There will be some sensible constraints on the subject of deploying the AI fashions for retail environments. Retail environments can embody store-level techniques, edge gadgets, and finances aware setup, particularly for small to medium-sized retail corporations. One such main use case is demand forecasting for stock administration or shelf optimization. It requires the deployed mannequin to be small, quick, and correct.
That’s precisely what we are going to work on right here. On this article, I’ll stroll you thru three compression strategies step-by-step. We are going to begin by constructing a baseline LSTM. Then we are going to measure its dimension and accuracy, after which apply every compression technique separately to see the way it modifications the mannequin. On the finish, we are going to deliver all the pieces along with a side-by-side comparability.
So, with none delay, let’s dive proper in.
The Drawback: Retail AI on the Edge
As all the pieces is now transferring to the sting, Retail can also be transferring in direction of store-level cellular apps, gadgets, and IOT sensors, which may run the fashions and predict the forecast domestically relatively than calling the cloud APIs each time.
A forecast mannequin working on a retailer machine or cellular app, like a shelf sensor or scanner, can face constraints corresponding to restricted reminiscence, restricted battery, and requires low community latency.
Even for cloud deployments, if the mannequin dimension is smaller, it will probably decrease the prices. Particularly when you find yourself working hundreds of predictions every day throughout an enormous product catalog. A mannequin with dimension 4KB prices considerably lower than a mannequin with dimension 64KB
Not simply price, inference velocity additionally impacts the real-time selections. Quicker mannequin prediction can profit stock optimization and restocking alerts.
Benchmarking Setup
For the experiment, I utilized the Kaggle Merchandise Demand forecasting information set on the retailer stage. The information is unfold over 5 years of every day gross sales throughout 10 shops and 50 gadgets. This public information set has a retail sample with weekly seasonality, traits, and noise.
For this, I used pattern information of 5 shops, 10 gadgets, and created 50 separate time collection. Every of the shop merchandise mixtures generates its personal sequences, which is able to lead to a complete of 72,000 coaching pattern information. The mannequin will predict the subsequent day’s gross sales information based mostly on the previous 14 days’ gross sales historical past, which is a standard setup for demand forecasting information.
The experiment was run 3 instances and averaged for dependable outcomes.
| Parameter | Particulars |
|---|---|
| Dataset | Kaggle Retailer Merchandise Demand Forecasting Dataset |
| Pattern | 5 shops × 10 gadgets = 50 time collection |
| Coaching Samples | ~72,000 complete samples |
| Sequence Size | 14 days previous information |
| Job | Single-step every day gross sales prediction |
| Metric | Imply Absolute Share Error (MAPE) |
| Runs per Mannequin | 3 instances, averaged |
Step 1: Constructing the Baseline LSTM
Earlier than compressing something, we want a reference level. Our baseline is a regular LSTM with 64 hidden models educated on the dataset described above.
Baseline Code:
from tensorflow.keras.fashions import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout
def build_lstm(models, seq_length):
"""Construct LSTM with specified hidden models."""
mannequin = Sequential([
LSTM(units, activation='tanh', input_shape=(seq_length, 1)),
Dropout(0.2),
Dense(1)
])
mannequin.compile(optimizer="adam", loss="mse")
return mannequin
# Baseline: 64 hidden models
baseline_model = build_lstm(64, seq_length=14) Baseline Efficiency:
| Technique | Mannequin | Measurement (KB) | MAPE (%) | MAPE Std (%) |
|---|---|---|---|---|
| Baseline | LSTM-64 | 66.25 | 15.92 | ±0.10 |
That is our reference level. The LSTM-64 mannequin is 66.25KB in dimension with a MAPE of 15.92%. Each compression approach under can be measured in opposition to these numbers.
Step 2: Compression Approach 1 — Structure Sizing
On this method, we cut back the mannequin capability by a couple of hidden models. As a substitute of a 64-unit LSTM, we practice a 32/16-unit mannequin from scratch and see the way it performs. This can be a less complicated method among the many three.
