Delivering Actual-Time Personalization at Scale
Each millisecond counts when vacationers seek for inns, flights, or experiences. As India’s largest on-line journey company, MakeMyTrip competes on real-time pace and relevance. Considered one of its most essential options is “last-searched” inns: as customers faucet the search bar, they count on a real-time, customized checklist of their current pursuits, primarily based on their interplay with the system.
At MakeMyTrip’s scale, delivering that have requires sub-second latency on a manufacturing pipeline serving hundreds of thousands of day by day customers — throughout each shopper and company journey strains of enterprise. By implementing Databricks’ Actual-Time Mode (RTM)—the next-generation execution engine in Apache Spark™ Structured Streaming, MakeMyTrip efficiently achieved millisecond-level latencies, whereas sustaining a cheap infrastructure and decreasing engineering complexity.
The Problem: Extremely-Low Latency With out Architectural Fragmentation
MakeMyTrip’s knowledge crew wanted sub-second latency for the “last-searched” inns workflow throughout all strains of enterprise. At their scale, even just a few hundred milliseconds of delay creates friction within the consumer journey, immediately impacting click-through charges.
Apache Spark’s micro-batch mode launched inherent latency limits that the crew couldn’t break regardless of intensive tuning — constantly delivering latency of 1 to 2 seconds, far too gradual for his or her necessities.
Subsequent, they evaluated Apache Flink throughout roughly 10 streaming pipelines which solved their latency necessities. Nevertheless, adopting Apache Flink as a second engine would have launched vital long-term challenges:
- Architectural fragmentation: Sustaining separate engines for real-time and batch processing
- Duplicated enterprise logic: Enterprise guidelines would must be applied and maintained throughout two codebases
- Larger operational overhead: Doubling monitoring, debugging, and governance effort throughout a number of pipelines
- Consistency dangers: Outcomes threat divergence between batch and real-time processing
- Infrastructure prices: Working and tuning two engines will increase compute spend and upkeep burden
Why Actual-Time Mode: Millisecond Latency on a Single Spark Stack
As a result of MakeMyTrip by no means needed a dual-engine structure, Apache Flink was not a viable long-term choice. The crew made a deliberate architectural determination: to attend for Apache Spark to develop into quicker, moderately than fragment the stack.
Subsequently, when Apache Spark Structured Streaming launched RTM, MakeMyTrip grew to become the primary buyer to undertake it. RTM allowed them to realize millisecond-level latency on Apache Spark — assembly real-time necessities with out introducing one other engine or splitting the platform.
Sustaining two engines means doubling the complexity and the danger of logic drift between batch and real-time calculations. We needed one supply of fact — one Spark-based pipeline — moderately than two engines to keep up. Actual-Time Mode gave us the efficiency we would have liked with the simplicity we needed.” — Aditya Kumar, Affiliate Director of Engineering, MakeMyTrip
RTM delivers steady, low-latency processing by three key technical improvements that work collectively to eradicate the latency sources inherent in micro-batch execution:
- Steady knowledge move: Information is processed because it arrives as an alternative of being discretized into periodic chunks.
- Pipeline scheduling: Levels run concurrently with out blocking, permitting downstream duties to course of knowledge instantly with out ready for upstream levels to complete.
- Streaming shuffle: Information is handed between duties instantly, bypassing the latency bottlenecks of conventional disk-based shuffles.
Collectively, these improvements permit Apache Spark to realize millisecond-scale pipelines that have been beforehand solely potential with specialised engines. To be taught extra in regards to the technical basis of RTM, learn this weblog, “Breaking the Microbatch Barrier: The Structure of Apache Spark Actual-Time Mode.”
