Multimodal AI has grown from novelty to a should in latest instances. Want proof? If I had been to inform you to work on an AI mannequin that solely understands textual content, you’ll in all probability chuckle and throw 10 mannequin names at me that may work throughout codecs – be it textual content, audio, or visuals. The brand new race, thus, for the bigwigs, is to not make simply one other AI mannequin, however a system that may perceive the world extra like people do. That is naturally completed by means of language, visuals, sound, and movement collectively. That’s the house Alibaba’s new Qwen3.5-Omni enters.
The most recent mannequin in Alibaba’s Qwen household is positioned as a “totally omni-modal LLM”. We will discover what which means in idea, and what this moniker guarantees within the practicality of issues. One factor is for certain (with Qwen and different launches just like the latest Gemini 3.1 Flash Dwell), AI fashions have gotten much less like separate instruments and extra like unified interactive techniques.
For now, we deal with the Qwen3.5-Omni and all that it brings ot the desk.
What’s Qwen3.5-Omni?
As I discussed earlier, this one is a totally omni-modal mannequin beneath the Qwen household. In easy phrases, it’s constructed to deal with textual content, photos, audio, and audio-visual content material inside a single system. That’s what separates it from older AI setups, the place every modality typically wanted a unique mannequin or pipeline.
As is obvious from its launch temporary, Alibaba is pitching Qwen3.5-Omni as a mannequin designed for richer, extra pure interplay with real-world inputs. As an alternative of treating voice, photos, and video as non-obligatory add-ons, it presents them as core components of the mannequin itself. Which means Qwen3.5-Omni is far more than a regular chatbot. It’s a multimodal AI system meant to interpret totally different varieties of data collectively.
As for its variants, the brand new Qwen3.5-Omni collection consists of Instruct variants in three sizes – Plus, Flash, and Mild. This household construction makes it ideally suited for various use circumstances and efficiency wants. The launch additionally highlights long-context assist, which suggests the mannequin will not be solely broad in modality but in addition constructed for heavier, extra sustained inputs.
There are, in fact, extra such options in line. Right here is all that the brand new Qwen3.5-Omni brings to the desk.

Qwen3.5-Omni Options
Qwen3.5-Omni is clearly a extra succesful step up from Qwen3-Omni. Although the factor to notice right here is that it comes with a lot broader horizons as effectively. Right here is how:
1. Stronger multilingual capabilities
In contrast with Qwen3-Omni, Qwen3.5-Omni comes with considerably improved multilingual capabilities, together with speech recognition in 113 languages.
2. Lengthy-context assist
The Qwen3.5-Omni collection consists of Instruct variations with assist for 256K long-context enter. This factors to a mannequin that’s designed for a lot bigger and extra sustained prompts than a regular chatbot workflow.
3. A number of mannequin sizes
The collection consists of three Instruct sizes: Plus, Flash, and Mild. That offers Qwen3.5-Omni a extra versatile product household slightly than a single one-size-fits-all launch.
4. Massive multimodal enter capability
The announcement weblog says the mannequin can deal with greater than 10 hours of audio enter and over 400 seconds of 720p audio-visual enter at 1 FPS. That signifies that it’s constructed for heavier audio and video understanding workloads.
5. Semantic interruption assist
Qwen3.5-Omni helps semantic interruption by means of “native turn-taking intent recognition.” In easy phrases, this helps the mannequin distinguish between significant person interruption and irrelevant background noise. All in all, the characteristic makes stay conversations really feel extra pure.
6. Native WebSearch and Perform Calling
The mannequin natively helps WebSearch and sophisticated FunctionCall capabilities. This permits it to determine by itself whether or not it ought to invoke WebSearch with the intention to reply a person’s real-time query. Assume extra agent-like sensible use.
7. Finish-to-end voice management and dialogue
This can be a very attention-grabbing improve with Qwen3.5-Omni, and I’m certain you’ll find it irresistible too when you see its demos. The brand new Qwen mannequin helps end-to-end voice management and dialogue. This implies the mannequin can observe spoken directions in a extra human-like approach by controlling features of speech similar to quantity, velocity, and emotion. As demonstrated in some movies, the mannequin can whisper, shout, and even specific feelings in a approach that may sound very pure to most.
8. Voice cloning
One other notable characteristic is voice cloning, which permits customers to add a voice and customise the AI assistant’s output voice accordingly. It means now you can converse to the AI and have it reply within the voice of your alternative.
With all these options, right here is how the Qwen3.5-Omni performs in benchmark assessments.
