For years, Apache Spark Structured Streaming has powered among the world’s most demanding streaming workloads. Nevertheless, for ultra-low latency use circumstances, groups wanted to keep up separate, specialised engines — mostly Apache Flink, alongside Spark, duplicating codebases, governance fashions, and operational overhead. Now, Databricks removes this burden for purchasers.
In the present day, we’re excited to announce the Basic Availability of Actual-Time Mode (RTM) in Spark Structured Streaming, bringing millisecond-level latency to the Spark APIs you already use. Be it detecting fraud in real-time, or producing recent, real-time context to steer your AI brokers, now you can use Spark to energy all of those use circumstances.
Powering industry-leading prospects and use circumstances
RTM has already been adopted by groups at industry-leading organizations throughout monetary companies, e-commerce, media, and advert tech to energy fraud detection, dwell personalization, ML function computation, and advert attribution.
Coinbase, one of many world’s main cryptocurrency exchanges, makes use of RTM to scale their high-frequency threat administration and fraud detection engines—processing large volumes of blockchain and alternate occasions with the sub-100ms latency essential to safe hundreds of thousands of digital asset transactions.
By leveraging Actual-Time Mode in Spark Structured Streaming, we’ve achieved an 80%+ discount in end-to-end latencies, hitting sub-100ms P99s, and streamlining our real-time ML technique at large scale. This efficiency permits us to compute over 250 ML options all powered by a unified Spark engine.”—Daniel Zhou, Senior Workers Machine Studying Platform Engineer, Coinbase
DraftKings, considered one of North America’s largest sportsbook and fantasy sports activities platforms, makes use of real-time mode to energy function computation for his or her fraud detection fashions — processing high-throughput betting occasion streams with the latency and reliability required for real-money wagering selections.
In dwell sports activities betting, fraud detection calls for excessive velocity. The introduction of Actual-Time Mode along with the transformWithState API in Spark Structured Streaming has been a sport changer for us. We achieved substantial enhancements in each latency and pipeline design, and for the primary time, constructed unified function pipelines for ML coaching and on-line inference, reaching ultra-low latencies that had been merely not attainable earlier.”—Maria Marinova, Sr. Lead Software program Engineer, DraftKings
MakeMyTrip, considered one of India’s main on-line journey platform for resorts, flights, and experiences, adopted Actual-Time Mode to energy personalised search experiences. RTM processed high-volume traveler searches to ship real-time suggestions.
In journey search, each millisecond counts. By leveraging Spark Actual-Time Mode (RTM), we delivered personalised experiences with sub-50ms P50 latencies, driving a 7% uplift in click-through charges. RTM has additionally remodeled our knowledge operations, enabling a unified structure the place Spark handles every little thing from high-throughput ETL to ultra-low-latency pipelines. As we transfer into the period of AI brokers, steering them successfully requires constructing real-time context from knowledge streams. We’re experimenting with Spark RTM to produce our brokers with the richest, most up-to-date context essential to take the very best selections.” —Aditya Kumar, Affiliate Director of Engineering, MakeMyTrip
RTM can help any workload that advantages from turning knowledge into selections in milliseconds. Some instance use circumstances embrace:
- Customized experiences in retail and media: An OTT streaming supplier updates content material suggestions instantly after a consumer finishes watching a present. A number one e-commerce platform recalculates product gives as prospects browse – holding engagement excessive with sub-second suggestions loops.
- IoT monitoring: A transport and logistics firm ingests dwell telemetry to drive anomaly detection, transferring from reactive to proactive decision-making in milliseconds.
- Fraud detection: A worldwide financial institution processes bank card transactions from Kafka in actual time and flags suspicious exercise, all inside 200 milliseconds – decreasing threat and response time with out replatforming.
What Is Actual-Time Mode (RTM)?
RTM is an evolution of the Spark Structured Streaming engine that allows it to realize sub-millisecond efficiency in benchmarking demanding function engineering buyer workloads.
Structured Streaming’s default microbatch mode (MBM) is like an airport shuttle bus that waits for a sure variety of passengers to board earlier than departing. Alternatively, RTM operates like a high-speed transferring walkway, eliminating the limitation to attend for the shuttle bus to refill. RTM processes every occasion because it arrives, offering end-to-end millisecond latency with out leaving the Spark ecosystem.
