
(Chuysang/Shutterstock)
On this planet of monitoring software program, the way you course of telemetry knowledge can considerably affect your skill to derive insights, troubleshoot points, and handle prices.
There are 2 main use circumstances for a way telemetry knowledge is leveraged:
- Radar (Monitoring of techniques) normally falls into the bucket of identified knowns and identified unknowns. This results in eventualities the place some knowledge is sort of ‘pre-determined’ to behave, be plotted in a sure manner – as a result of we all know what we’re in search of.
- Blackbox (Debugging, RCA and so forth.) ones alternatively are extra to do with unknown unknowns. Which entails to what we don’t know and will must hunt for to construct an understanding of the system.
Understanding Telemetry Information Challenges
Earlier than diving into processing approaches, it’s necessary to grasp the distinctive challenges of telemetry knowledge:
- Quantity: Trendy techniques generate huge quantities of telemetry knowledge
- Velocity: Information arrives in steady, high-throughput streams
- Selection: A number of codecs throughout metrics, logs, traces, profiles and occasions
- Time-sensitivity: Worth usually decreases with age
- Correlation wants: Information from completely different sources have to be linked collectively
These traits create particular issues when selecting between ETL and ELT approaches.
ETL for Telemetry: Remodel-First Structure
Technical Structure
In an ETL method, telemetry knowledge undergoes transformation earlier than reaching its ultimate vacation spot:

Fig. 1 — ETL for Telemetry
A typical implementation stack would possibly embrace:
- Assortment: OpenTelemetry, Prometheus, Fluent Bit
- Transport: Kafka or Kinesis or in reminiscence because the buffering layer
- Transformation: Stream processing
- Storage: Time-series databases (Prometheus) or specialised indices or Object Storage (s3)
Key Technical Parts
- Aggregation Methods
Pre-aggregation considerably reduces knowledge quantity and question complexity. A typical pre-aggregation move seems to be like this:

Fig. 2 — Aggregation Methods
This transformation condenses uncooked knowledge into 5-minute summaries, dramatically decreasing storage necessities and bettering question efficiency.
Instance: For a gaming utility dealing with thousands and thousands of requests per day, uncooked request latency metrics (doubtlessly billions of knowledge factors) will be grouped by service and endpoint, then aggregated into 5-minute (or 1-minute) home windows. A single API name that generates 100 latency knowledge factors per second (8.64 million per day) is diminished to simply 288 aggregated entries per day (one per 5-minute window), whereas nonetheless preserving vital p50/p90/p99 percentiles wanted for SLA monitoring.
- Cardinality Administration
Excessive-cardinality metrics can break time-series databases. The cardinality administration course of follows this sample:
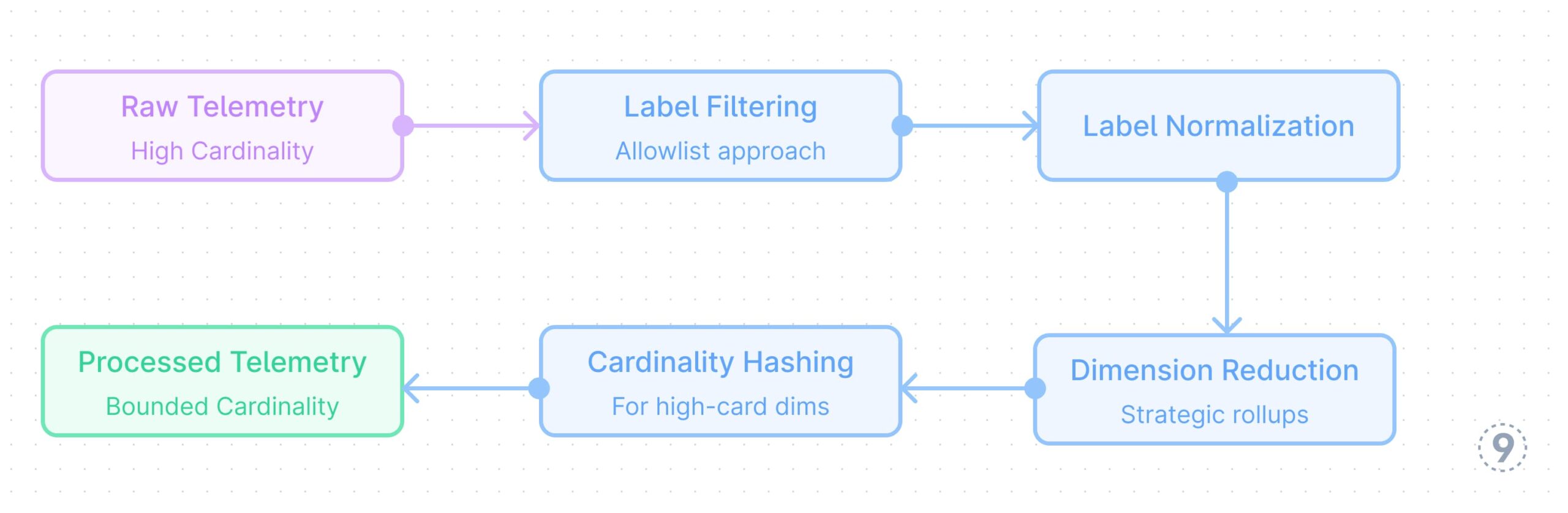
Fig. 3 — Cardinality-Administration
Efficient methods embrace:
- Label filtering and normalization
- Strategic aggregation of particular dimensions
- Hashing strategies for high-cardinality values whereas preserving question patterns
Instance: A microservice monitoring HTTP requests contains consumer IDs and request paths in its metrics. With 50,000 day by day energetic customers and hundreds of distinctive URL paths, this creates thousands and thousands of distinctive label mixtures. The cardinality administration system filters out consumer IDs solely (configurable, too excessive cardinality), normalizes URL paths by changing dynamic segments with placeholders (e.g., /customers/123/profilebecomes /customers/{id}/profile), and applies constant categorization to errors. This reduces distinctive time collection from thousands and thousands to tons of, permitting the time-series database to perform effectively.