Code:
# Utilizing the identical build_lstm operate from baseline
# Evaluate: 64 models (66KB) vs 32 models vs 16 models
model_32 = build_lstm(32, seq_length=14)
model_16 = build_lstm(16, seq_length=14)Outcomes:
| Technique | Mannequin | Measurement (KB) | MAPE (%) | MAPE Std (%) |
|---|---|---|---|---|
| Baseline | LSTM-64 | 66.25 | 15.92 | ±0.10 |
| Structure | LSTM-32 | 17.13 | 16.22 | ±0.09 |
| Structure | LSTM-16 | 4.57 | 16.74 | ±0.46 |
Evaluation: The LSTM-16 mannequin is 14.5x smaller than 64 bit mannequin (4.57KB vs 66.25KB), whereas MAPE is elevated solely by 0.82%. For lots of purposes in retail, this distinction is minute, whereas the LSTM 32 mannequin presents a center floor with 3.9x compression, having 0.3% accuracy loss.
Step 3: Compression Approach 2 — Magnitude Pruning
Pruning is to take away low-importance weights from mannequin coaching. The core concept is that the contributions of many neural community connections are minimal and will be ignored or set to zero. After the pruning, the mannequin is fine-tuned to get well the accuracy.
Code:
import numpy as np
from tensorflow.keras.optimizers import Adam
def apply_magnitude_pruning(mannequin, target_sparsity=0.5):
"""Apply per-layer magnitude pruning, skip biases"""
masks = []
for layer in mannequin.layers:
weights = layer.get_weights()
layer_masks = []
new_weights = []
for w in weights:
if w.ndim == 1: # Bias - do not prune
layer_masks.append(None)
new_weights.append(w)
else: # Kernel - prune per-layer
threshold = np.percentile(np.abs(w), target_sparsity * 100)
masks = (np.abs(w) >= threshold).astype(np.float32)
layer_masks.append(masks)
new_weights.append(w * masks)
masks.append(layer_masks)
layer.set_weights(new_weights)
return masks
# After pruning, fine-tune with decrease studying price
mannequin.compile(optimizer=Adam(learning_rate=0.0001), loss="mse")
mannequin.match(X_train, y_train, epochs=50, callbacks=[maintain_sparsity])Outcomes:
| Technique | Mannequin | Measurement (KB) | MAPE (%) | MAPE Std (%) |
|---|---|---|---|---|
| Baseline | LSTM-64 | 66.25 | 15.92 | ±0.10 |
| Pruning | Pruned-30% | 11.99 | 16.04 | ±0.09 |
| Pruning | Pruned-50% | 8.56 | 16.20 | ±0.08 |
| Pruning | Pruned-70% | 5.14 | 16.84 | ±0.16 |
Evaluation: With Magnitude Pruning at 50% sparsity, the mannequin dimension has dropped to eight.56KB with solely 0.28% accuracy loss in comparison with the baseline. Even with 70% Pruning, MAPE was underneath 17%.
The vital discovering to make pruning work on LSTMs was utilizing thresholds at each layer as an alternative of a worldwide threshold, skipping bias weights (utilizing solely kernel weights), and in addition utilizing a decrease studying price throughout fine-tuning. With out these, LSTM efficiency can degrade considerably because of the interdependency of recurrent weights.
Step 4: Compression Approach 3 — INT8 Quantization
Quantization offers with the conversion of 32-bit floating level weights to 8-bit integers post-training which is able to cut back the mannequin dimension by 4 instances with out dropping a lot of accuracy.
Code:
def simulate_int8_quantization(mannequin):
"""Simulate INT8 quantization on mannequin weights."""
for layer in mannequin.layers:
weights = layer.get_weights()
quantized = []
for w in weights:
w_min, w_max = w.min(), w.max()
if w_max - w_min > 1e-10:
# Quantize to INT8 vary [0, 255]
scale = (w_max - w_min) / 255.0
zero_point = np.spherical(-w_min / scale)
w_int8 = np.spherical(w / scale + zero_point).clip(0, 255)
# Dequantize
w_quant = (w_int8 - zero_point) * scale
else:
w_quant = w
quantized.append(w_quant.astype(np.float32))
layer.set_weights(quantized)For manufacturing deployment, it’s beneficial to make use of TensorFlow Lite’s built-in quantization:
import tensorflow as tf
converter = tf.lite.TFLiteConverter.from_keras_model(mannequin)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_model = converter.convert()Outcomes:
| Technique | Mannequin | Measurement (KB) | MAPE (%) | MAPE Std (%) |
|---|---|---|---|---|
| Baseline | LSTM-64 | 66.25 | 15.92 | ±0.10 |
| Quantization | INT8 | 4.28 | 16.21 | ±0.22 |
Evaluation: INT8 quantization has decreased the mannequin dimension to 4.28KB from 66.25KB(15.5x compression) with 0.29% enhance in accuracy. That is the smallest mannequin with accuracy similar to the unpruned LSTM 32 mannequin. Specifically for deployments, INT8 inference is supported, and it’s the greatest amongst 3 strategies.