Qwen3.5-Omni: Benchmark Efficiency
Moderately than profitable each single benchmark outright, Qwen3.5-Omni-Plus comes throughout as a really well-rounded omni-modal mannequin that stays extremely aggressive throughout textual content, imaginative and prescient, audio, audio-visual understanding, and speech era. That’s the greater takeaway right here: consistency throughout nearly each format. And as an add-on, it both leads or comes extraordinarily shut typically instances to the highest mannequin within the comparability.
1. Audio: USP of the mannequin
Audio is clearly considered one of Qwen3.5-Omni-Plus’s strongest areas.
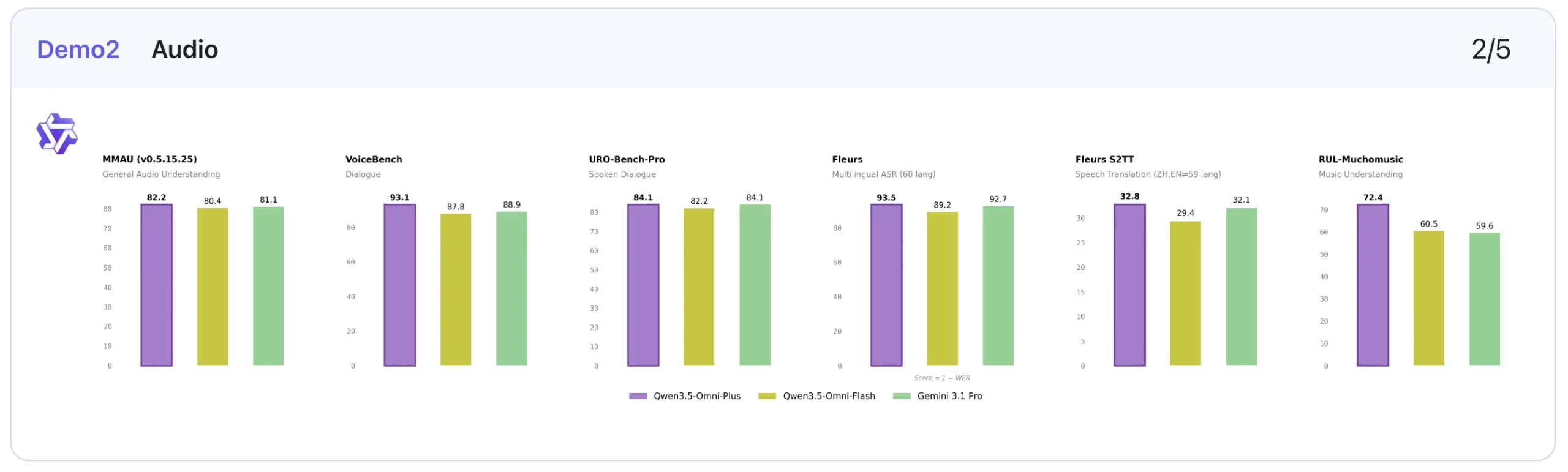
In audio understanding, it barely edges out Gemini-3.1-Professional on MMAU (82.2 vs 81.1) and MMSU (82.8 vs 81.3), whereas additionally delivering an enormous soar on RUL-MuchoMusic (72.4 vs 59.6). On dialogue-heavy duties, it posts the most effective rating on VoiceBench (93.1), forward of Gemini-3.1-Professional’s 88.9.
Its speech-related efficiency can also be spectacular in transcription and recognition-style duties. For instance, on LibriSpeech, Qwen3.5-Omni-Plus scores 1.11 / 2.23, forward of Gemini-3.1-Professional’s 3.36 / 4.41, and on CV15 (en) it information 4.83 in opposition to Gemini’s 8.73. That implies Qwen is especially robust not simply at listening to audio, however at processing it precisely.
2. Audio-Visible: Robust, however not all the time the outright chief
On audio-visual duties, Qwen3.5-Omni-Plus performs strongly, although that is one space the place Gemini-3.1-Professional nonetheless holds some benefits.
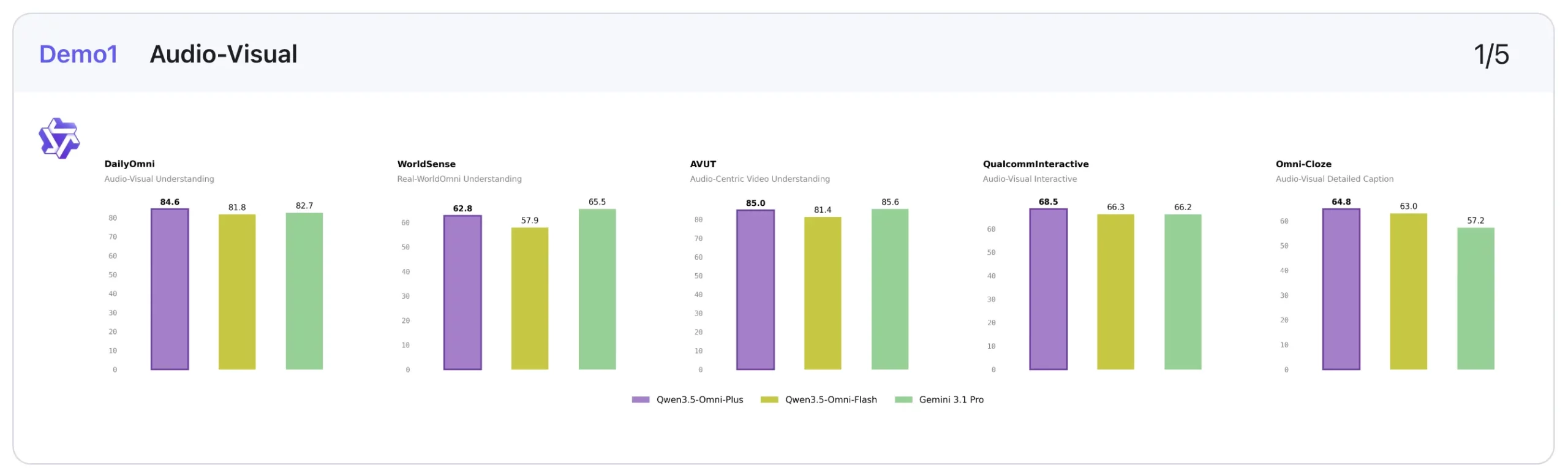
For example, Qwen leads on DailyOmni (84.6 vs 82.7) and QualcommInteractive (68.5 vs 66.2), and likewise tops Omni-Cloze (64.8 vs 57.2) in captioning. However Gemini stays forward on benchmarks like WorldSense (65.5 vs 62.8), VideoMME with audio (89.0 vs 83.7), and OmniGAIA instrument use (68.9 vs 57.2).
3. Visible: Aggressive, with some category-leading scores
In visible duties, Qwen3.5-Omni-Plus once more appears to be like balanced and succesful slightly than wildly dominant.
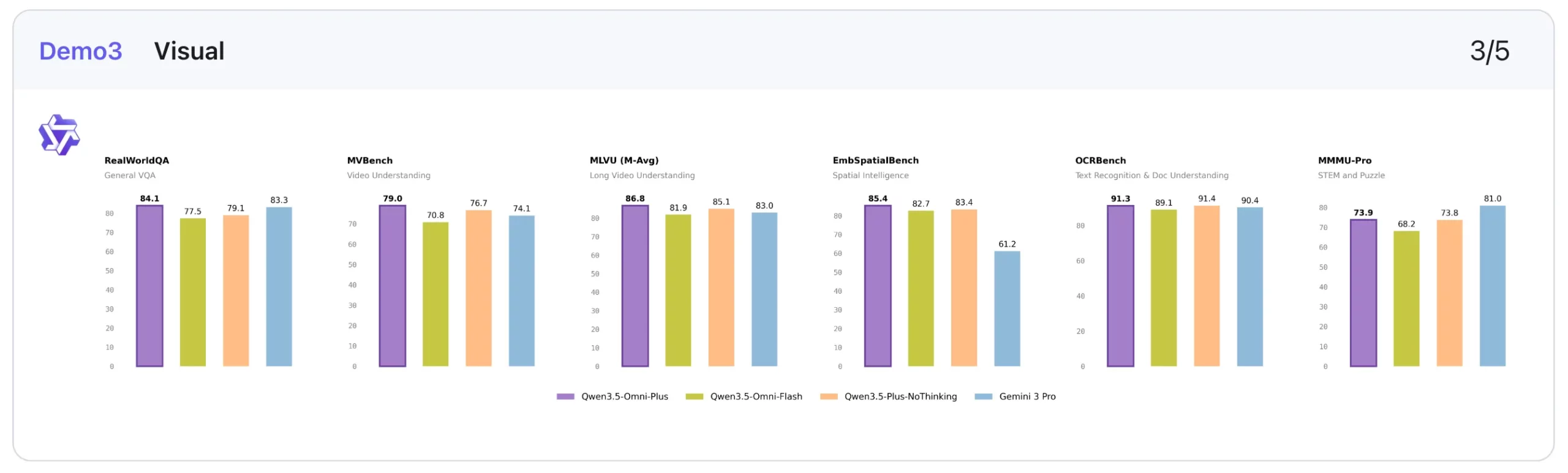
It posts the most effective rating on MMMU-Professional (73.9), edges forward on RealWorldQA (84.1), leads on CC-OCR (83.4), tops EmbSpatialBench (85.4), and performs finest on a number of video benchmarks, together with VideoMME with out subtitles (81.9), MLVU (86.8), MVBench (79.0), LVBench (71.2), and MME-VideoOCR (77.0).
That mentioned, the non-thinking Qwen3.5-Plus baseline nonetheless beats it on some basic visible and reasoning-heavy benchmarks similar to MMMU, MathVision, and Mathvista mini. So Qwen3.5-Omni-Plus will not be the very best visible mannequin in isolation. Although it nonetheless demonstrates very strong visible efficiency whereas bringing audio and speech into the identical system.
4. Textual content: Strong, however not the headline story
Qwen3.5-Omni-Plus reveals a superb textual content efficiency, although it doesn’t seem like the central headline of the discharge.
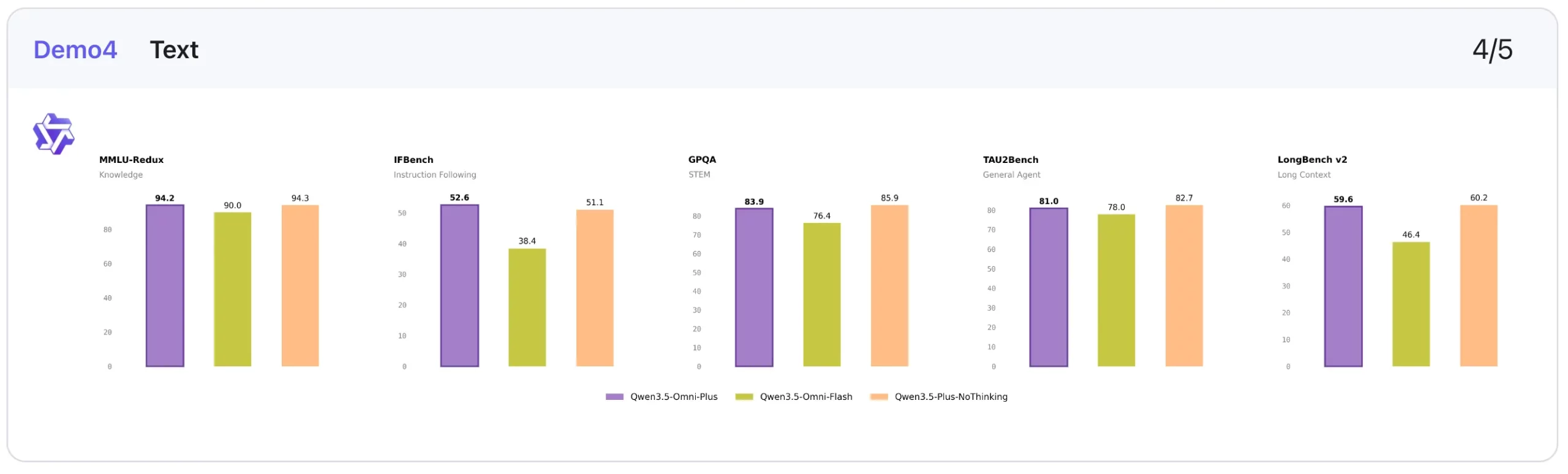
Qwen3.5-Omni-Plus stays near the non-thinking Qwen3.5-Plus mannequin on a number of benchmarks: MMLU-Redux (94.2 vs 94.3), C-Eval (92.0 vs 92.3), and IFEval (89.7 vs 89.7). It additionally does moderately effectively on long-context duties like LongBench v2 (59.6) and reasoning duties like HMMT Nov 25 (84.4).
The broader sample is that Qwen3.5-Omni-Plus preserves a powerful textual content basis whereas extending into different modalities. In fact, it’s not essentially the most thrilling a part of the benchmark desk. However it’s reassuring that the multimodal enlargement does minimize down on text-quality.
5. Speech Technology: Standout benchmark outcomes
This is among the clearest strengths of the mannequin.
