You might need information in Amazon Easy Storage Service (Amazon S3) buckets in numerous AWS Areas that you really want accessible in a single Amazon OpenSearch Service area or assortment. Consolidating information throughout Areas offers unified analytics and searches, cut back operation complexity, and streamline your search infrastructure. We’re comfortable to announce that Amazon OpenSearch Ingestion pipelines can now learn from S3 buckets in numerous Areas to ingest and consolidate information right into a single OpenSearch Service area or assortment.
To consolidate this information throughout AWS Areas, you beforehand had to offer your personal resolution. Now Amazon OpenSearch Ingestion can assist you accomplish this. On this publish, I’ll present you use the brand new cross-Area assist to ingest information from S3 buckets throughout a number of AWS Areas right into a single OpenSearch Service area or assortment.
Amazon OpenSearch Ingestion (OSI) is a feature-rich information ingestion pipeline that you should use for a lot of totally different functions: observability, analytics, and zero-ETL search. Many purchasers use OpenSearch Ingestion to ingest information from Amazon S3 into OpenSearch Service domains and Amazon OpenSearch Serverless collections. Till now, you possibly can solely ingest from a single AWS Area at a time. Now that you should use OpenSearch Ingestion for cross-Area S3 ingestion, I’ll present you ways you should use it in two situations: batch processing utilizing S3 scan, and streaming ingestion utilizing Amazon Easy Queue Service (Amazon SQS) queues for AWS vended logs like Amazon Digital Non-public Cloud (Amazon VPC) Move Logs and AWS CloudTrail.
Conditions
Full the next prerequisite steps:
- Deploy an OpenSearch Service area or OpenSearch Serverless assortment within the Areas the place you need to carry out your search or analytics.
- You want S3 buckets in not less than two totally different Areas. You should use present ones or create S3 buckets. You should use one in the identical AWS Area as your OpenSearch Service area or assortment, or use two fully totally different Areas.
- Add objects with information into your S3 buckets. The info may be JSON, ND-JSON, Parquet, CSV, or plaintext codecs.
- Configure AWS Id and Entry Administration (IAM) permissions wanted for OSI. For directions, see Amazon S3 as a supply.
- For cross-Area ingestion, you have to now additionally embrace the s3:GetBucketLocation permission. This offers the pipeline the power to find out which AWS Area the bucket is positioned in.
After you full these steps, you’ll be able to both arrange your Amazon OpenSearch Ingestion pipelines for batch or streaming situations. Within the following sections, I’ll provide you with suggestions on when to decide on which method, and I define the steps for creating your pipeline.
Batch situations
You should use the OpenSearch Ingestion S3 scan functionality to learn batch information from S3. You would possibly discover this method helpful when your information is written to S3 on a schedule. To carry out a cross-Area S3 scan, you solely specify the buckets that you simply’re studying from while you create the OpenSearch Ingestion pipeline.
The next diagram exhibits the design for an OpenSearch Ingestion pipeline in us-west-2 studying from S3 buckets in us-east-1 and eu-west-1 and writing that information into an OpenSearch Service area in us-west-2.
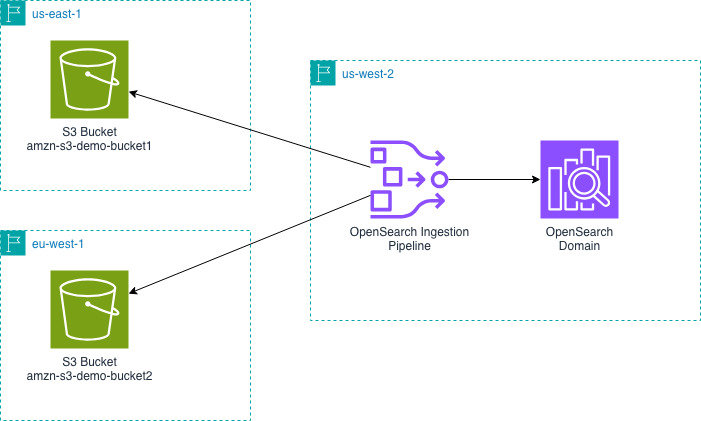
Subsequent, you’ll create an OpenSearch Ingestion pipeline. You have to create this pipeline in the identical Area as your OpenSearch Service area or assortment.
The earlier pipeline configuration helps the JSON codec. You would possibly need to configure a distinct codec in case your information isn’t a big JSON object.
Now you can question your OpenSearch Service area or assortment to see the information that you simply ingested.
Streaming situations: AWS vended logs
Like lots of our clients, you would possibly need to ingest S3 information from totally different AWS Areas into OpenSearch Service. A standard purpose is to consolidate AWS vended logs. For instance, VPC Move Logs, CloudTrail information, and cargo balancer logs. For these situations, you’ll be able to configure OpenSearch Ingestion pipelines to learn from an Amazon SQS queue to stream information into your OpenSearch Service area or assortment.
These AWS vended logs write to Amazon S3 in the identical AWS Area because the service working it. For instance, VPC Move Logs will likely be in the identical AWS Area as your Amazon VPC. You should use OpenSearch Ingestion to consolidate these logs into one AWS Area. Within the VPC Move Logs instance, you’ll be able to consolidate your VPC Move Logs from a number of AWS Areas right into a single OpenSearch Service area or assortment to research community patterns out of your totally different Amazon VPCs.
