In hospital intensive care items (ICUs), steady affected person monitoring is vital. Medical gadgets generate huge quantities of real-time information on important indicators corresponding to coronary heart price, blood strain, and oxygen saturation. The important thing problem lies in early detection of affected person deterioration by means of important signal trending. Healthcare groups should course of 1000’s of knowledge factors every day per affected person to determine regarding patterns, a process essential for well timed intervention and doubtlessly life-saving care.
AWS Lambda occasion supply mapping will help on this situation by robotically polling information streams and triggering capabilities in real-time with out further infrastructure administration. By utilizing AWS Lambda for real-time processing of sensor information and storing aggregated ends in safe information buildings designed for giant analytic datasets referred to as Iceberg tables in Amazon Easy Storage Service (Amazon S3) buckets, medical groups can obtain each rapid alerting capabilities and acquire long-term analytical insights, enhancing their capacity to offer well timed and efficient care.
On this submit, we exhibit how you can construct a serverless structure that processes real-time ICU affected person monitoring information utilizing Lambda occasion supply mapping for rapid alert technology and information aggregation, adopted by persistent storage in Amazon S3 with an Iceberg catalog for complete healthcare analytics. The answer demonstrates how you can deal with high-frequency important signal information, implement vital threshold monitoring, and create a scalable analytics platform that may develop along with your healthcare group’s wants and assist monitor sensor alert fatigue within the ICU.
Structure
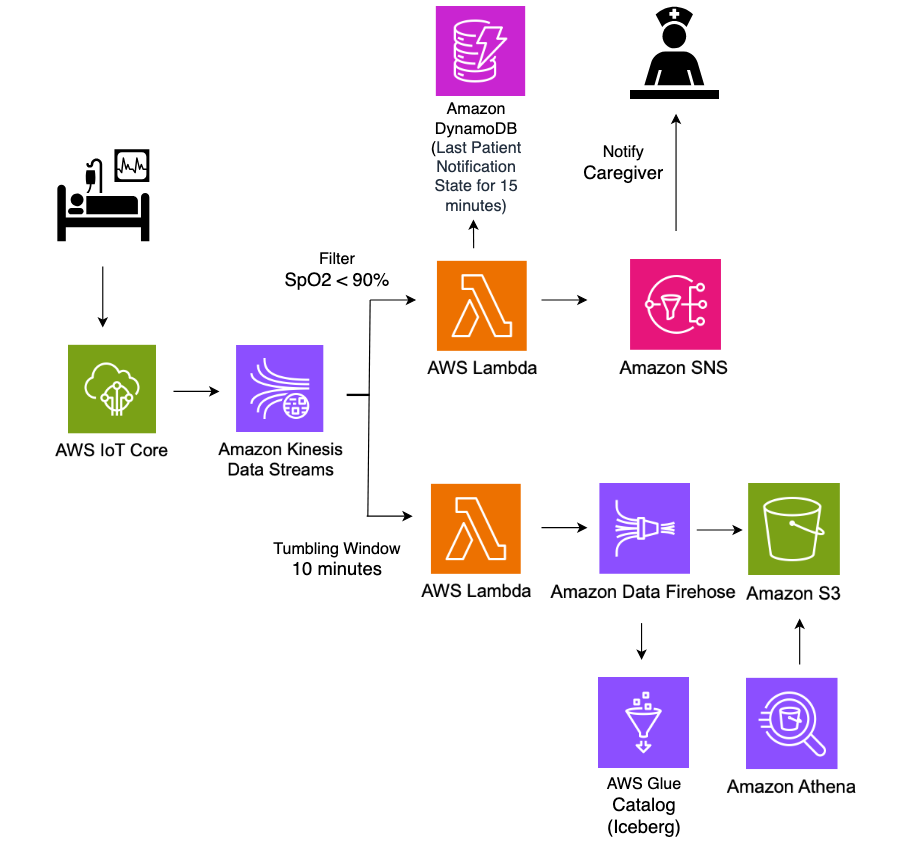
The next structure diagram illustrates a real-time ICU affected person analytics system.