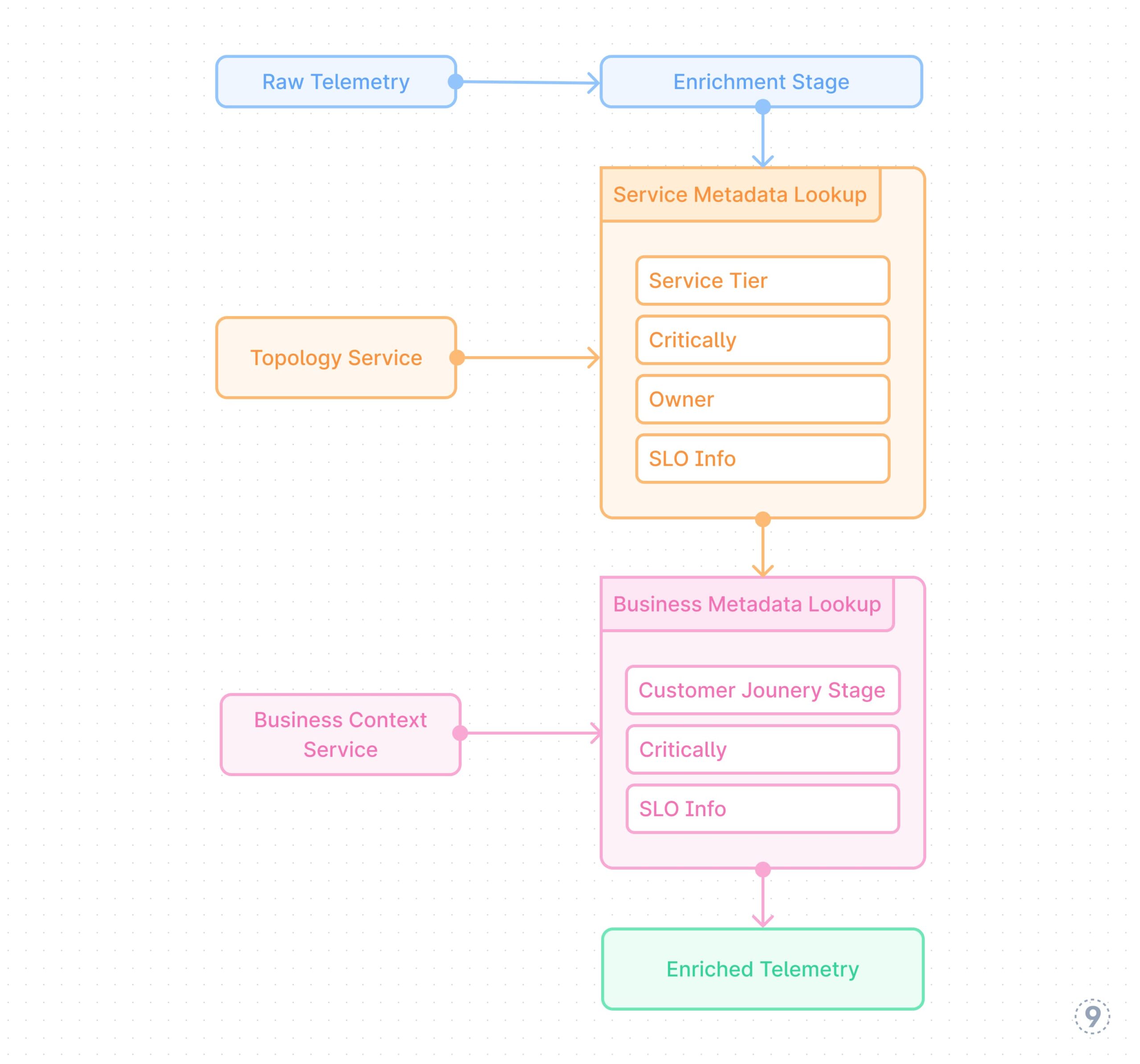
Fig. 4 — Actual-time Enrichment
- Actual-time Enrichment
Including context to metrics in the course of the transformation part entails integrating exterior knowledge sources:
This course of provides vital enterprise and operational context to uncooked telemetry knowledge, enabling extra significant evaluation and alerting primarily based on service significance, buyer affect, and different components past pure technical metrics.