The next diagram outlines the general setup. It exhibits an instance of sending AWS vended logs from us-east-1 and eu-west-1 to an OpenSearch Service area in us-west-2. You possibly can change the AWS Areas relying in your particular wants.
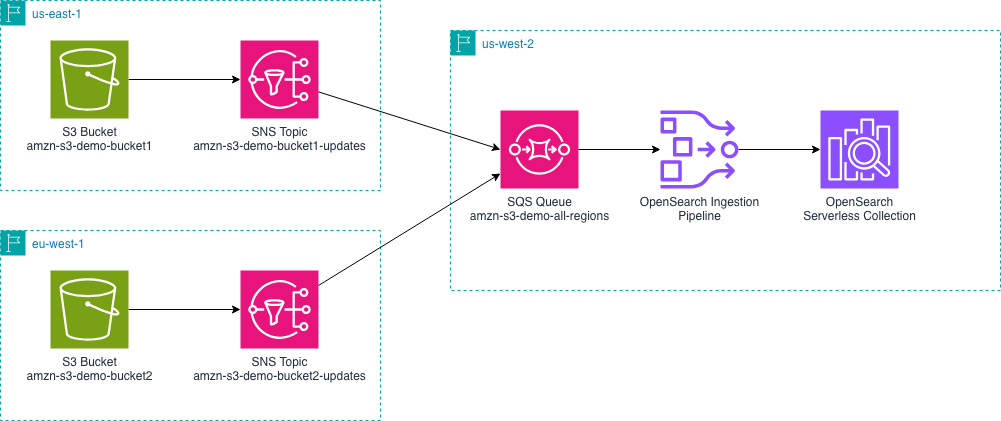
- You have to configure your vended logs to write down log occasions to Amazon S3 buckets of their respective AWS Areas. Utilizing VPC Move Logs as our instance, you’ll be able to configure VPC Move Logs to your VPCs.
- Create an Amazon SQS queue in the identical AWS Area as your OpenSearch Service area.
- Amazon S3 doesn’t ship notifications to cross-Area Amazon SQS queues, so you’ll use intermediate Amazon Easy Notification Service (Amazon SNS) subjects to consolidate the notifications from a number of Areas into one queue. For every S3 bucket, create an SNS matter.
- Configure S3 Occasion Notifications for SNS. You’ll do that for every S3 bucket and every SNS matter.
- SNS can ship cross-Area notifications to SQS. Create a subscription from every SNS matter that you simply created in step 3 to the one SQS queue you created in step 2.
- Configure your pipeline position to learn from SQS and skim from the related S3 buckets.
Now create an OpenSearch Ingestion pipeline in the identical AWS Area as your OpenSearch Service area.
The earlier pipeline configuration helps the JSON codec. You would possibly need to configure a distinct codec in case your information isn’t a big JSON object.
Subsequent, add objects with information into your S3 buckets. By importing information, S3 will ship notifications to SNS after which the SQS queue.
Now you can question your OpenSearch Service area or assortment to see the information that you simply ingested.
Here’s what makes this attainable and what’s totally different. The SQS queue receives the occasion notifications for the buckets. Earlier than the cross-Area characteristic of OpenSearch Ingestion, the pipeline might see these occasions, however couldn’t entry the S3 bucket even when the permissions had been granted. Now, the pipeline will decide the AWS Area that the bucket is in, entry an AWS Safety Token Service (AWS STS) token for the AWS Area of the bucket. Utilizing the STS token from the identical Area because the S3 bucket permits the pipeline to learn and entry the information.
Utilizing the AWS Console
Whenever you create the pipeline utilizing the OpenSearch Ingestion console, you should have choices to pick a blueprint to your use-case. These blueprints assist you create pipelines for varied vended log varieties solely by choosing your SQS queue and OpenSearch area. The blueprint handles the information sort mappings for you by together with acceptable processors. You should use these blueprints as a place to begin and modify your processors to your particular necessities.
Clear up assets
Whenever you’re accomplished testing this out, use the next assets to delete the assets that you simply created.
For those who arrange a batch pipeline:
- Delete the OpenSearch Ingestion pipeline.
For those who arrange a streaming pipeline:
For each pipelines, these steps assist you delete the widespread assets.
Conclusion
On this publish, I confirmed you ways you should use Amazon OpenSearch Ingestion to ingest information from Amazon S3 buckets in numerous AWS Areas. I confirmed that this works for each batch scan and streaming situations. The characteristic gives you an easy option to consolidate your information from different Areas into one OpenSearch Service area or assortment.
To get began with the cross-Area S3 supply, confer with the OpenSearch Ingestion documentation or attempt making a pipeline from one in every of our blueprints utilizing the OpenSearch Ingestion console. You possibly can learn in regards to the codecs that OpenSearch Ingestion gives for parsing your S3 objects. You may as well find out how in regards to the varied processors that OpenSearch Ingestion gives, so you’ll be able to rework and enrich your information to satisfy your wants.
You may as well use OpenSearch Ingestion for cross-Area and cross-account. To do that, you have to grant cross-account permissions in your S3 bucket. You have to additionally make some modifications to your pipeline configuration. Combining what I confirmed you on this publish with the present cross-account options significantly expands your ingestion choices.
For those who’re able to take your streaming ingestion analytics to the subsequent stage you’ll be able to examine generate metrics from logs and even ship these derived metrics to Amazon Managed Service for Prometheus.
Have you ever tried out the cross-Area capabilities of OpenSearch Ingestion? Share your use-cases and questions within the feedback.
Concerning the authors