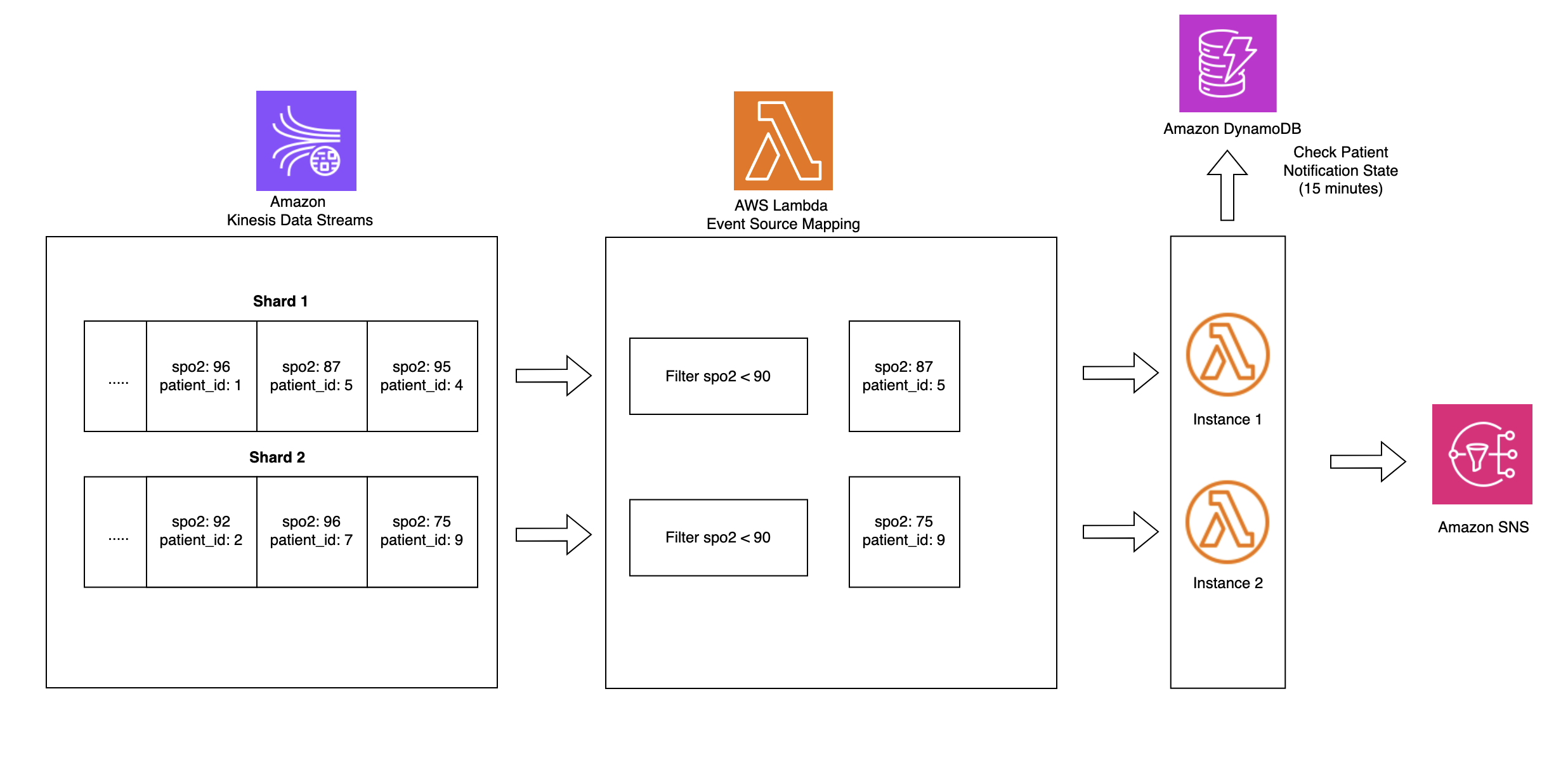
On this structure, real-time affected person monitoring information from hospital ICU sensors is ingested into AWS IoT Core, which then streams the information into Amazon Kinesis Information Streams. Two Lambda capabilities eat this streaming information concurrently for various functions, each utilizing Lambda occasion supply mapping integration with Kinesis Information Streams. The primary Lambda perform makes use of the filtering function of occasion supply mapping to detect vital well being occasions the place SpO2(blood oxygen saturation) ranges fall beneath 90%, instantly triggering notifications to caregivers by means of Amazon Easy Notification Service (Amazon SNS) for fast response. The second Lambda perform employs the tumbling window function of occasion supply mapping to mixture sensor information over 10-minute time intervals. This aggregated information is then systematically saved in S3 buckets in Apache Iceberg format for historic evaluation and reporting. All the pipeline operates in a serverless method, offering scalable, real-time processing of vital healthcare information whereas sustaining each rapid alerting capabilities and long-term information storage for analytics.
