Introduction
Advantage Basis is a nonprofit targeted on world well being supply and creating an environment friendly market for world philanthropic healthcare. Thus far, they’ve delivered care to over 50,000 sufferers with a particular concentrate on Ghana and Mongolia. The spine of this market is the curation of worldwide healthcare facility knowledge via VF Match, a platform that connects medical professionals to volunteer alternatives in 72 low and low-middle revenue international locations. Databricks for Good has been partnering carefully with Advantage Basis since 2024 to leverage AI to mixture knowledge throughout these international locations and make it actionable.
An preliminary proof of idea demonstrated that LLMs may extract structured data from disparate net knowledge sources to create a map of healthcare infrastructure and, most significantly, the gaps in providers in under-resourced areas. Nonetheless, scaling this performance and shifting it into manufacturing posed many challenges. Since that first iteration, we’ve constructed a Databricks-based platform that has remodeled the POC right into a production-grade system aggregating knowledge from 1000’s of healthcare amenities and non-profits throughout the globe.
On this article, we stroll via how we improved on our earlier work to additional allow Advantage Basis to match their group of medical volunteers with important wants in these international locations.
Constructing the Basis: 72 International locations of Healthcare Information
The core of VF Match is the Foundational Information Refresh (FDR): a complete healthcare facility and nonprofit dataset constructed from the bottom up from varied web-based sources. We systematically ingest and refresh knowledge from 72 low and low-middle revenue international locations throughout the globe.
Two complementary knowledge sources energy this refresh:
- Overture Maps: An open-source geospatial dataset by Meta and Microsoft, offering authoritative places for healthcare amenities.
- Vibrant Information: Industrial web-scraping infrastructure that captures real-time data from throughout the web.
The center of FDR is an data extraction pipeline powered by OpenAI’s GPT fashions. Processing greater than 25 million net pages via LLMs with manufacturing ensures required rethinking conventional LLM inference pipelines. Reasonably than trying one-shot extraction, our pipeline breaks the duty into focused steps: classifying medical relevance, figuring out group kind (both a medical facility or NGO), and extracting specialties, gear, and procedures.