Instance: A cost processing service emits primary metrics like request counts, latencies, and error charges. The enrichment pipeline joins this telemetry with service registry knowledge so as to add metadata concerning the service tier (vital), SLO targets (99.99% availability), and workforce possession (payments-team). It then incorporates enterprise context to tag transactions with their kind (subscription renewal, one-time buy, refund) and estimated income affect. When an incident happens, alerts are routinely prioritized primarily based on enterprise affect reasonably than simply technical severity, and routed to the suitable workforce with wealthy context.
Technical Benefits
- Question efficiency: Pre-calculated aggregates remove computation at question time
- Predictable useful resource utilization: Each storage and question compute are managed
- Schema enforcement: Information conformity is assured earlier than storage
- Optimized storage codecs: Information will be saved in codecs optimized for particular entry patterns
Technical Limitations
- Lack of granularity: Some element is completely misplaced
- Schema rigidity: Adapting to new necessities requires pipeline modifications
- Processing overhead: Actual-time transformation provides complexity and useful resource calls for
- Transformation-time choices: Evaluation paths have to be identified prematurely
ELT for Telemetry: Uncooked Storage with Versatile Transformation
Technical Structure
ELT structure prioritizes getting uncooked knowledge into storage, with transformations carried out at question time:

Fig. 5 — ELT for Telemetry
A typical implementation would possibly embrace:
- Assortment: OpenTelemetry, Prometheus, Fluent Bit
- Transport: Direct ingestion with out advanced processing
- Storage: Object storage (S3, GCS) or knowledge lakes in Parquet format
- Transformation: SQL engines (Presto, Athena), Spark jobs, or specialised OLAP techniques
Key Technical Parts
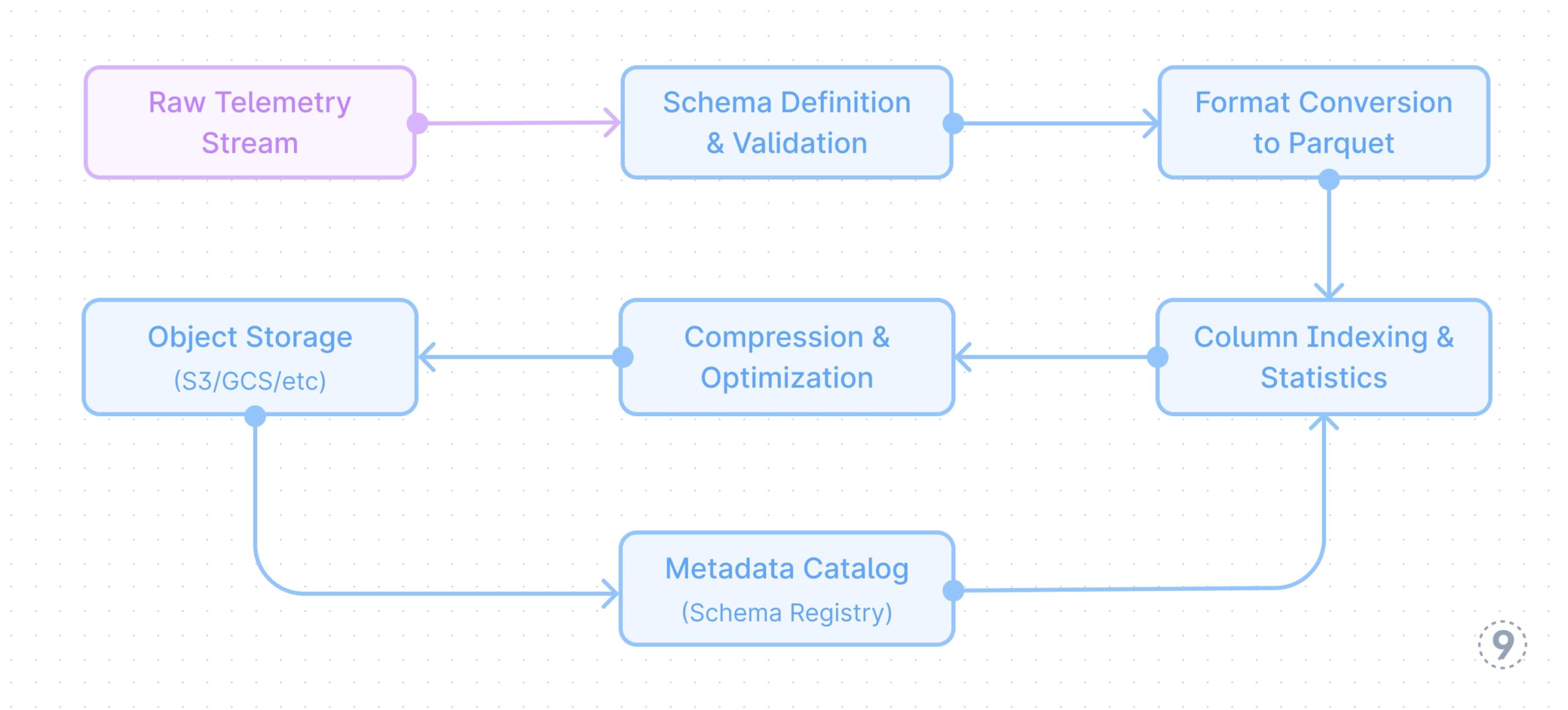
Fig. 6 — Environment friendly-Uncooked-Storage
- Environment friendly Uncooked Storage
Optimizing for long-term storage of uncooked telemetry requires cautious consideration of file codecs and storage group:
This method leverages columnar storage codecs like Parquet with acceptable compression (ZSTD for traces, Snappy for metrics), dictionary encoding, and optimized column indexing primarily based on widespread question patterns (trace_id, service, time ranges).