Amazon S3 information, with its assist for Apache Iceberg desk format, allows healthcare organizations to effectively retailer and question massive volumes of time-series affected person information. This resolution permits for advanced analytical queries throughout historic affected person information whereas sustaining excessive efficiency and value effectivity.
Conditions
To implement the answer supplied on this submit, it is best to have the next:
An lively AWS account
IAM permissions to deploy CloudFormation templates and provision AWS assets
Python put in in your machine to run the ICU affected person sensor information simulator code
Deploy a real-time ICU affected person analytics pipeline utilizing CloudFormation
You utilize AWS CloudFormation templates to create the assets for a real-time information analytics pipeline.
To get began, Sign up to the console as Account consumer and choose the suitable Area.
Amazon CloudWatch log teams to file for Kinesis Firehose exercise and Lambda capabilities.
Resolution walkthrough
Now that you just’ve deployed the answer, let’s assessment a purposeful walkthrough. First, simulate affected person important indicators information and ship it to AWS IoT Core utilizing the next Python code in your native machine. To run this code efficiently, guarantee you will have the required IAM permissions to publish messages to the IoT matter within the AWS account the place the answer is deployed.
import boto3
import json
import random
import time
# AWS IoT Information consumer
iot_data_client = boto3.consumer(
'iot-data',
region_name="us-west-2"
)
# IOT Subject to publish
matter="icu/sensors"
# Mounted set of affected person IDs
patient_ids = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print("Infinite sensor information simulation...")
attempt:
whereas True:
for patient_id in patient_ids:
# Generate sensor information
message = {
"patient_id": patient_id,
"timestamp": int(time.time()),
"spo2": random.randint(91, 99),
"heart_rate": random.randint(60, 100),
"temperature_f": spherical(random.uniform(97.0, 100.0), 1)
}
# Publish to matter
response = iot_data_client.publish(
matter=matter,
qos=1,
payload=json.dumps(message)
)
print(f"Printed: {message}")
# Wait 30 seconds earlier than subsequent spherical
print("Sleeping for 30 seconds...n")
time.sleep(30)
besides KeyboardInterrupt:
print("nSimulation stopped by consumer.")
The next is the format of a pattern ICU sensor message produced by the simulator.
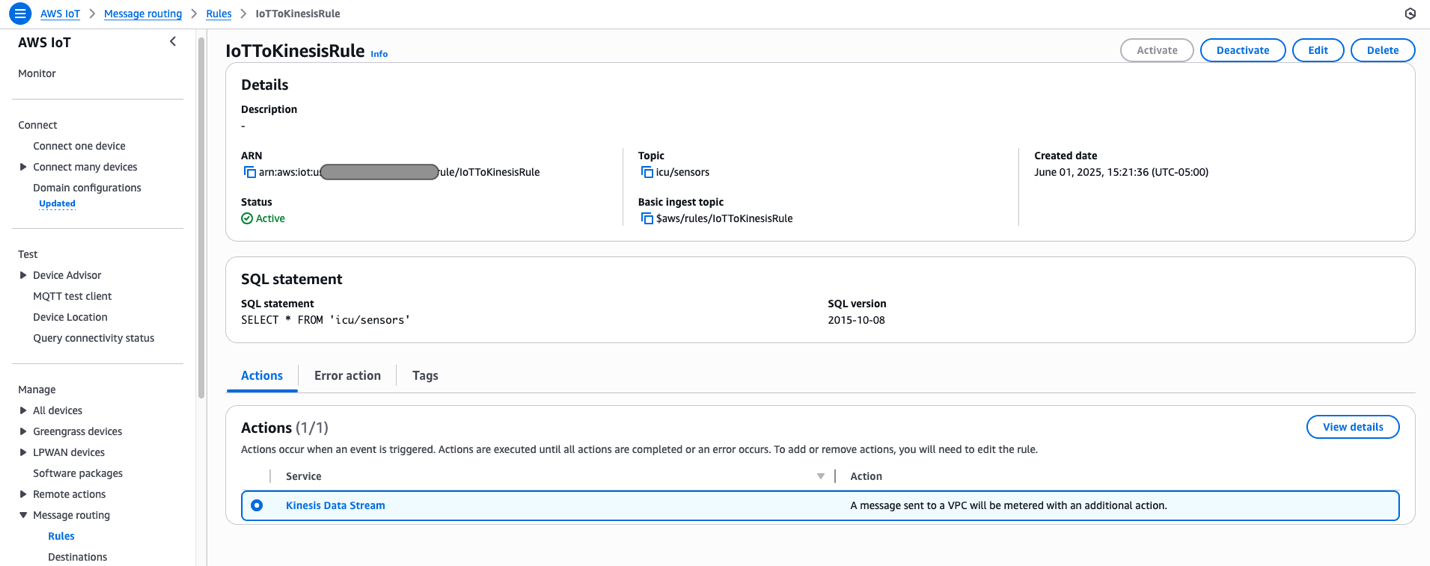
Information is printed to the icu/sensors IoT matter each 30 seconds for 10 completely different sufferers, making a steady stream of ICU affected person monitoring information. Messages printed to AWS IoT Core are handed to Kinesis Information Streams utilizing the next message routing rule deployed by our resolution.