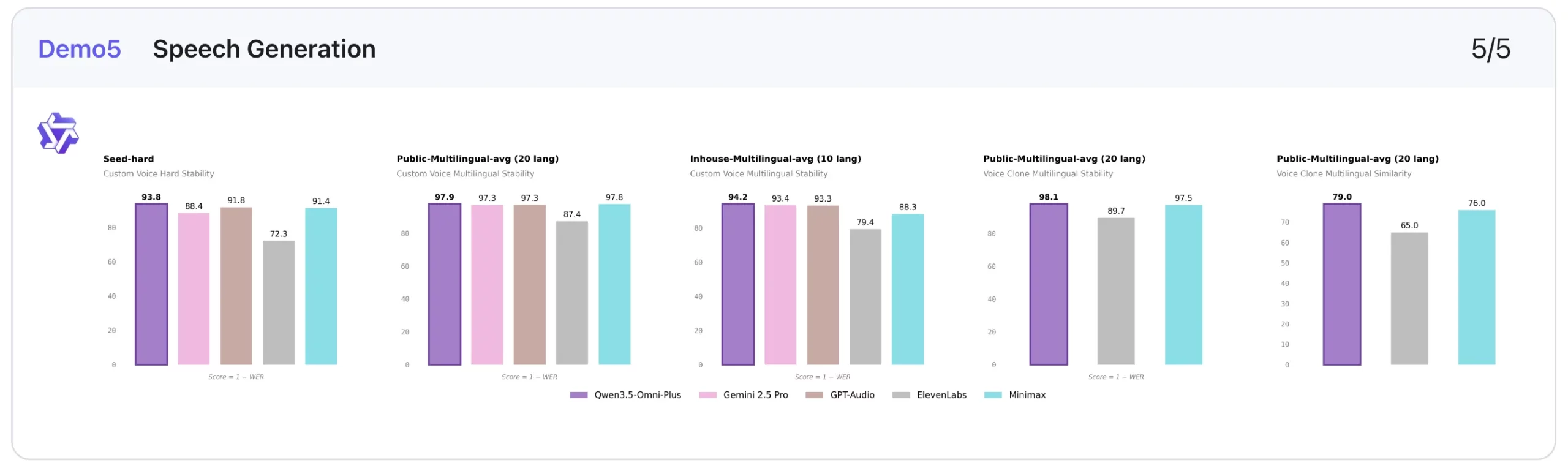
In customized voice stability, decrease is healthier, and Qwen3.5-Omni-Plus performs extraordinarily effectively. It scores 1.07 on Seed-zh, beating ElevenLabs (13.08), Gemini-2.5 Professional (2.42), GPT-Audio (1.11), and Minimax (1.19). It additionally leads on Seed-hard (6.24) and performs finest on the multilingual averages proven, together with 2.06 on Public-Multilingual-avg (20 languages) and 5.82 on Inhouse-Multilingual-avg (9 languages).
On voice clone stability, it additionally posts the most effective multilingual rating within the public setting at 1.87, forward of ElevenLabs (10.29) and Minimax (2.52). On voice clone similarity, increased is healthier, and Qwen3.5-Omni-Plus reaches 0.79 and 0.80, which is once more the strongest rating within the comparability proven.
This makes speech era one of the crucial compelling components of the Qwen3.5-Omni-Plus benchmark story.
Total takeaway
- Strongest: Audio, Speech era
- Very robust: Audio-visual, Imaginative and prescient
- Strong/above common: Textual content
This efficiency is made potential due to the distinctive structure of the Qwen mannequin. Right here is
Qwen3.5-Omni Structure
Qwen3.5-Omni follows what Qwen calls a Thinker-Talker structure. We’ve got seen it earlier than within the earlier Qwen fashions. As an alternative of treating understanding and response era as one blended course of, the mannequin separates them into two purposeful components. That makes the structure simpler to grasp, particularly for a mannequin constructed to deal with a number of modalities.
Here’s what each components do:
1. The Thinker
The Thinker is liable for the mannequin’s understanding layer. In accordance with Qwen, it receives visible and audio alerts by means of the mannequin’s encoders and handles the higher-level reasoning over these inputs.
In easy phrases, that is the a part of the system that interprets what the mannequin is seeing, listening to, or studying earlier than a response is generated.
2. The Talker
The Talker handles the output facet of the system. As soon as the mannequin has processed the enter, this element is liable for producing the response.
This distinction issues as a result of Qwen3.5-Omni is not only meant to analyse inputs. It’s also meant to reply to interactive and conversational use circumstances.
3. Hybrid-Consideration MoE in Each Parts
Qwen says that each the Thinker and the Talker undertake Hybrid-Consideration MoE.
That element suggests the structure is designed to stability functionality and effectivity. As an alternative of counting on one massive block to handle the whole lot, the mannequin makes use of a extra structured design to assist each multimodal understanding and response era.
Why This Structure Issues
For an omni-modal mannequin, structure issues greater than traditional. Qwen3.5-Omni is anticipated to course of textual content, photos, audio, and audio-visual content material inside one system. A cut up between understanding and era helps assist that broader function.
That is additionally why, slightly than trying like a textual content mannequin with a couple of added multimodal options, Qwen3.5-Omni is being framed as a system designed from the bottom up for richer interplay throughout totally different enter and output modes.
Now that we all know the way it works, right here is methods to entry the brand new Qwen mannequin.
Qwen3.5-Omni: Learn how to Entry
There are 3 major methods to entry the Qwen3.5-Omni, principally based mostly in your use case. These are:
1. Qwen Chat
Probably the most simple solution to attempt Qwen3.5-Omni is thru Qwen Chat, which acts because the direct user-facing entry level for the mannequin household.
Finest for: particular person customers
2. through Offline API in Alibaba Cloud Mannequin Studio
For normal API-based integration, Alibaba Cloud gives Qwen-Omni by means of Mannequin Studio. The mannequin accepts textual content mixed with one different modality right here, similar to picture, audio, or video, and might generate responses in textual content or speech. Alibaba notes that Qwen-Omni at present helps OpenAI-compatible calls solely, requires an API key, and works with the newest SDK.
Finest for: app integration and multimodal era workflows
3. through Realtime API for stay audio and video interactions
For interactive purposes, Alibaba Cloud additionally gives Qwen-Omni-Realtime, which is accessed by means of a stateful WebSocket connection. This route is supposed for real-time audio and video chat use circumstances, the place the mannequin can course of streaming inputs and generate responses constantly throughout a session.
Finest for: voice- or video-driven stay experiences
Qwen3.5-Omni: Demonstration
The Qwen crew has shared a number of demos of the brand new Qwen3.5-Omni that showcase its capabilities throughout use circumstances. Test them out under:
1. Audio-Visible Captioning
The primary demo for the mannequin is that of audio-visual captioning. The demo reveals how the mannequin is ready to precisely interpret the knowledge being shared inside a video and generate the textual content for a similar. Test it out in motion within the embed under.
2. Audio-Visible Vibe Coding
This one is tremendous attention-grabbing, because it reveals Qwen3.5-Omni decoding particular technical directions shared inside a video, after which appearing accordingly. As may be seen, the mannequin can clearly perceive what is going on throughout visible and audio inputs and help in producing or refining code accordingly. That is combining multimodal context into the coding loop, making the interplay really feel extra intuitive than a plain text-only workflow.
3. Multi-Flip Dialogue and Clever Interruption
Alibaba additionally shares proof for its claims of multi-turn dialogue capabilities on the Qwen3.5-Omni. In one other video, the mannequin may be seen dealing with interruptions tremendous intelligently. It showcases that the Qwen3.5-Omni can casually maintain a back-and-forth dialog whereas additionally recognising when a person is meaningfully interrupting, as an alternative of reacting awkwardly to each sound or pause.
The anchor may be clearly seen making an attempt to idiot the mannequin with filler phrases like “hmmm” and “okay” in the midst of the mannequin’s response. Although Qwen3.5-Omni appears to know higher than to interrupt.
4. Voice Model, Emotion, and Quantity Management
Should you had been to ask me, this appears to be the USP of the brand new Qwen mannequin. We’ve got all seen AI fashions conversate with us in a really related (if not precise) tone as people. The Qwen3.5-Omni now takes it a step additional and brings in voice type, emotion, and quantity management. The demo highlights how the mannequin can whisper, shout, and even narrate a poem whereas feeling dejected. That’s one thing you don’t see too typically.
Conclusion
From what we will see within the demos and the knowledge shared by Alibaba, the brand new Qwen3.5-Omni takes the multi-modal capabilities of an LLM to a different degree. From deciphering audio-visual directions to creating AI conversations really feel far more human, it brings with it a set of options which are not often seen in AI fashions.
I’m certain many would love to modify to Qwen3.5-Omni after this, largely for your complete conversations taking place in audio-visual inputs and outputs. Whether or not they ship on the standard that’s showcased right here, stays to be seen.
Login to proceed studying and luxuriate in expert-curated content material.