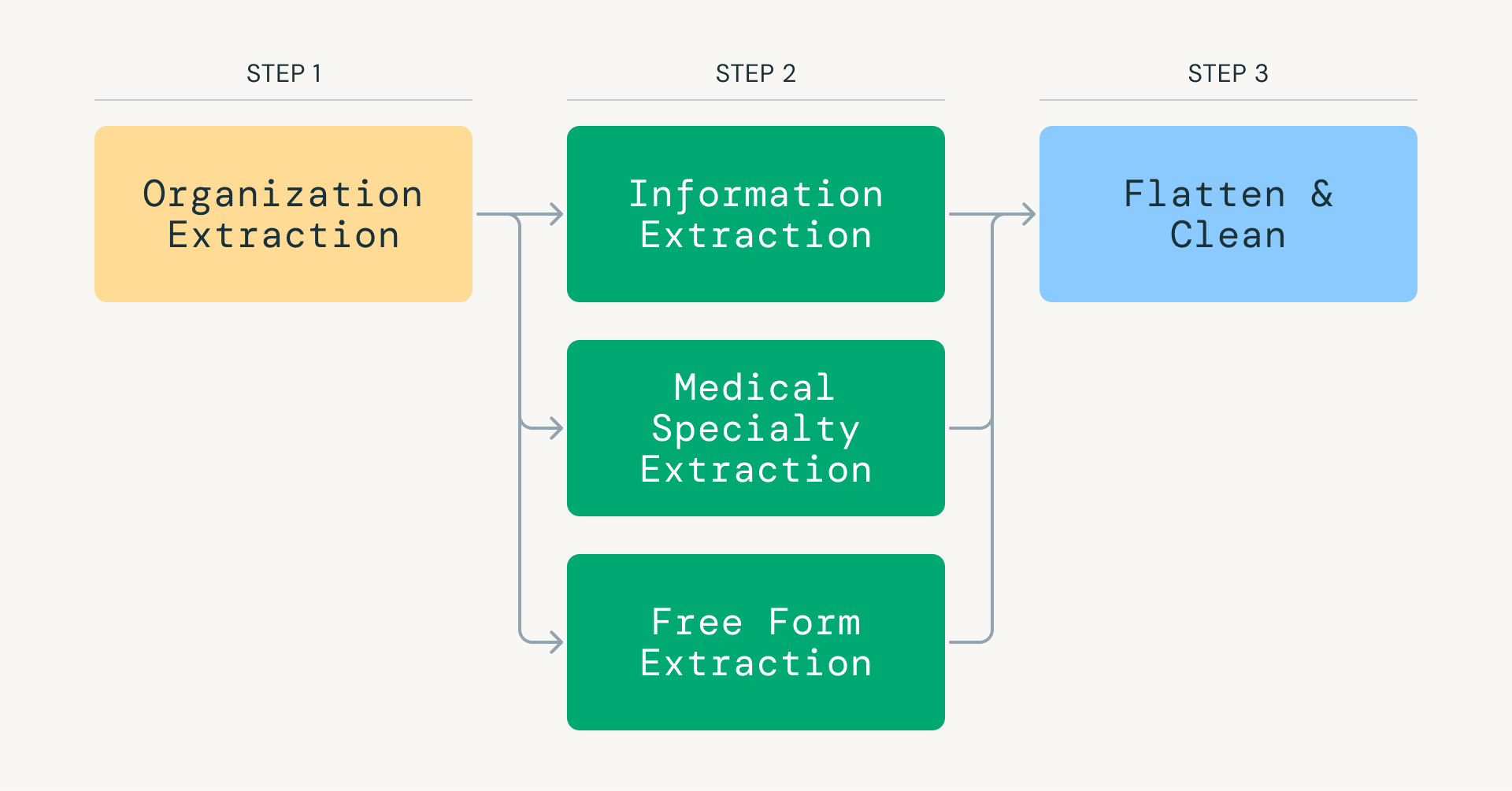
This method dramatically reduces token consumption whereas focusing every mannequin invocation on a slim, high-precision process. Databricks and Apache Spark are used to effectively orchestrate and parallelize the scraped knowledge, distributing workloads throughout 1000’s of executors and enabling high-throughput LLM inference.
Various important options make this pipeline scalable and prepared for manufacturing:
- Extensible knowledge modeling: Information at every step is saved in a star schema, simplifying downstream analytics and enhancing question efficiency.
- Standing-based checkpointing: Each report tracks its processing state, enabling pipelines to renew from any level with out reprocessing rows with costly LLM calls.
- Configurable extraction registry: Every extraction methodology is managed by a structured object specifying the system immediate, making extraction logic modular, reproducible, and extensible.
- Scalable distributed processing: The system processes skewed, multi-terabyte workloads utilizing Spark for parallelism, Photon for efficiency at scale, and production-grade orchestration.
These ensures are enforced via Lakeflow Jobs, which orchestrate greater than 15 interdependent duties with conditional branching, parallel execution, and clever retry insurance policies. The result’s a system that processes healthcare facility knowledge at scale with the precision of medical consultants.
Entity Decision at Scale
As soon as the power and nonprofit knowledge is scraped and extracted utilizing an LLM, a basic problem emerges: entity decision. The identical facility might seem throughout a number of knowledge sources with title variations, inconsistent addresses, or lacking contact particulars. Conventional deduplication breaks down in these eventualities because of messy knowledge, so we use Splink, an open supply probabilistic report linkage framework. Utilizing the knowledge sourced in our IE step, Splink evaluates match pairs through weighted comparisons throughout fields like cellphone quantity, road deal with, and extra. The result’s a unified key per facility, making certain that finish customers see one authoritative report for every medical facility and NGO.