Instance: A cloud-native utility generates 10TB of hint knowledge day by day throughout its distributed companies. As an alternative of discarding or closely sampling this knowledge, the whole hint data is captured utilizing OpenTelemetry collectors and transformed to Parquet format with ZSTD compression. Key fields like trace_id, service title, and timestamp are listed for environment friendly querying. This method reduces the storage footprint by 85% in comparison with uncooked JSON whereas sustaining question efficiency. When a vital customer-impacting concern occurred, engineers had been capable of entry full hint knowledge from 3 months prior, figuring out a refined sample of intermittent failures that will have been misplaced with conventional sampling.
- Partitioning Methods
Efficient partitioning is essential for question efficiency in opposition to uncooked telemetry. A well-designed partitioning technique follows this hierarchy:
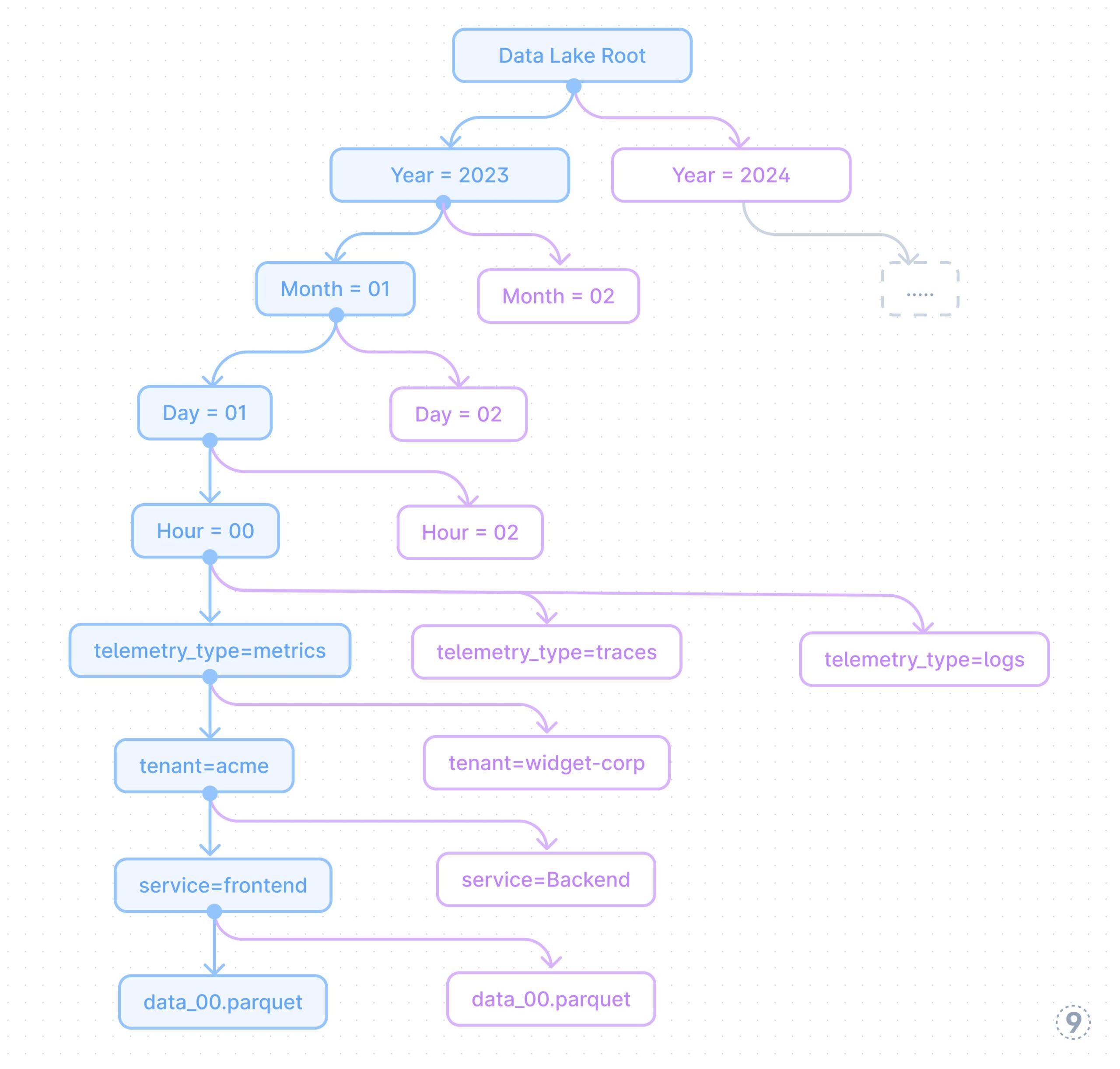
Fig. 7 — Partitioning-Methods
This partitioning method allows environment friendly time-range queries whereas additionally permitting filtering by service and tenant, that are widespread question dimensions. The partitioning technique is designed to:
- Optimize for time-based retrieval (commonest question sample)
- Allow environment friendly tenant isolation for multi-tenant techniques
- Permit service-specific queries with out scanning all knowledge
- Separate telemetry varieties for optimized storage codecs per kind
Instance: A SaaS platform with 200+ enterprise clients makes use of this partitioning technique for its observability knowledge lake. When a high-priority buyer experiences a difficulty that occurred final Tuesday between 2-4pm, engineers can instantly question simply these particular partitions: /yr=2023/month=11/day=07/hour=1[4-5]/tenant=enterprise-x/*. This method reduces the scan dimension from doubtlessly petabytes to only a few gigabytes, enabling responses in seconds reasonably than hours. When evaluating present efficiency in opposition to historic baselines, the time-based partitioning permits environment friendly month-over-month comparisons by scanning solely the related time partitions.
- Question-time Transformations
SQL and analytical engines present highly effective query-time transformations. The question processing move for on-the-fly evaluation seems to be like this (See Fig. 8).
This question move demonstrates how advanced evaluation like calculating service latency percentiles, error charges, and utilization patterns will be carried out solely at question time with no need pre-computation. The analytical engine applies optimizations like predicate pushdown, parallel execution, and columnar processing to attain cheap efficiency even in opposition to massive uncooked datasets.
Fig. 8 — Question-time-Transformations
Instance: A DevOps workforce investigating a efficiency regression found it solely affected premium clients utilizing a particular function. Utilizing query-time transformations in opposition to the ELT knowledge lake, they wrote a single question that first filtered to the affected time interval, joined buyer tier data, extracted related attributes about function utilization, calculated percentile response instances grouped by buyer phase, and recognized that premium clients with excessive transaction volumes had been experiencing degraded efficiency solely when a particular optionally available function flag was enabled. This evaluation would have been not possible with pre-aggregated knowledge for the reason that buyer phase + function flag dimension hadn’t been beforehand recognized as necessary for monitoring.
Technical Benefits
- Schema flexibility: New dimensions will be analyzed with out pipeline modifications
- Value-effective storage: Object storage is considerably cheaper than specialised DBs
- Retroactive evaluation: Historic knowledge will be examined with new views
Technical Limitations
- Question efficiency challenges: Interactive evaluation could also be gradual on massive datasets
- Useful resource-intensive evaluation: Compute prices will be excessive for advanced queries
- Implementation complexity: Requires extra refined question tooling
- Storage overhead: Uncooked knowledge consumes considerably more room
Technical Implementation: The Hybrid Strategy
Core Structure Parts
Implementation Technique
- Twin-path processing
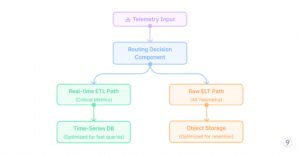
Fig. 10 — -Twin-path-processing
Instance: A world ride-sharing platform applied a dual-path telemetry system that routes service well being metrics and buyer expertise indicators (trip wait instances, ETA accuracy) via the ETL path for real-time dashboards and alerting. In the meantime, all uncooked knowledge together with detailed consumer journeys, driver actions, and utility logs flows via the ELT path to cost-effective storage. When a regional outage occurred, operations groups used the real-time dashboards to shortly establish and mitigate the rapid concern. Later, knowledge scientists used the preserved uncooked knowledge to carry out a complete root trigger evaluation, correlating a number of components that wouldn’t have been seen in pre-aggregated knowledge alone.
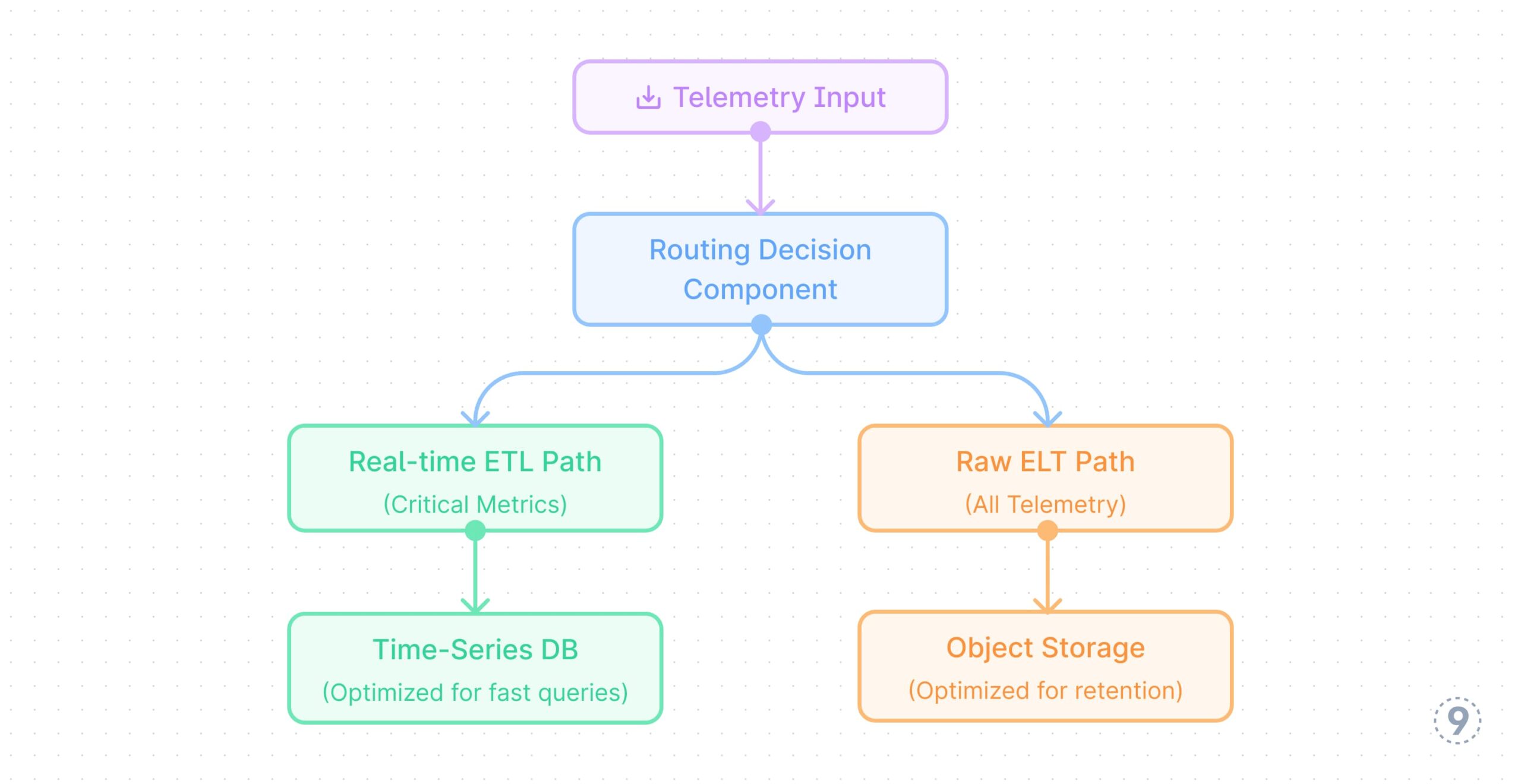
- Good knowledge routing
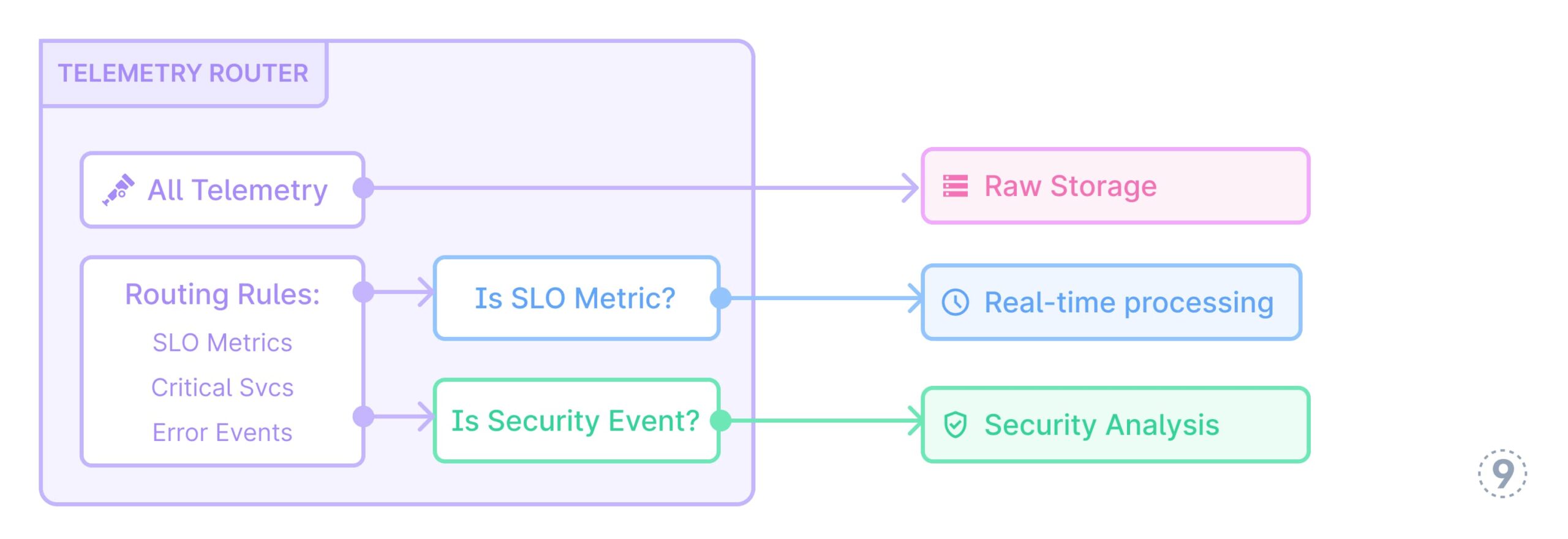
Fig. 11 — Good Information Routing
Instance: A monetary companies firm deployed a sensible routing system for his or her telemetry knowledge. All knowledge is preserved within the knowledge lake, however vital metrics like transaction success charges, fraud detection indicators, and authentication service well being metrics are instantly routed to the real-time processing pipeline. Moreover, any security-related occasions akin to failed login makes an attempt, permission modifications, or uncommon entry patterns are instantly despatched to a devoted safety evaluation pipeline. Throughout a latest safety incident, this routing enabled the safety workforce to detect and reply to an uncommon sample of authentication makes an attempt inside minutes, whereas the whole context of consumer journeys and utility habits was preserved within the knowledge lake for subsequent forensic evaluation.
- Unified question interface
Actual-world Implementation Instance
A particular engineering implementation at last9.io demonstrates how this hybrid method works in apply:
For a large-scale Kubernetes platform with tons of of clusters and hundreds of companies, we applied a hybrid telemetry pipeline with:
- Crucial-path metrics processed via a pipeline that:
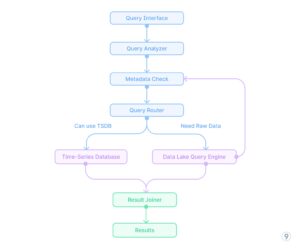
Fig. 12 — Unified question interface
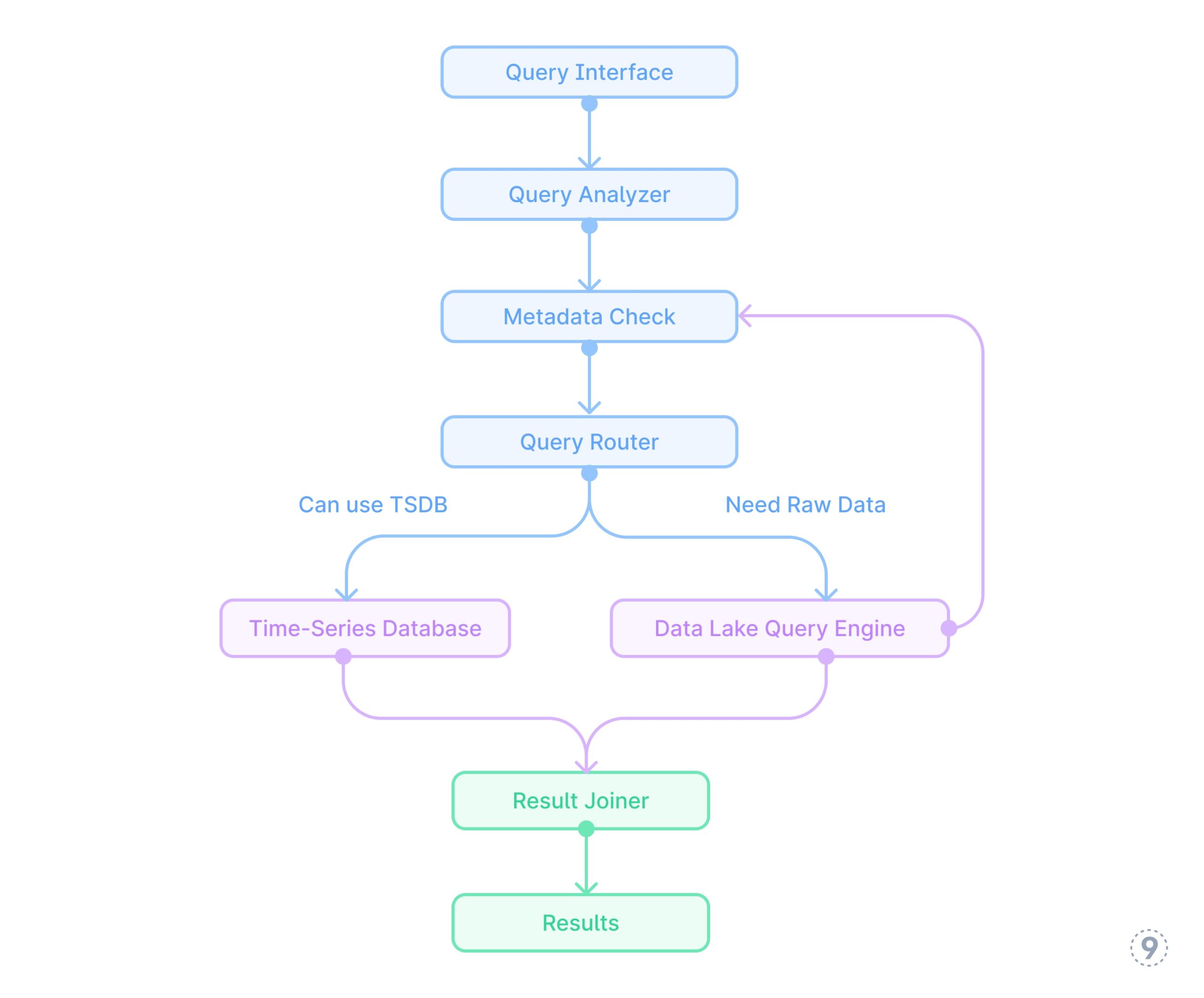
-
- Performs dimensional discount (limiting label mixtures)
-
- Pre-calculates service-level aggregations
-
- Computes derived metrics like success charges and latency percentiles
- Uncooked telemetry saved in an economical knowledge lake:
-
- Partitioned by time, knowledge kind, and tenant
-
- Optimized for typical question patterns
-
- Compressed with acceptable codecs (Zstd for traces, Snappy for metrics)
- Unified question layer that:
-
- Routes dashboard and alerting queries to pre-aggregated storage
-
- Redirects exploratory and ad-hoc evaluation to the information lake
-
- Manages correlation queries throughout each techniques
This method delivered each the question efficiency wanted for real-time operations and the analytical depth required for advanced troubleshooting.
Resolution Framework
When architecting telemetry pipelines, these technical issues ought to information your method:
| Resolution Issue | Use ETL | Use ELT |
| Question latency necessities | < 1 second | Can wait minutes |
| Information retention wants | Days/Weeks | Months/Years |
| Cardinality | Low/Medium | Very excessive |
| Evaluation patterns | Properly-defined | Exploratory |
| Price range precedence | Compute | Storage |
Conclusion
The technical realities of telemetry knowledge processing demand pondering past easy ETL vs. ELT paradigms. Engineering groups ought to architect tiered techniques that leverage the strengths of each approaches:
- ETL-processed knowledge for operational use circumstances requiring rapid insights
- ELT-processed knowledge for deeper evaluation, troubleshooting, and historic patterns
- Metadata-driven routing to intelligently direct queries to the suitable tier
This engineering-centric method balances efficiency necessities with value issues whereas sustaining the pliability required in trendy observability techniques.
In regards to the writer: Nishant Modak is the founder and CEO of Last9, a excessive cardinality observability platform firm backed by Sequoia India (now PeakXV). He’s been an entrepreneur and dealing with massive scale firms for practically twenty years.
India (now PeakXV). He’s been an entrepreneur and dealing with massive scale firms for practically twenty years.
Associated Gadgets:
From ETL to ELT: The Subsequent Era of Information Integration Success
50 Years Of ETL: Can SQL For ETL Be Changed?