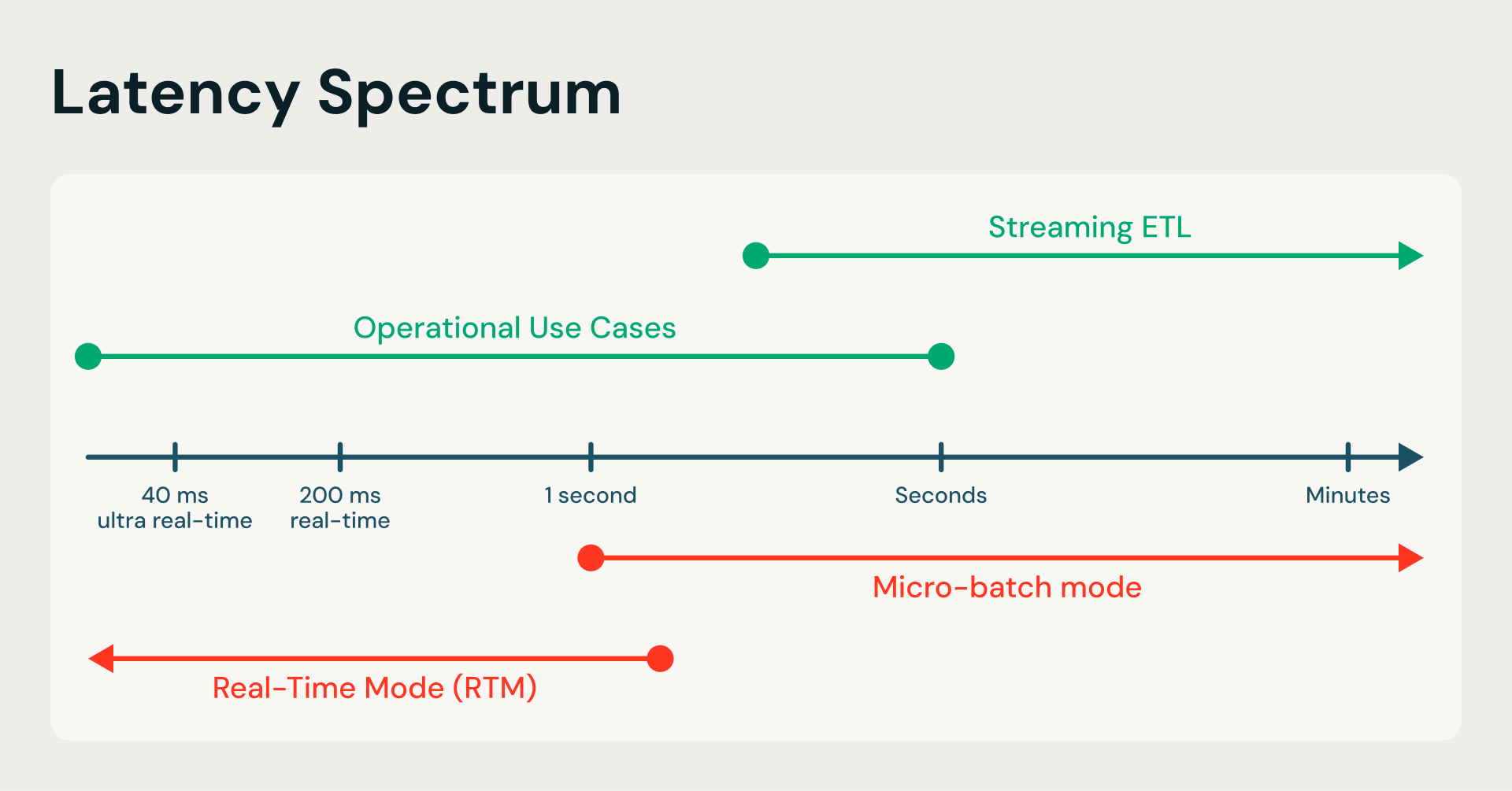
From seconds to milliseconds: RTM transforms the Spark engine by changing periodic batching with a steady knowledge move, eliminating the latency bottlenecks of conventional ETL.