Bringing It All Collectively: Facet-by-Facet Comparability
Right here’s how every approach compares in opposition to the LSTM-64 baseline:
| Approach | Compression Ratio | Accuracy Affect |
|---|---|---|
| LSTM-32 | 3.9x | +0.30% MAPE |
| LSTM-16 | 14.5x | +0.82% MAPE |
| Pruned-30% | 5.5x | +0.12% MAPE |
| Pruned-50% | 7.7x | +0.28% MAPE |
| Pruned-70% | 12.9x | +0.92% MAPE |
| INT8 Quantization | 15.5x | +0.29% MAPE |
The complete benchmark outcomes throughout all strategies:
| Technique | Mannequin | Measurement (KB) | MAPE (%) | MAPE Std (%) |
|---|---|---|---|---|
| Baseline | LSTM-64 | 66.25 | 15.92 | ±0.10 |
| Structure | LSTM-32 | 17.13 | 16.22 | ±0.09 |
| Structure | LSTM-16 | 4.57 | 16.74 | ±0.46 |
| Pruning | Pruned-30% | 11.99 | 16.04 | ±0.09 |
| Pruning | Pruned-50% | 8.56 | 16.20 | ±0.08 |
| Pruning | Pruned-70% | 5.14 | 16.84 | ±0.16 |
| Quantization | INT8 | 4.28 | 16.21 | ±0.22 |
Every one of many above strategies comes with its personal tradeoffs. Structure sizing can cut back the mannequin dimension, however it wants retraining of the mannequin. Pruning will protect the structure however filters the connections. Quantization will be quick however requires appropriate inference runtimes.
Selecting the Proper Approach
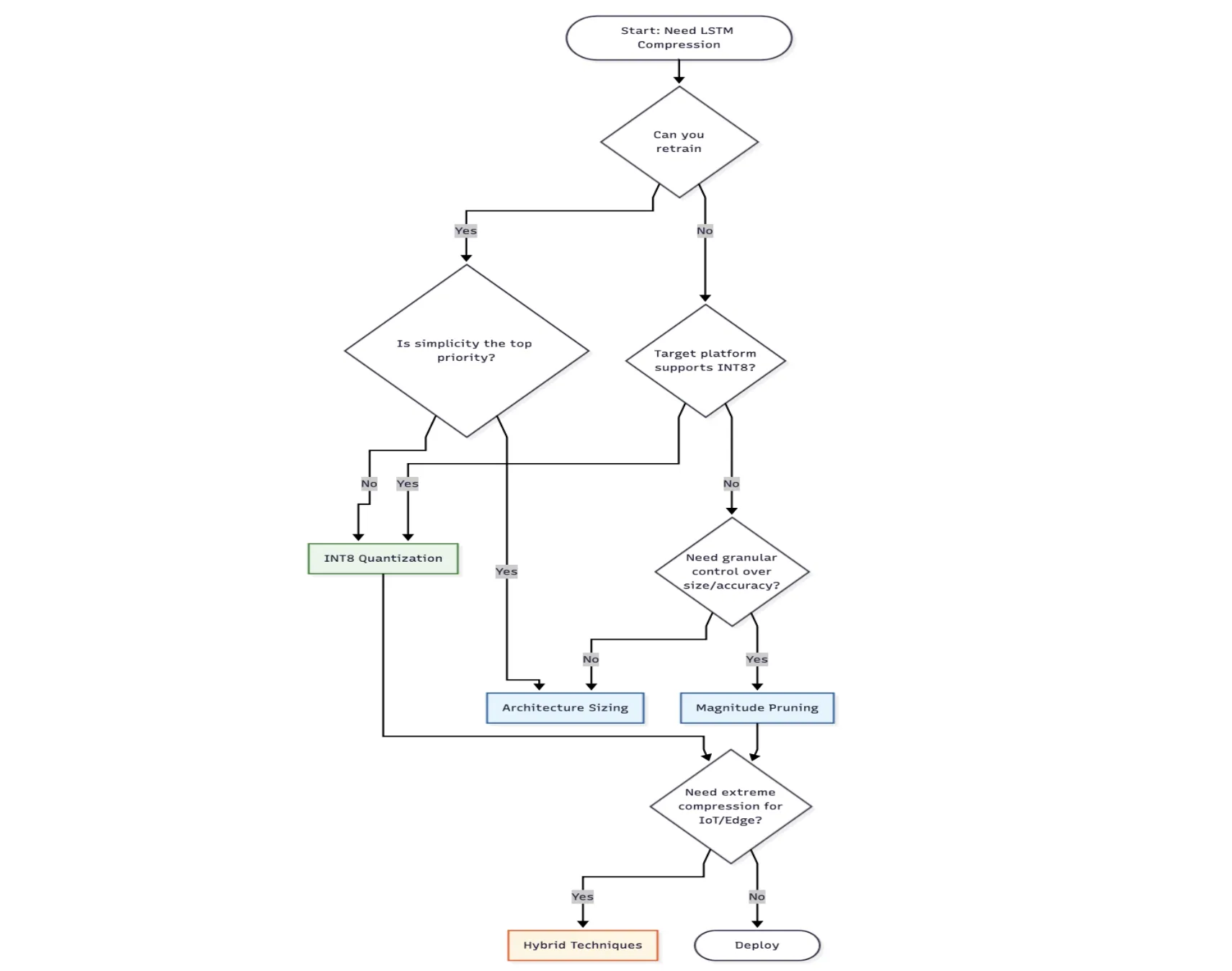
Select Structure Sizing when:
- You’re ranging from scratch and may practice
- Simplicity issues greater than most compression
Choose Pruning when:
- You have already got a educated mannequin and are searching for mannequin compression
- You want granular-level management over the accuracy-size tradeoff
Go for Quantization when:
- You want most compression with minimal accuracy loss
- Your goal deployment platform has INT8 optimization (Ex, cellular, edge gadgets)
- You desire a fast resolution with out retraining from the start.
Select hybrid strategies when:
- Heavy compression is required (edge deployment, IoT)
- You possibly can make investments time in iterating on the compression pipeline
Factors to Keep in mind for Retail Deployment
Mannequin compression is only one a part of the puzzle. There are different components to think about for retail techniques, as given under.
- A Bigger mannequin is all the time higher than a smaller mannequin which is stale. Construct retraining into your pipeline as retail patterns change with seasons, traits, promotions, and many others.
- Benchmarks from an area machine can’t be matched with a manufacturing surroundings machine. Particularly, the quantized fashions can behave otherwise on totally different platforms.
- Monitoring is a key factor in manufacturing, as compression may cause refined accuracy degradation. All mandatory alerts and paging should be in place.
- At all times take into account the whole system price as a 4KB mannequin that wants a specialised sparse inference runtime may cost a little greater than deploying a daily 17KB mannequin, which runs in all places.
Conclusion
To conclude, all three compression strategies can ship vital dimension reductions whereas sustaining correct accuracy.
Structure sizing is the best amongst 3. An LSTM-16 delivers 14.5x compression with lower than 1% accuracy loss.
Pruning presents extra management. With correct execution (per-layer thresholds, skip biases, low studying price fine-tuning), 70% pruning achieves 12.9x compression.
INT8 quantization achieves the most effective tradeoff with 15.5x compression with solely 0.29% enhance in accuracy.
Selecting the most effective approach will rely in your limitations and constraints. If a easy resolution is required, then begin with structure sizing. If wanted, a most stage of compression with minimal accuracy loss, go together with quantization. Select pruning primarily while you want a fine-grained management over the compression accuracy tradeoff.
For edge deployments that assist the in-store gadgets, tablets, shelf sensors, or scanners, the mannequin dimension (4KB vs 66KB) can decide in case your AI runs domestically on the machine or require a steady cloud connectivity.
Ravi Teja Pagidoju is a Senior Engineer with 9+ years of expertise
constructing AI/ML techniques for retail optimization and provide chain. He holds an MS in Pc Science and has revealed analysis on hybrid LLM-optimization approaches in IEEE and Springer publications.
Login to proceed studying and luxuriate in expert-curated content material.