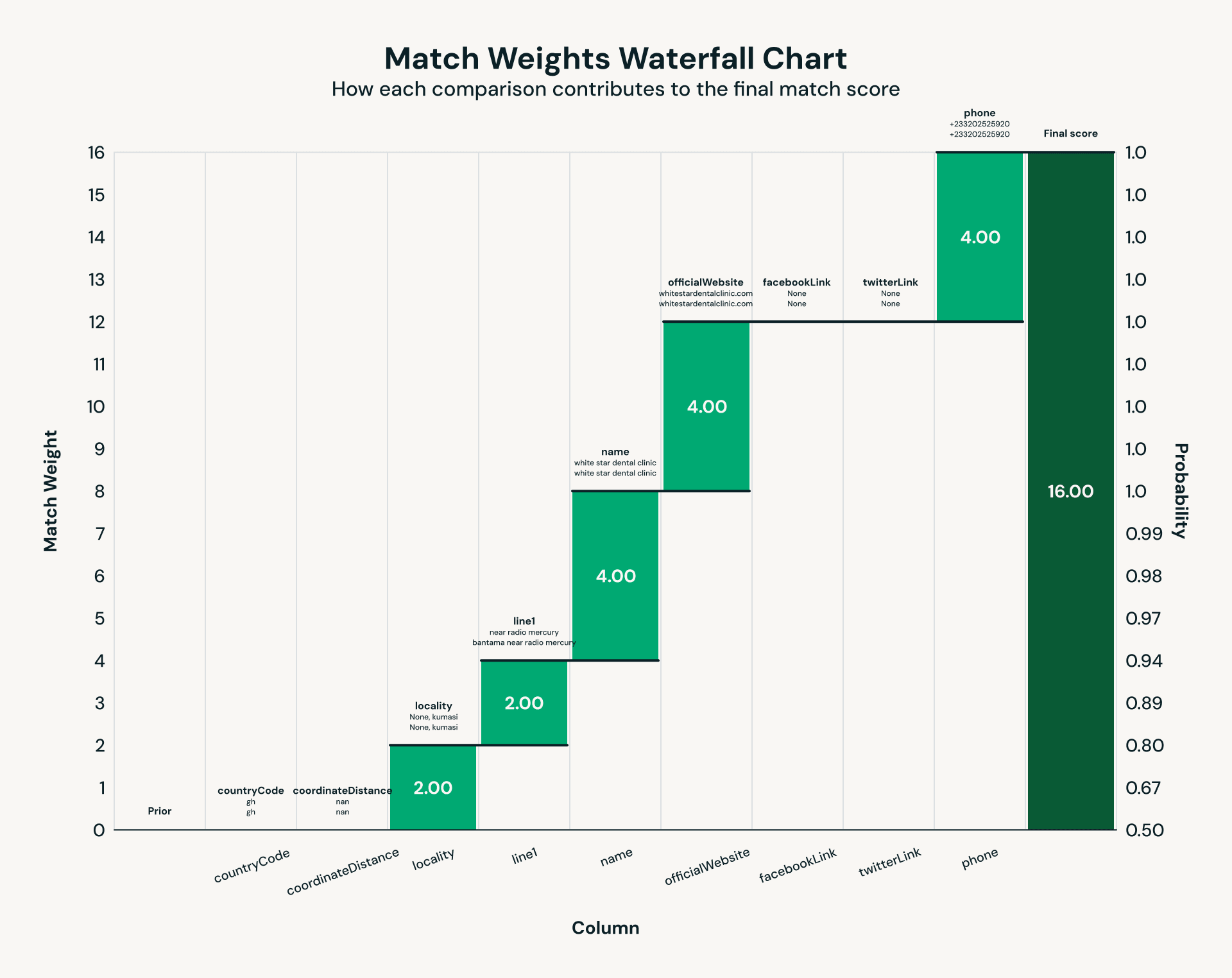
Operating probabilistic matching throughout 1000’s of healthcare amenities and non-profits revealed basic efficiency bottlenecks that emerge at terabyte scale. The core of report linkage is pairwise comparability, which creates inherently skewed workloads: widespread comparisons produce huge partitions whereas most others stay a lot smaller. Early runs made this painfully clear, with one Spark partition operating for half-hour whereas the median accomplished in 52 seconds – a textbook case of stragglers (the “curse of the final reducer”) degrading job efficiency. Enabling Photon, Databricks’ vectorized question engine, lowered worst-case knowledge partitions from half-hour to roughly 2 minutes: a 15x enchancment.
VF Agent: Pure Language Meets Healthcare Information
Seeking to the longer term, we have now developed a prototype of an agent that permits consultants to research knowledge utilizing pure language. We use a multi-agent structure inbuilt LangGraph and leverage Databricks Mannequin Serving, Vector Search, and Genie.
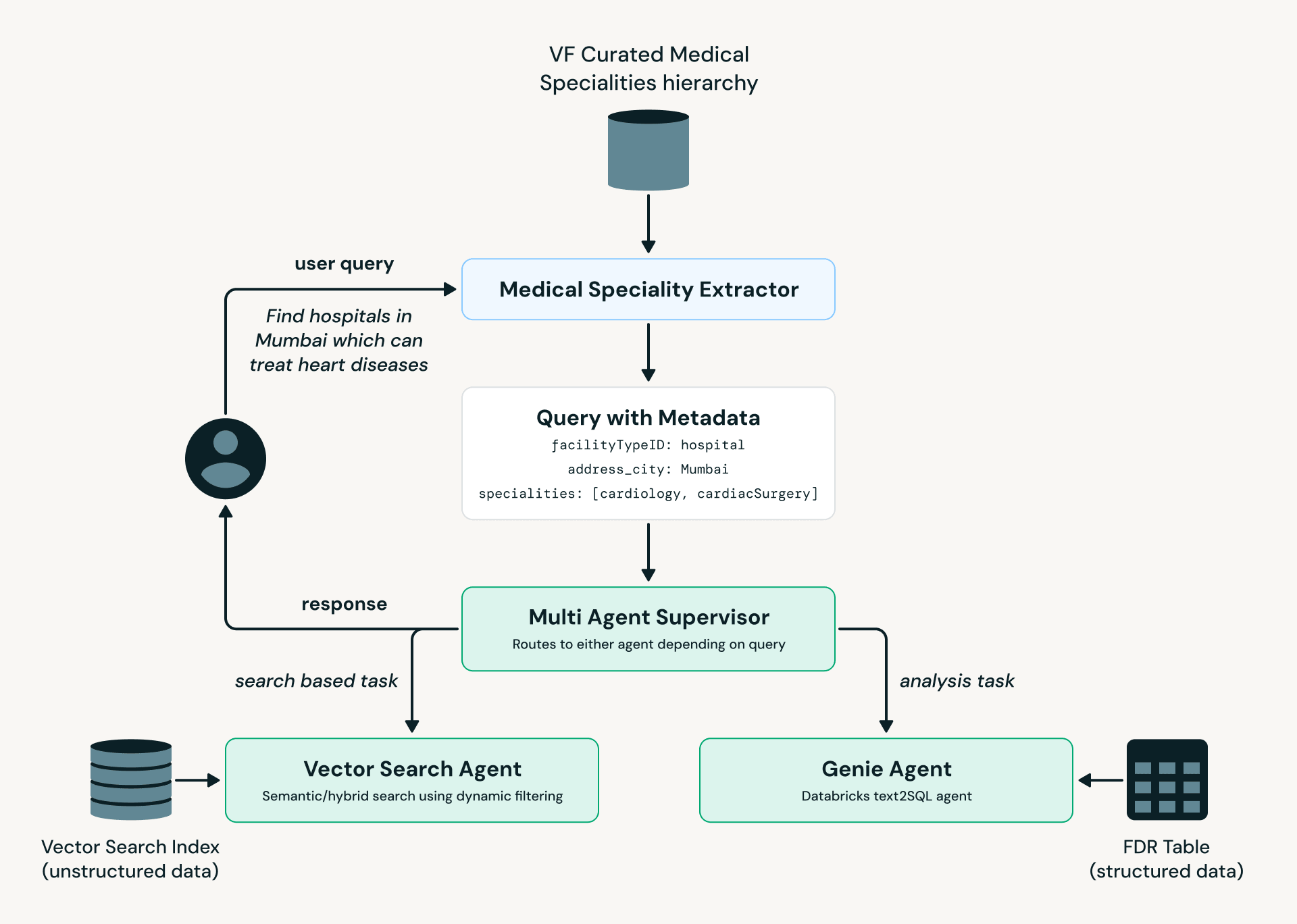
As illustrated within the diagram above, the Medical Specialty Extractor converts consumer language into standardized medical terminology, which is then handed to the Multi-Agent Supervisor. Primarily based on the question’s intent and complexity, it’s routed to both the Vector Search Agent (facility discovery and search) or the Genie Agent (analytical queries in opposition to structured knowledge).
Abstract
Healthcare professionals can now uncover up-to-date alternatives quicker, discover matches to their medical specialties, and entry world knowledge on 1000’s of amenities worldwide. The Advantage Basis’s journey from proof of idea to manufacturing demonstrates what’s doable when superior AI techniques are paired with a unified knowledge platform.
The ultimate result’s a world view of healthcare infrastructure – surfacing the place medical volunteers are wanted most.
If you want to be taught extra about this challenge please see:
– Databricks x Advantage Basis Challenge Overview – YouTube
– UN Bloomberg Interview (YouTube) – round minute 38:00
– Video testimonial: Vibrant Initiative x Advantage Basis x Databricks
Please learn extra about a few of our different Databricks for Good initiatives under: