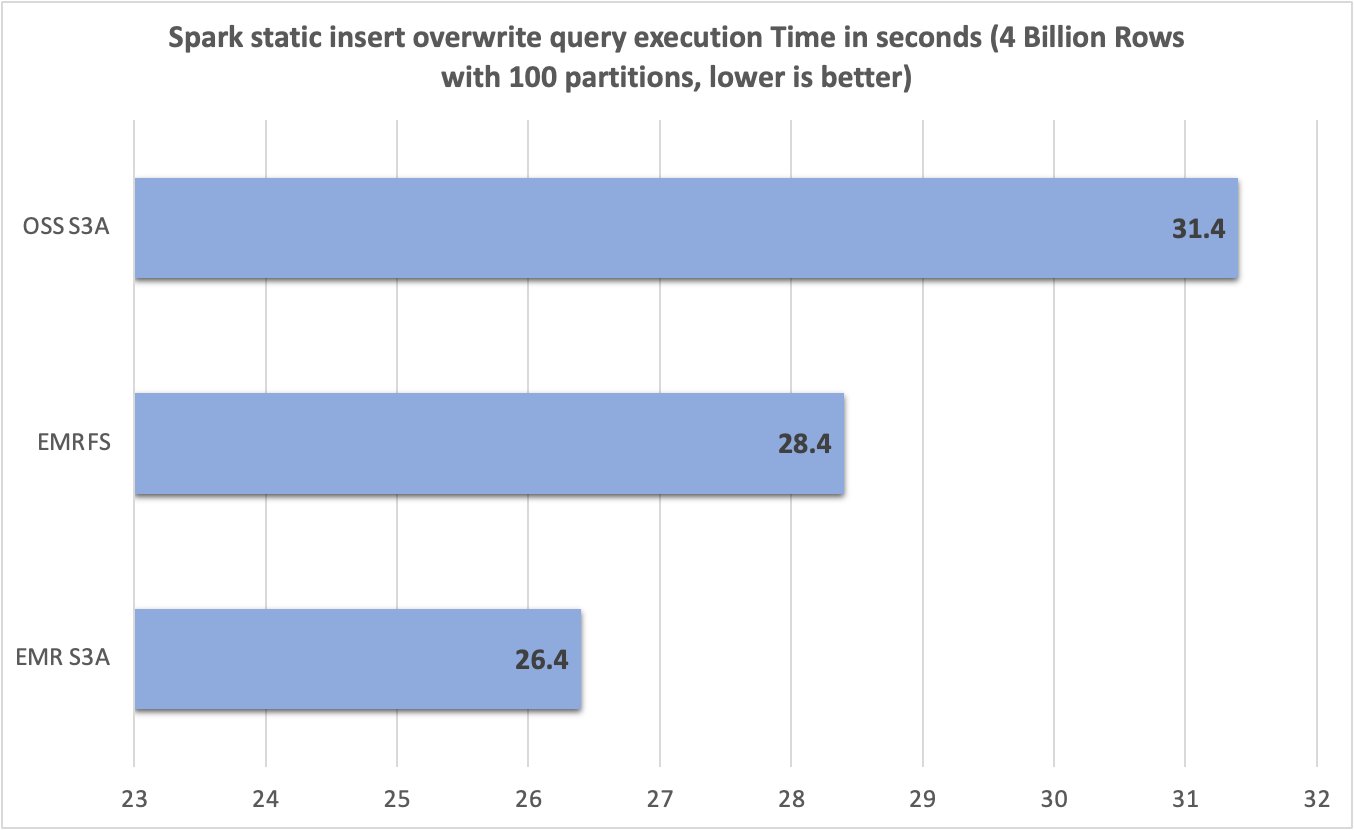
After working 10 trials for every file system, we captured and summarized question runtimes within the following chart. Whereas EMR S3A averaged solely 26.4 seconds, the EMRFS and open supply S3A averaged 28.4 seconds and 31.4 seconds—a 1.07 instances and 1.19 instances enchancment, respectively.
Dynamic partition overwrite
We additionally evaluated the write efficiency by executing the next INSERT OVERWRITE dynamic partition Spark SQL question, which joins TPC-DS 3TB partitioned Parquet knowledge of the desk web_sales and date_dim tables, which inserts roughly 2,100 partitions, the place every partition comprises one Parquet file with a mixed measurement of roughly 31.2 GB in Amazon S3.
The take a look at atmosphere was configured as follows:
- EMR cluster with emr-7.10.0 launch label
- Single r5d.4xlarge occasion (grasp group)
- 5 r5d.4xlarge cases (core group)
- Roughly 2,100 partitions with one Parquet file every
- Mixed measurement of roughly 31.2 GB in Amazon S3
Outcomes
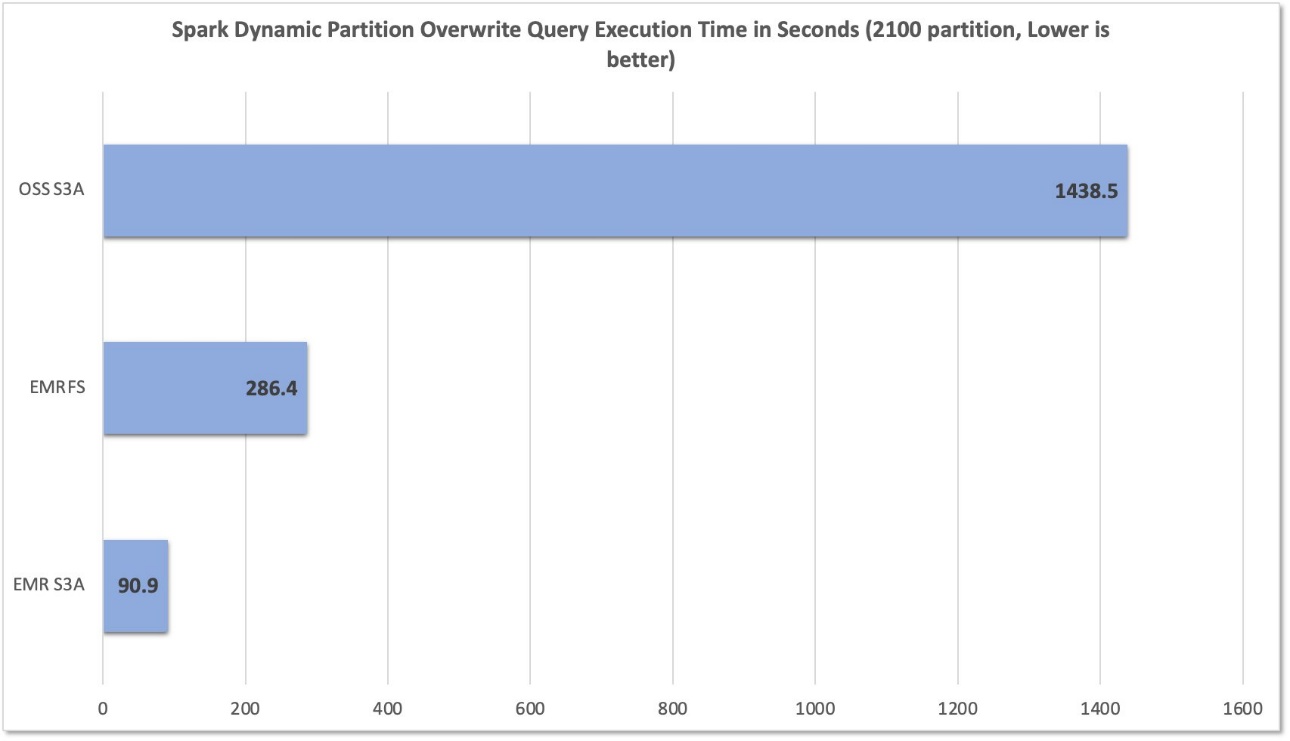
After working 10 trials for every file system, we captured and summarized question runtimes within the following chart. Whereas EMR S3A averaged solely 90.9 seconds, the EMRFS and open supply S3A averaged 286.4 seconds and 1,438.5 seconds—a 3.15 instances and 15.82 instances enchancment, respectively.
Abstract
Amazon EMR constantly enhances its Apache Spark runtime and S3A connector, delivering steady efficiency enhancements that assist massive knowledge prospects execute analytics workloads extra cost-effectively. Past efficiency positive factors, the strategic shift to S3A introduces vital benefits, together with enhanced standardization, improved cross-platform portability, and strong community-driven help—all whereas sustaining or surpassing the efficiency benchmarks established by the earlier EMRFS implementation.
We advocate that you just keep up-to-date with the most recent Amazon EMR launch to benefit from the most recent efficiency and have advantages. Subscribe to the AWS Massive Knowledge Weblog’s RSS feed to be taught extra concerning the Amazon EMR runtime for Apache Spark, configuration finest practices, and tuning recommendation.
Concerning the authors