RTM’s efficiency features come from three key architectural improvements:
- Steady knowledge move: Information is processed because it arrives as an alternative of discretized, periodic chunks.
- Pipeline scheduling: Levels run concurrently with out blocking, permitting downstream duties to course of knowledge instantly with out ready for upstream levels to complete.
- Streaming shuffle: Information is handed between duties instantly, bypassing the latency bottlenecks of conventional disk-based shuffles.
Collectively, they remodel Spark right into a high-performance, low-latency engine able to dealing with probably the most demanding operational use circumstances.
Spark RTM: As much as 92% sooner than Flink, enabling groups to function much less infrastructure, transfer sooner
In an effort to validate the efficiency of Spark RTM, we benchmarked the efficiency towards a well-liked specialised engine, Apache Flink based mostly on precise buyer workloads performing function computation. These function computation patterns are consultant of most low-latency ETL use circumstances, comparable to fraud detection, personalization, and operational analytics.When evaluating Spark RTM with Flink, the outcomes reveal that Spark’s advanced structure offers a latency profile similar to specialised streaming frameworks. For extra data, on the info units and queries referenced, see this GitHub repository.
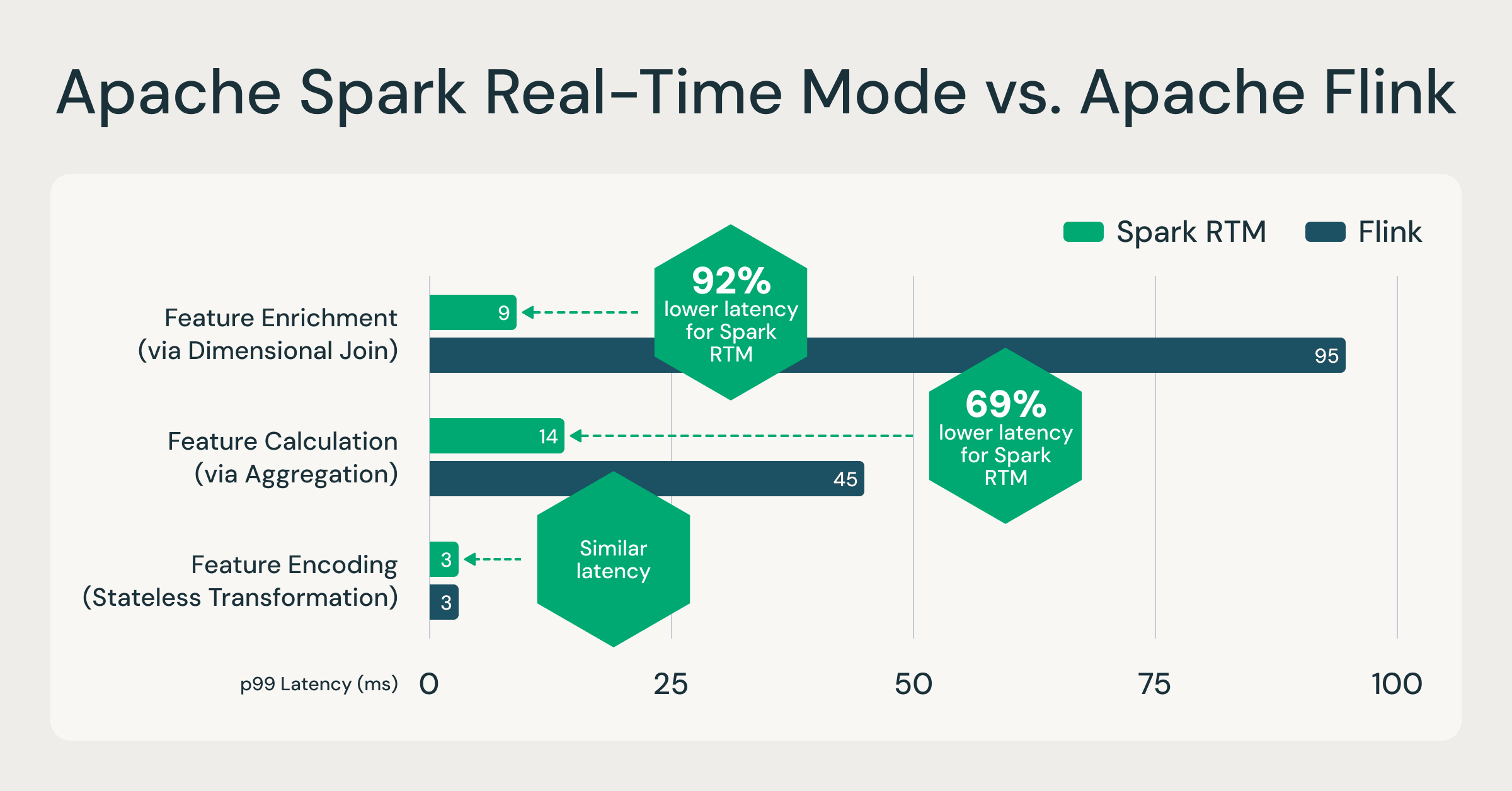
One engine, as much as 92% sooner: RTM outpaces specialised engines like Flink, proving that millisecond-level operational analytics not requires a separate streaming engine. Supply: Inner benchmarks based mostly on buyer function computation patterns. Full queries obtainable on GitHub.