The Structure: A Unified Actual-Time Pipeline
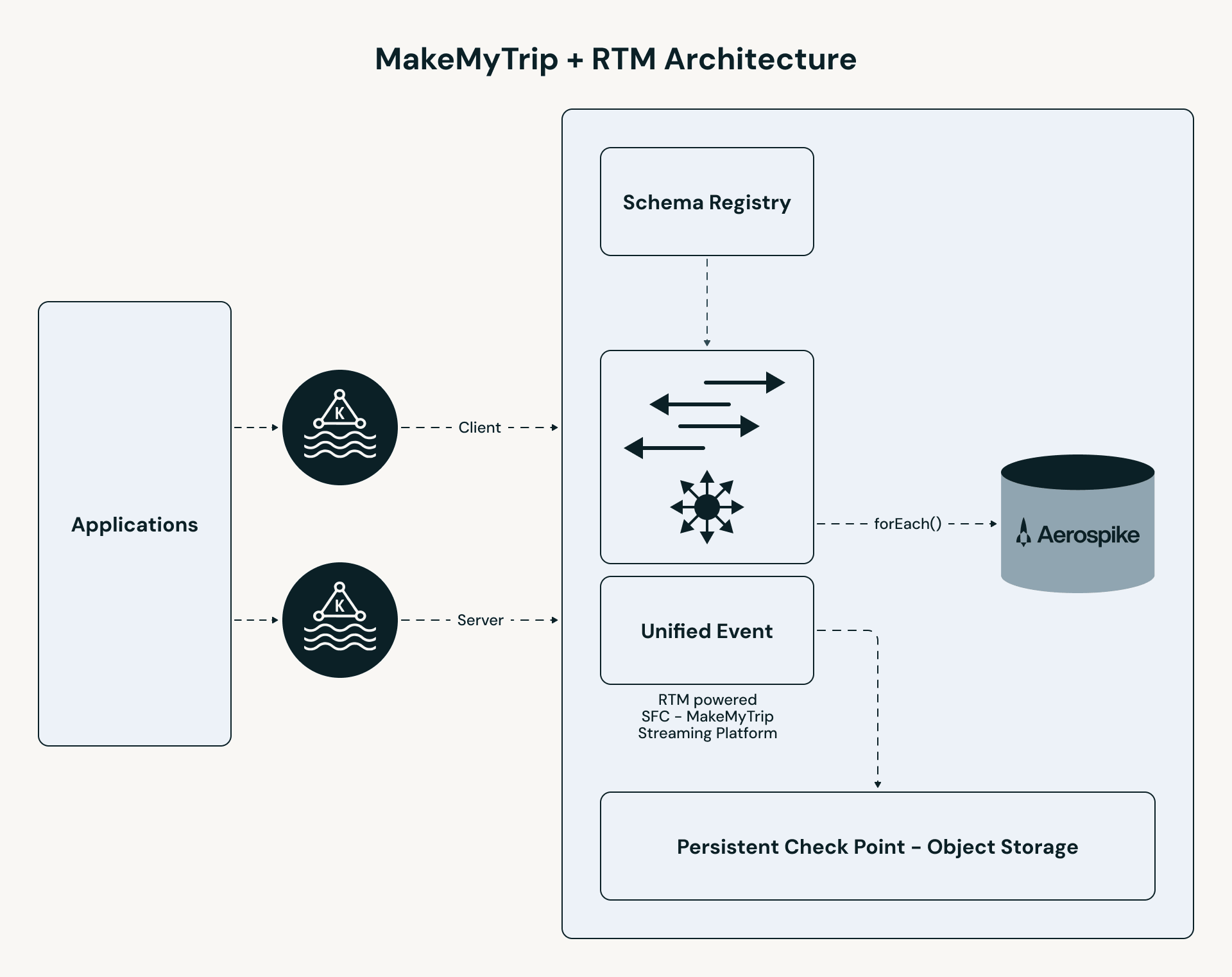
MakeMyTrip’s pipeline follows a high-performance path:
- Unified ingestion: B2C and B2B clickstream subjects are merged right into a single stream. All personalization logic — enrichment, stateful lookup, and occasion processing — is utilized constantly throughout each consumer segments.
- RTM processing: The Apache Spark engine makes use of concurrent scheduling and streaming shuffle to course of occasions in milliseconds.
- Stateful enrichment: The pipeline performs a low-latency lookup in Aerospike to retrieve the “Final N” inns for every consumer.
- Prompt serving: Outcomes are pushed to a UI cache (Redis), enabling the app to serve customized ends in underneath 50ms.
Configuring RTM: a single-line code change
Utilizing RTM in your streaming question doesn’t require rewriting enterprise logic or restructuring pipelines. The one code change wanted is setting the set off sort to RealTimeTrigger, as proven within the following code snippet:
The one infrastructure consideration: cluster job slots should be larger than or equal to the overall variety of lively duties throughout supply and shuffle levels. MakeMyTrip’s crew analyzed their Kafka partitions, shuffle partitions, and pipeline complexity upfront to make sure enough concurrency earlier than going to manufacturing.
Co-Creating RTM for Manufacturing
As RTM’s first adopter, MakeMyTrip labored immediately with Databricks engineering to deliver the pipeline to manufacturing readiness. A number of capabilities required lively collaboration between the 2 groups to construct, tune, and validate.
- Stream Union: Merging B2C and B2B right into a Single Pipeline
MakeMyTrip wanted to unify two separate Kafka matter streams — B2C shopper clickstream and B2B company journey — right into a single RTM pipeline in order that the identical personalization logic could possibly be utilized constantly throughout each consumer segments. After a month of shut collaboration with Databricks engineering, the function was constructed and shipped. The end result was a single pipeline the place all enterprise logic lives in a single place, with no divergence threat between consumer segments. - Job Multiplexing: Extra Partitions, Fewer Cores
RTM’s default mannequin assigns one slot/core per Kafka partition. With 64 partitions in MakeMyTrip’s manufacturing setup, that interprets to 64 slots/cores — cost-prohibitive at their scale. To deal with this, the Databricks crew launched the MaxPartitions choice for Kafka, which permits a number of partitions to be dealt with by a single core. This gave MakeMyTrip the lever they wanted to scale back infra prices with out compromising throughput. - Pipeline Hardening: Checkpointing, Backpressure, and Fault Tolerance
The crew labored by a set of operational challenges particular to high-throughput, low-latency workloads: tuning checkpoint frequency and retention, dealing with timeouts, and managing backpressure throughout surges in clickstream quantity. By scaling to 64 Kafka partitions, enabling backpressure, and capping the MaxRatePerPartition at 500 occasions, the crew optimized throughput and stability. Via this iterative tuning of batch configurations, partitioning, and retry habits, they arrived at a secure, production-grade pipeline serving hundreds of thousands of customers day by day.
Outcomes
RTM enabled prompt personalization and improved responsiveness, greater engagement measured by way of click-through charges and operational simplicity of a single unified engine. Key metrics are proven under.
Apache Spark as a Actual-Time Engine
MakeMyTrip’s deployment proves that RTM on Spark delivers the extraordinarily low latency that your real-time purposes require. As a result of RTM is constructed on the identical acquainted Spark APIs, you need to use the identical enterprise logic throughout batch and actual time pipelines. You not want the overhead of sustaining a second platform or separate codebase for actual time processing, and might merely allow RTM on Spark with a single line of code.
Actual-Time Mode allowed us to compress our infrastructure and ship real-time experiences with out managing a number of streaming engines. As we transfer into the period of AI brokers, steering them successfully requires constructing real-time context from knowledge streams. We’re experimenting with Spark RTM to provide our brokers with the richest, most up-to-date context essential to take the very best choices.” — Aditya Kumar, Affiliate Director of Engineering, MakeMyTrip
Getting began with Actual-Time Mode
To be taught extra about Actual-Time Mode, watch this on-demand video on the way to get began or evaluate the documentation.