Two Lambda capabilities eat information from Information Streams concurrently, each utilizing the Lambda occasion supply mapping integration with Kinesis Information Streams.
Occasion supply mapping
Lambda occasion supply mapping robotically triggers Lambda capabilities in response to information adjustments from supported occasion sources like Amazon DynamoDB Streams, Amazon Kinesis Information Streams, Amazon Easy Queue Service (Amazon SQS), Amazon MQ, and Amazon Managed Streaming for Apache Kafka. This serverless integration works by having Lambda ballot these sources for brand new information, that are then processed in configurable batch sizes starting from 1 to 10,000 information. When new information is detected, Lambda robotically invokes the perform synchronously, dealing with the scaling robotically based mostly on the workload. The service helps at-least-once supply and offers sturdy error dealing with by means of retry insurance policies and dead-letter queues for failed occasions. Occasion supply mappings could be fine-tuned by means of numerous parameters corresponding to batch home windows, most file age, and retry makes an attempt, making them extremely adaptable to completely different use instances. This function is especially beneficial in event-driven architectures, in order that prospects can deal with enterprise logic whereas AWS manages the complexities of occasion processing, scaling, and reliability.
Occasion supply mapping makes use of tumbling home windows and filtering to course of and analyze information.
Tumbling home windows
Tumbling home windows in Lambda occasion processing allow information aggregation in fastened, non-overlapping time intervals, the place every occasion belongs to precisely one window. That is superb for time-based analytics and periodic reporting. When mixed with occasion supply mapping, this strategy permits environment friendly batch processing of occasions inside outlined time durations (for instance, 10-minute home windows), enabling calculations corresponding to common important indicators or cumulative fluid consumption and output whereas optimizing perform invocations and useful resource utilization.
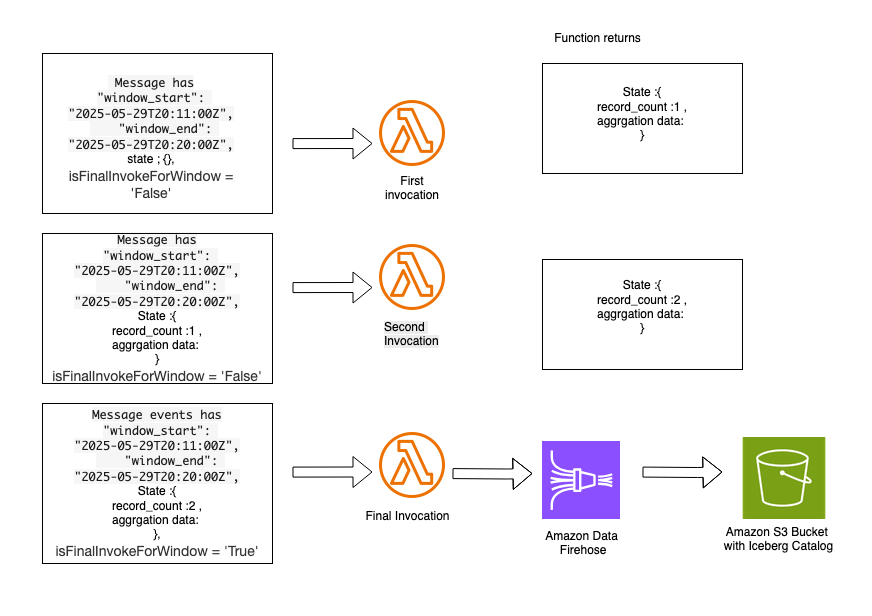
While you configure an occasion supply mapping between Kinesis Information Streams and a Lambda perform, use the Tumbling Window Period setting, which seems within the set off configuration within the Lambda console. The answer you deployed utilizing the CloudFormation template consists of the AggregateSensorData Lambda perform, which makes use of a 10-minute tumbling window configuration. Relying on the quantity of messages flowing by means of the Amazon Kinesis stream, the AggregateSensorData perform could be invoked a number of occasions for every 10-minute window, sequentially, with the next attributes within the occasion equipped to the perform.
Window begin and finish: The start and ending timestamps for the present tumbling window.
State: An object containing the state returned from the earlier window, which is initially empty. The state object can comprise as much as 1 MB of knowledge.
isFinalInvokeForWindow: Signifies if that is the final invocation for the tumbling window. This solely happens as soon as per window interval.
isWindowTerminatedEarly: A window ends early provided that the state exceeds the utmost allowed dimension of 1 MB.
In a tumbling window, there’s a sequence of Lambda invocations within the following sample:
AggregateSensorData Lambda code snippet:
def handler(occasion, context):
state_across_window = occasion['state']
# Iterate by means of every file and decode the base64 information
for file in occasion['Records']:
encoded_data = file['kinesis']['data']
partition_key = file['kinesis']['partitionKey']
decoded_bytes = base64.b64decode(encoded_data)
decoded_str = decoded_bytes.decode('utf-8')
decoded_json = json.hundreds(decoded_str)
# create partition_key attribute if it don't exists in state
if partition_key not in state_across_window:
state_across_window[partition_key] = {"min_spo2": decoded_json['spo2'], "max_spo2": decoded_json['spo2'], "avg_spo2": decoded_json['spo2'], "sum_spo2": decoded_json['spo2'], "min_heart_rate": decoded_json['heart_rate'], "max_heart_rate": decoded_json['heart_rate'], "avg_heart_rate": decoded_json['heart_rate'], "sum_heart_rate": decoded_json['heart_rate'], "min_temperature_f": decoded_json['temperature_f'], "max_temperature_f": decoded_json['temperature_f'], "avg_temperature_f": decoded_json['temperature_f'], "sum_temperature_f": decoded_json['temperature_f'], "record_count": 1}
else:
min_spo2 = state_across_window[partition_key]['min_spo2'] if state_across_window[partition_key]['min_spo2'] < decoded_json['spo2'] else decoded_json['spo2']
max_spo2 = state_across_window[partition_key]['max_spo2'] if state_across_window[partition_key]['max_spo2'] > decoded_json['spo2'] else decoded_json['spo2']
sum_spo2 = state_across_window[partition_key]['sum_spo2'] + decoded_json['spo2']
min_heart_rate = state_across_window[partition_key]['min_heart_rate'] if state_across_window[partition_key]['min_heart_rate'] < decoded_json['heart_rate'] else decoded_json['heart_rate']
max_heart_rate = state_across_window[partition_key]['max_heart_rate'] if state_across_window[partition_key]['max_heart_rate'] > decoded_json['heart_rate'] else decoded_json['heart_rate']
sum_heart_rate = state_across_window[partition_key]['sum_heart_rate'] + decoded_json['heart_rate']
min_temperature_f = state_across_window[partition_key]['min_temperature_f'] if state_across_window[partition_key]['min_temperature_f'] < decoded_json['temperature_f'] else decoded_json['temperature_f']
max_temperature_f = state_across_window[partition_key]['max_temperature_f'] if state_across_window[partition_key]['max_temperature_f'] > decoded_json['temperature_f'] else decoded_json['temperature_f']
sum_temperature_f = state_across_window[partition_key]['sum_temperature_f'] + decoded_json['temperature_f']
record_count = state_across_window[partition_key]['record_count'] + 1
avg_spo2 = sum_spo2/record_count
avg_heart_rate = sum_heart_rate/record_count
avg_temperature_f = sum_temperature_f/record_count
state_across_window[partition_key] = {"min_spo2": min_spo2, "max_spo2": max_spo2, "avg_spo2": avg_spo2, "sum_spo2": sum_spo2, "min_heart_rate": min_heart_rate, "max_heart_rate": max_heart_rate, "avg_heart_rate": avg_heart_rate, "sum_heart_rate": sum_heart_rate, "min_temperature_f": min_temperature_f, "max_temperature_f": max_temperature_f, "avg_temperature_f": avg_temperature_f, "sum_temperature_f": sum_temperature_f, "record_count": record_count}
# Decide if the window is ultimate (window finish)
is_final_window = occasion.get('isFinalInvokeForWindow', False)
# Decide if the window is terminated (window ended early)
is_terminated_window = occasion.get('isWindowTerminatedEarly', False)
window_start = occasion['window']['start']
window_end = occasion['window']['end']
if is_final_window or is_terminated_window:
firehose_client = boto3.consumer('firehose')
firehose_stream = os.environ['FIREHOSE_STREAM_NAME']
for key, worth in state_across_window.gadgets():
worth['patient_id'] = key
worth['window_start'] = window_start
worth['window_end'] = window_end
firehose_client.put_record(
DeliveryStreamName= firehose_stream,
Document={'Information': json.dumps(worth) }
)
return {
"state": {},
"batchItemFailures": []
}
else:
print(f"interim name for window: ws: {window_start} we: {window_end}")
return {
"state": state_across_window,
"batchItemFailures": []
}
The primary invocation comprises an empty state object within the occasion. The perform returns a state object containing customized attributes which might be particular to the customized logic within the aggregation.
The second invocation comprises the state object supplied by the primary Lambda invocation. This perform returns an up to date state object with new aggregated values. Subsequent invocations comply with this similar sequence. Following is a pattern of the aggregated state, which could be equipped to subsequent Lambda invocations throughout the similar 10-minute tumbling window.
The ultimate invocation within the tumbling window has the isFinalInvokeForWindow flag set to the true. This comprises the state returned by the latest Lambda invocation. This invocation is chargeable for passing aggregated state messages to the Information Firehose stream, which delivers information to the Amazon S3 bucket utilizing Iceberg information format.
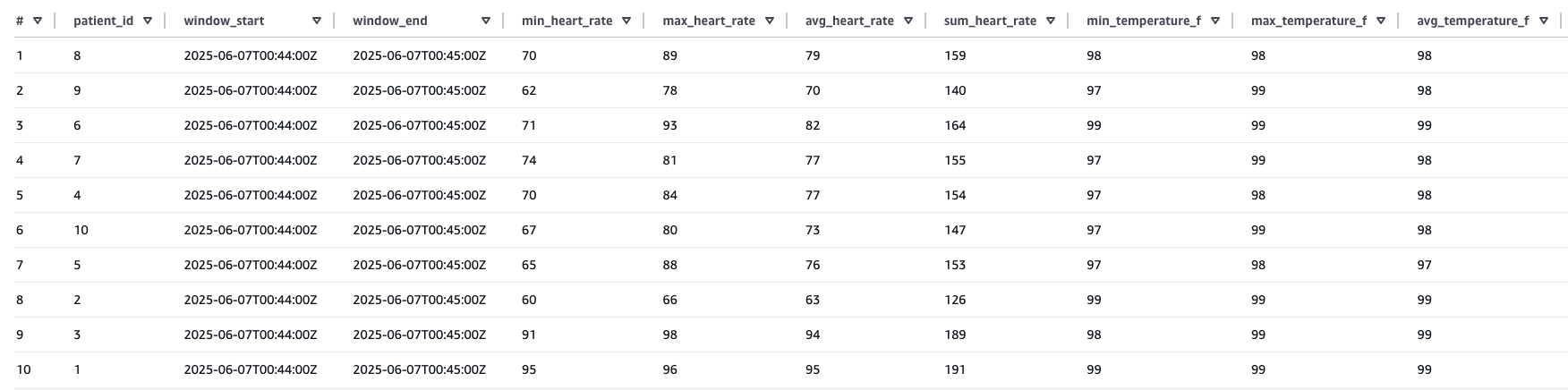
After the aggregated information is shipped to Amazon S3, you’ll be able to question the information utilizing Athena.
Question: SELECT * FROM "cfdb_<>"."table_<
>"
Pattern results of the previous Athena question:
Occasion supply mapping with filtering
Lambda occasion supply mapping with filtering optimizes information processing from sources like Amazon Kinesis by making use of JSON sample filtering earlier than perform invocation. That is demonstrated within the ICU affected person monitoring resolution, the place the system filters for SpO2 readings from Kinesis Information Streams which might be beneath 90%. As an alternative of processing all incoming information, the filtering functionality is used to selectively processes solely vital readings, considerably decreasing prices and processing overhead. The answer makes use of DynamoDB for classy state administration, monitoring low SpO2 occasions by means of a schema combining PatientID and timestamp-based keys inside outlined monitoring home windows.
This state-aware implementation balances medical urgency with operational effectivity by sending rapid Amazon SNS notifications when vital situations are first detected whereas implementing a 15-minute alert suppression window to stop alert fatigue amongst healthcare suppliers. By sustaining state throughout a number of Lambda invocations, the system helps guarantee fast response to doubtlessly life-threatening conditions whereas minimizing pointless notifications for a similar affected person situation. The mixing of Lambda’occasion filtering, DynamoDB state administration, and dependable alert supply supplied by Amazon SNS creates a strong, scalable healthcare monitoring resolution that exemplifies how AWS providers could be strategically mixed to deal with advanced necessities whereas balancing technical effectivity with medical effectiveness.
Filter sensor information Lambda code snippet:
sns_client = boto3.consumer('sns')
dynamodb = boto3.useful resource('dynamodb')
table_name = os.environ['DYNAMODB_TABLE']
sns_topic_arn = os.environ['SNS_TOPIC_ARN']
desk = dynamodb.Desk(table_name)
FIFTEEN_MINUTES = 15 * 60 # quarter-hour in seconds
def handler(occasion, context):
for file in occasion['Records']:
print(f"Aggregated occasion: {file}")
encoded_data = file['kinesis']['data']
partition_key = file['kinesis']['partitionKey']
decoded_bytes = base64.b64decode(encoded_data)
decoded_str = decoded_bytes.decode('utf-8')
# Verify final notification timestamp from DynamoDB
attempt:
response = desk.get_item(Key={'partition_key': partition_key})
merchandise = response.get('Merchandise')
now = int(time.time())
if merchandise:
last_sent = merchandise.get('timestamp', 0)
if now - last_sent < FIFTEEN_MINUTES:
print(f"Notification for {partition_key} skipped (despatched just lately)")
proceed
# Ship SNS Notification
sns_response = sns_client.publish(
TopicArn=sns_topic_arn,
Message=f"Affected person SpO2 beneath 90 proportion occasion data: {decoded_str}",
Topic=f"Low SpO2 detected for affected person ID {partition_key}"
)
print("Message despatched to SNS! MessageId:", sns_response['MessageId'])
# Replace DynamoDB with present timestamp and TTL
desk.put_item(Merchandise={
'partition_key': partition_key,
'timestamp': now,
'ttl': now + FIFTEEN_MINUTES + 60 # Add further buffer to TTL
})
besides Exception as e:
print("Error processing occasion:", e)
return {
'statusCode': 500,
'physique': json.dumps('Error processing occasion')
}
return {
'statusCode': 200,
'physique': {}
}
To generate an alert notification by means of the deployed resolution, replace the previous simulator code by setting the SpO2 worth to lower than 90 and run it once more. Inside 1 minute, it is best to obtain an alert notification on the e mail tackle you supplied throughout stack creation. The next picture is an instance of an alert notification generated by the deployed resolution.
Clear up
To keep away from ongoing prices after finishing this tutorial, delete the CloudFormation stack that you just deployed earlier on this submit. This may take away a lot of the AWS assets created for this resolution. You would possibly must manually delete objects created in Amazon S3, as a result of CloudFormation gained’t take away non-empty buckets throughout stack deletion.
Conclusion
As demonstrated on this submit, you'll be able to construct a serverless real-time analytics pipeline for healthcare monitoring through the use of AWS IoT Core, Amazon S3 buckets with iceberg format, and Amazon Kinesis Information Streams integration with AWS Lambda occasion supply mapping. This architectural strategy eliminates the necessity for advanced code whereas enabling fast vital affected person care alerts and information aggregation for evaluation utilizing Lambda. The answer is especially beneficial for healthcare organizations trying to modernize their affected person monitoring methods with real-time capabilities. The structure could be prolonged to deal with numerous medical gadgets and sensor information streams, making it adaptable for various healthcare monitoring situations. This submit presents one implementation strategy, and organizations adopting this resolution ought to make sure the structure and code meets their particular utility efficiency, safety, privateness, and regulatory compliance wants.
If this submit helps you or conjures up you to resolve an issue, we'd love to listen to about it!