Whereas uncooked pace issues, Spark RTM’s best benefit over engines like Flink is the simplicity it gives builders. It permits groups to make use of the identical Spark API for each batch coaching and real-time inference, successfully eliminating “logic drift” and codebase duplication. Spark RTM permits seamless scalability, the place a single-line code change can shift a pipeline from hourly batches to sub-second streaming with out guide infrastructure tuning. Finally, by decreasing operational complexity and the necessity for a number of specialised methods, groups can develop and deploy real-time functions considerably sooner with Spark RTM.
Getting began with Spark RTM
Getting up and working with RTM is simple. In case you’re already utilizing Structured Streaming, you possibly can allow it with a single configuration replace – no rewrites required.
Step 1: Configure your cluster
RTM is presently obtainable on Traditional compute, throughout each Devoted and Normal entry modes. RTM is supported on Databricks Runtime (DBR) 16.4 and above; nonetheless,we suggest DBR 18.1 for the newest options and optimizations. Throughout cluster creation, add the next Spark configuration:
Step 2: Use the brand new Actual-Time Set off in your streaming question
What’s New with Spark RTM
Since launching in Public Preview in August 2025, Databricks has continued to develop RTM’s capabilities, based mostly on buyer suggestions.
Here’s what’s new with this GA launch:
- OSS help in Apache Spark 4.1 (stateless transformations): RTM for stateless transformations is now obtainable in open-source Apache Spark 4.1. Groups constructing on OSS Spark can reap the benefits of real-time mode for projection, filtering, and UDF-based pipelines.
- Normal entry mode help: RTM now works on each devoted and customary entry modes in traditional compute in Python, giving groups extra flexibility in how they make the most of compute sources throughout streaming workloads.
- Async state checkpointing and progress monitoring: State and question progress checkpointing at the moment are carried out asynchronously, decoupled from the occasion processing crucial path. This improves the latency of real-time mode for stateless and stateful pipelines.
- Preliminary state load in transformWithState: transformWithState is a strong Spark Structured Streaming operator for constructing customized stateful logic. Customers can now load the preliminary state from the checkpoint of a pre-existing question or from a delta desk when utilizing transformWithState with Actual-Time Mode. This functionality is crucial for stateful function engineering, permitting you to pre-populate on-line queries with historic context with out “ranging from zero.”
- Enhanced metrics and observability for UDFs: Extra correct latency metrics for Python UDF execution surfaced by means of StreamingQueryProgress listener.
- Efficiency enhancements for Python Stateful UDFs: Added optimizations to enhance the efficiency of stateful operations in Python transformWithState, particularly for RTM queries.
Conclusion
RTM extends Apache Spark Structured Streaming into a brand new class of workloads — operational, latency-sensitive functions that demand speedy response to streaming knowledge. By bringing sub-second latency to the Spark APIs your staff already makes use of, it eliminates the necessity to function a separate specialised engine in your most time-critical pipelines Whether or not you are constructing fraud detection pipelines, personalization engines, or ML function computation methods, real-time mode offers you the latency your utility calls for with the simplicity and ecosystem breadth of Spark.
Technical Sources
Try the next sources to get began with RTM right now: